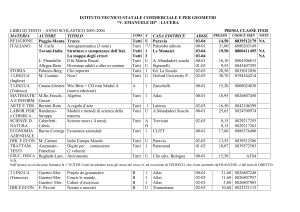
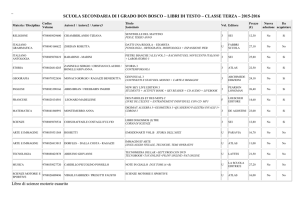
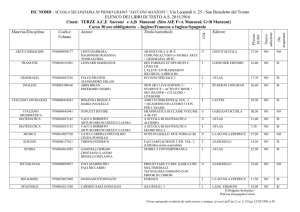
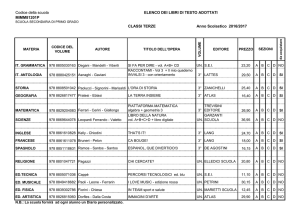
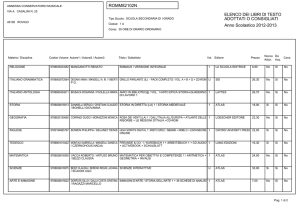
ATLAS Distributed Computing
e Data Management
Alessandro De Salvo [email protected]
19-5-2011
Outline
Stato attuale
Evoluzione del modello di calcolo
Nuove tecnologie e roadmap
A. De Salvo – 19 Maggio 2011
ATLAS Panda
Modello di base: I dati sono pre-distribuiti nei siti, I job sono inviati ai siti che
posseggono i dati
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
ATLAS DDM model
I file sono aggregati in datasets
Subscription service
I files sono trasferiti solo come
parte di un dataset
Uno o più dataset può essere
sottoscritto per triggerare
una replica ad un sito
specifico di destinazione
I metadati di fisica sono
contenuti in un DB separato
(AMI)
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
ATLAS Cloud Model
•
•
•
Modello gerarchico basato
sulla topologia di rete di
Monarc
Comunicazioni possibili:
• T0-T1
• T1-T1
• Intra-cloud T1-T2
Comunicazioni vietate:
• Inter-cloud T1-T2
• Inter-cloud T2-T2
Limitazioni:
• Impossibile fornire una replica di dati
per l’analisi ad ogni cloud
• Trasferimenti tra le cloud attraverso
salti multipli tra i Tier1
• User analysis outputs
• MC confinato nella cloud
• Tier2 non utilizzabili come repository di
dati primari per il PD2P o di gruppo
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
ATLAS Cloud(less) Model
Breaking the Wall
•
La rete attuale permette il
superamento del modello
Monarc:
• molti Tier2 sono già ben
connessi con molti Tier1
• Abilitazione delle
connessioni inter cloud
•
Superamento di una gerarchia
stretta tra Tier1 e Tier2
•
Scelta dei Tier2 adatti
• alcuni Tier2 invece sono
mal collegati anche con il
proprio Tier1
• Non tutti I Tier2 hanno le
dimensioni e le
performance necessarie
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Tier-2 diretti (T2D)
•
•
•
T2D – Tier2 “Directly Connected”
Tier2 connessi direttamente tra di loro a tutti i Tier1
Storage per dati primari come i Tier1
•
Pre-placement di una quota di dati
•
Data source per il PD2P
•
Group data
•
Disponibilità di una quota di disco nei Tier1 come cache
Requirement molto stretti
•
Metriche di trasferimento con tutti i Tier1
•
Livello di committment e reliability adeguato
Avg(Byterate)+StD(Byterate)
SMALL
<0.05MB/s
<0.1MB/s
≥0.1MB/
s
MEDIUM
<1MB/s
<2MB/s
≥2MB/s
LARGE
<10MB/s
<15MB/s
≥15MB/
s
T2D approvati:
INFN-NAPOLI- ATLAS, INFN-MILANO-ATLASC, INFNROMA1
IFIC-LCG2, IFAE, UAM-LCG2
GRIF-LPNHE, GRIF-LAL, TOKYO-LCG2
DESY-HH, DESY-ZN, LRZ-LMU, MPPMU
MWT2_UC,WT2, AGLT2,BU_ATLAS_Tier2, SWT2_CPB
UKI-LT2-QMUL, UKI-NORTHGRID-LANCS-HEP, UKI-NORTHGRIDMAN-HEP, UKI-SCOTGRID-GLASGOW
Siti che faranno parte
da subito di LHCOne
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
PanDA Dynamic Data Placement (PD2P) [1]
Il precedente modello di calcolo di ATLAS prevedeva la distribuzione dei
dati in tutti i centri (~75), secondo share predefiniti
Il nuovo modello di calcolo prevede l’invio dei dati su richiesta ai centri
Tier2 (~65) tramite l’utilizzo di un algoritmo di brokering predittivo
Non molto efficiente in termini di tempo e banda utilizzata
Utilizzo dello spazio disco non ottimale
Il primo utilizzo di un dataset che non è disponibile in nessuno dei Tier2 fa partire la replica
verso una locazione ottimale, scelta dal sistema di brokering di PanDA
I job degli utenti continueranno ad essere assegnati ai Tier1 finché una copia dei dati non
sarà disponibile ai Tier2, momento in cui i job verranno ri-schedulati al Tier2 in questione
Se il numero dei job rimamenti (di tutti gli utenti) che richiedono un dataset è troppo elevato
verranno effettuate delle copie addizionali del dataset di input in altrettanti siti
Dal 2011 il sistema di Dynamic Data Placement è stato esteso anche ai
centri Tier1
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
PanDA Dynamic Data Placement (PD2P) [2]
•
•
•
•
•
•
•
•
•
2010
Buoni risultati di ottimizzazione dello spazio disco
Diminuzione delle repliche pre-placed
Trasferimento solo di dati utili per l’analisi
Spazio disco ai Tier2 in gran parte usato come cache
Ristretto ai trasferimenti intra-cloud T1 T2
2011
Cancellazione dei cloud boundaries: trasferimenti intra-cloud
Extra repliche in base al riutilizzo dei dati già trasferiti e al numero di richieste di accesso al singolo
dataset
Trasferimenti anche tra Tier1
Dati trasferiti: AOD e D3PD molto più leggeri degli ESD del 2010 diminuzione della banda occupata
Concern
Il brokering dei dati e dei job di analisi in Panda sembra stia favorendo troppo i Tier1 a scapito dei Tier2.
Il mese di maggio sarà analizzato per verificare la bontà del modello e il tuning necessario.
Prima azione: pre-placement di una frazione di dati nei T2D
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Popolarità dei dati
Data replication on-demand (DaTri)
Possibilità di generare statistiche su
Dataset più utilizzati
Tipi di dati più popolari
Siti utilizzati per l’analisi dati
Group production
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Distribuzione dei dati di ATLAS nel 2010
Reprocessing
dati e MC
AVERAGE:2.3 GB/s
MAX 7.5 GB/s
inizio presa dati
@ 7 TeV
MB/s
per day
Reprocessing
MC
Gennaio
EFFICIENCY:
100%
(including retries)
Reprocessing
dati 2009
Febbraio
Marzo
Aprile
Maggio
2010 pp
reprocessing
Presa dati e produzione
Giugno
Dati disponibili nei siti
dopo poche ore
PbPb
processing
@T1s
MB/s
per day
Luglio
Agosto
Settembre
Ottobre
Novembre
Dicembre
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Distribuzione dei dati di ATLAS nel 2011
MB/s
per day
AVERAGE:2.2 GB/s
MAX 5.1 GB/s
PbPb
reprocessing
inizio presa dati @
7 TeV
Gennaio
Febbraio
Marzo
Aprile
Maggio
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Distribuzione dei dati di ATLAS in Italia nel 2010/2011
AVERAGE:195 MB/s
MAX 900 MB/s
2010
MB/s
per day
400
Marzo
Aprile
TB
Maggio
Giugno
2010
Luglio
Agosto
TB
MB/s
per day
Settembre
Ottobre
Novembre
Dicembre
2011
2011
AVERAGE:111 MB/s
MAX 400 MB/s
400
Gennaio
Febbraio
Marzo
Aprile
Maggio
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Condition data access
I condition data sono contenuti in database (ORACLE) e/o in plain
(ROOT) file, registrati al CERN
I dati sono replicati in alcuni dei Tier1 ed utilizzati dai job di analisi
L’accesso diretto ad ORACLE è una killer application per i DB nei Tier1
• Numero troppo elevato di connessioni ai server di ORACLE
• Load elevato
• Rischio di inefficienze
Per supplire a tale limitazione, l’accesso preferito ai condition
data viene effettuato tramite un caching proxy intermedio
• FroNTier server
• Estensione di uno squid proxy standard, può anche essere utilizzato come uno
squid tradizionale
• Caching e failover
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Condition data access example: ATLAS
FroNTier utilizzato per abilitare
l’accesso distribuito al condition DB
Sempre più trasparente dal punto di
vista degli utenti finali
Stesso modello utilizzato da CMS
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Nuove tecnologie di DB: noSQL database [1]
Gli RDBMS attuali hanno delle limitazioni
Difficoltà a scalare
Necessità di una de-normalizzazione per ottenere una perfomance migliore
Setup/configurazione complicata con apache
Difficoltà con applicazioni grandi, accessi random and I/O intensiva
ATLAS sta esplorando le soluzioni DB di tipo noSQL solutions per eliminare le
limitazioni attuali
‘Facilità a scalare’ – ma architettura differente
‘Fanno il loro lavoro’ su una infrastruttura a basso costo
Stessa affidabilità a livello di applicazione
Google, Facebook, Amazon, Yahoo!
Progetti open source
•
Bigtable, Cassandra, Simpledb, Dynamo, MongoDB, Couchdb, Hypertable, Riak, Hadoop Hbase, ecc.
Attualmente i database di tipo noSQL non sono un rimpiazzo per gli RDBMS standard
Ci sono classi di query complesse che includono range di date e tempi dove gli RDBMS hanno una
performance abbastanza bassa
Ad esempio, registrare molti dati storici su un costoso RDBMS transaction-oriented non sembra ottimale
Una opzione attraente è quella di scaricare una mole significante di dati di archiviazione da un database
ORACLE verso un sistema scalabile ad alte perfomance, basato su hardware a basso costo
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Nuove tecnologie di DB: noSQL database [2]
In fase di valutazione per
ATLAS Panda system
ATLAS Distributed Data Management
…
L’esperienza di ATLAS con il servizio di Accounting di DQ2 Accounting (grandi tabelle) mostra che
un database di tipo noSQL come MongoDB può raggiungere almeno le stesse performance di un
cluster di ORACLE RAC, utilizzando circa il medesimo spazio disco, ma girando su hardware a
basso costo
Oracle
•
•
•
•
•
0.3s per completare le query di test
Oracle RAC (CERN ADCR)
38 GB di spazio disco utilizzato
243 indici, 2 funzioni, 365 partizioni/Y+hints
5 settimane + DBAs per creare la facility
MongoDB
•
•
•
•
•
0.4s per completare le query di test
Singola macchina, 8 Cores/16G
42 GB di spazio disco utilizzato
4 ore per creare la facility
1 tabella, 1 indice
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Nuove tecnologie di accesso dati: XRootd Federations
Utilizzo di un redirector XRoot per creare un punto di accesso unificato
per i siti - “Global Redirector”
Namespace unificato, 1 protocollo, location-neutral
Alte performance, accesso ai dati con basso livello di manutenzione
•
Possibilità di girare job su dati remoti (con o senza cache locale)
XRD: alte prestazione, scalabile, flessibile,
architettura a plugin
•
Principalmente per i Tier3, ma anche carico ridotto per I T1/T2
Supporta dCache, GPFS, Hadoop, ecc come backend di storage
Quale livello di sicurezza è appropriato
per un accesso di tipo readonly
a dati di fisica?
GSI supportato via plugin 'seclib’
•
•
•
•
Stato del supporto a VOMS?
Maggiore overhead per installare/operare
User- o host- based? (service cert?)
Implicazioni sulle prestazioni
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Large Scale Tests: CERN EOS
EOS è un set di plug-in XRootd
E parla il protocollo Xroot verso gli utenti
Just a Bunch Of Disks...
JBOD - no hardware RAID array
“Network RAID” tra gruppi di nodi
Per-directory settings
Le operazioni (e gli utenti) decidono le disponibilità/performance (numero di repliche per directory – non
posizionamento fisico)
Un pool di dischi – differenti classi di servizio
Affidabilità e durabilità
Self-healing
Operazioni “asincrone” (ad esempio rimpiazzo di un disco rotto quando è “conveniente”, mentre il sistema è
in attività)
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Large Scale Tests: CERN EOS architecture
Head node
Head node NS
async
Namespace, Quota
Strong Authentication
Capability Engine
File Placement
File Location
Message Queue
sync
MQ
async
File server
Service State Messages
File Transaction Reports
File Server
File & File Meta Data Store
Capability Authorization
Checksumming & Verification
Disk Error Detection (Scrubbing)
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Large Scale Tests: CERN EOS performance
HammerCloud Test 10004055
http://hammercloud.cern.ch/atlas/10004055/test/
Reference Events/Wallclock time
15-20 Hz
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Large Scale Tests: pNFS (NFS v4.1)
pNFS aggiunge la parallel I/O al protocollo NFS
pNFS fa parte dello standard NFS v4.1
Approvato da IETF Dec, 2008
RFC editorial review Oct, 2009
Numeri di RFC assegnati a gennaio 2010
Multiple implementazioni sono in fase di sviluppo
Elimina il collo di bottiglia del file server
Mette a disposizione del path paralleli di dati, anche per un singolo file
Il client software software sarà incluso in tutte le distribuzioni di OS principali
L’unico Industry-Standard Parallel File System
Testbed con BlueArc a BNL (pianificato per Agosto 2011)
Singolo server di metadati, altamente scalabile
•
•
Clusterizzato per HA
L’architettura supporta molti server di metadati clusterizzati
Supporto per data server eterogenei
Costruito su piattaforma di classe Enterprise
•
•
Affidabilità
Full Featured NAS – Quota, Snapshot ecc.
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Large Scale Tests: testbed di pNFS a BNL
SRM
WA Network
Xrootd
GridFTP
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Nuove tecnologie per la distribuzione del software di esperimento: CVMFS
ATLAS ed LHCb si stanno muovendo verso un modello dinamico di distribuzione del
software tramite CVMFS
Virtual software installation tramite un File System HTTP
Data Store
•
•
Compressed Chunks (Files)
Eliminazione dei Duplicati
File Catalog
•
•
•
•
•
•
Directory Structure
Symlinks
SHA1 dei Regular Files
Digitally Signed
Time to Live
Nested Catalogs
ATLAS distribuirà anche i file di condition data tramite CVMFS
Export dell’area del software degli esperimenti come read-only
Montata nei nodi remoti tramite il modulo fuse
Local cache per accesso più rapido
Beneficia di una gerarchia di squid per garantire performance, scalabilità e affidabilità
•
Stesso tipo di squid utilizzato anche da Frontier
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Network monitoring e link commissioning:
Sonar Tests
Commissioning dei link nei siti di ATLAS (full
mesh)
15 trasferimenti di FTS
•
•
•
5 file piccoli: 20 MB
5 file medi: 200 MB
5 file grandi: 2 GB
I trasferimenti sono
effettuati in modo da
evitare trasferimenti
contemporanei in tutti
I canali
Le metriche in uso
vengono utilizzate per
definire i siti T2D
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011
Conclusioni
Il nuovo computing model di ATLAS prevede delle novità importanti
“Breaking the wall” – cloudless model
Nuovi tipi di Tier2 (T2D)
Dynamic Data Placement (PD2P)
Nuove tecnologie per l’ottimizzazione delle risorse e per rendere i sistemi
sempre più trasparenti, affidabili e performanti agli utenti
Frontier server per l’accesso ai condition data
noSQL database
Nuove tecnologie di storage
Link commissioning tramite i Sonar Tests
A. De Salvo – ATLAS Distributed Computing e Data Management – CCR Workshop, Isola d’Elba 19-5-2011