Metodi Quantitativi per Economia,
Finanza e Management
Lezione n°7
Test d’Ipotesi, Analisi Bivariata: discussione di un lavoro di gruppo
Bivariate Analysis
Objective
To jointly describe the relationship between two variables.
• qualitative variables: Analysis of Connection
• quantitative variables: Analysis of Correlation
• mixed variables: Analysis of Variance
Test per lo studio dell’associazione tra
variabili
• Nella teoria dei test, il ricercatore fornisce ipotesi riguardo la
distribuzione della popolazione; tali Hp sono parametriche se
riguardano il valore di uno ò più parametri della popolazione
conoscendone la distribuzione a meno dei parametri stessi;
non parametriche se prescindono dalla conoscenza della
distribuzione della popolazione.
• Obiettivo dei test: come decidere se accettare o rifiutare
un’ipotesi statistica alla luce di un risultato campionario.
Esistono due ipotesi: H0 e H 1, di cui la prima è l’ipotesi nulla,
la seconda l’ipotesi alternativa la quale rappresenta, di fatto,
l’ipotesi che il ricercatore sta cercando di dimostrare.
Test di Ipotesi
Cosa è un’ipotesi statistica?
• Una affermazione/assunzione circa un
parametro/caratteristica
di una popolazione che si intende
analizzare
Esempio: In questa città, il costo medio della bolletta mensile
per il cellulare è μ = $42
Esempio: In questa città, il costo medio della bolletta mensile
per il cellulare è lo stesso sia per gli uomini che per le donne
Test di Ipotesi
• Si può incorrere in due tipologie di errore:
Possibili Risultati Verifica di Ipotesi
Stato di Natura
Decisione
Non
Rifiutare
H0
Rifiutare
H0
H0 Vera
No errore
Errore
Primo Tipo
H0 Falsa
Errore
Secondo Tipo
No Errore
Test di Ipotesi
• Errore di Primo Tipo
– Rifiutare un’ipotesi nulla vera
– Considerato un tipo di errore molto serio
La probabilità dell’errore di primo tipo è
• Chiamato livello si significatività del test
• Fissato a priori dal ricercatore
Test di Ipotesi
• Errore di Secondo Tipo
– Non rifiutare un’ipotesi nulla falsa
La probabilità dell’errore di secondo tipo è β
Test di Ipotesi
Possibili Risultati Verifica di Ipotesi
Stato di Natura
Legenda:
Risultato
(Probabilità)
Decisione
H0 Vera
Non
Rifiutare
H0
No errore
(1 - )
Rifiutare
H0
Errore
Primo Tipo
()
H0 Falsa
Errore
Secondo Tipo
(β)
No Errore
(1-β)
Test di Ipotesi
Errore di primo tipo ed errore di secondo tipo non si
posso verificare contemporanemente
Errore di primo tipo può occorrere solo se H0 è vera
Errore di secondo tipo può occorrere solo se H0 è falsa
Se la probabilità dell’errore di primo tipo ( )
,
allora la probabilità dell’errore di secondo tipo ( β )
Lettura di un Test di Ipotesi (1)
Esempio:
H0:
b1= b2 = ....=bk = 0
1) Ipotesi
H1: bi = 0
2) Statistica test
3) p-value
Statistica F
Rappresenta la probabilità di commettere
l’errore di primo tipo.
Può essere interpretato come la probabilità
che H0 sia “vera” in base al valore osservato
della statistica test
Lettura di un Test di Ipotesi (2)
Il p-value:
- è la probabilità che H0 sia “vera” in base al valore
osservato della statistica test
- è anche chiamato livello di significatività osservato
- è il più piccolo valore di per il quale H0 può
essere rifiutata
Lettura di un Test di Ipotesi (3)
Regola di Decisione: confrontare il p-value con
Se p-value piccolo ( < α )
RIFIUTO H0
Altrimenti ( >= α )
ACCETTO H0
Test χ² per l’indipendenza statistica
Si considera la distribuzione χ², con un numero di gradi di libertà
pari a (k-1)(h-1), dove k è il numero di righe e h il numero di
colonne della tabella di contingenza. Qui:
• H0 :indipendenza statistica tra X e Y
• H1 : dipendenza statistica tra X e Y
La regione di rifiuto cade nella coda di destra della distribuzione
0.2
0.15
0.1
0.05
La regione di rifiuto è
caratterizzata da valori
relativamente elevati di
χ²; se il livello di
significatività è al 5%,
si rifiuta per χ²> χ²0.95
0
Regione di rifiuto
0 1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 9.9 11
Test χ² per l’indipendenza statistica
Chi-Square Tests
Pears on Chi-Square
Likelihood Ratio
N of Valid Cases
Value
5.471 a
5.402
221
df
3
3
Asymp. Sig.
(2-s ided)
.140
.145
a. 0 cells (.0%) have expected count les s than 5. The
minimum expected count is 15.95.
Chi-Square Tests
Pears on Chi-Square
Likelihood Ratio
N of Valid Cases
Value
26.304a
28.928
221
df
8
8
Asymp. Sig.
(2-s ided)
.001
.000
a. 0 cells (.0%) have expected count les s than 5. The
minimum expected count is 5.47.
Test χ² per l’indipendenza statistica
Esempio
H0: assenza di associazione tra mano dominante e sesso (indipendenza
statistica )
H1: mano dominante non è independente dal sesso (dipendenza statistica )
Mano dominante
Sesso
Sinistra
Destra
Femmina
12
108
120
Maschio
24
156
180
36
264
300
Se non c’è associazione, allora
P(Mancino | Femmina) = P(Mancino | Maschio) =P(Mancino)= 36/300= 0.12
Quindi ci aspetteremmo che Il 12% delle 120 femmine e Il 12% dei 180 maschi
siano mancini…
Test χ² per l’indipendenza statistica
Esempio
• Se H0 è vera, allora la proporzione di donne mancine
dovrebbe coincidere con la proporzione di uomini
mancini
• Le due proporzioni precedenti dovrebbero coincidere
con la proporzione generale di gente mancina
Mano dominante
Sesso
Sinistra
Destra
Femmina
Osservate = 12
Attese = 14.4
Osservate = 108
Attese = 105.6
120
Maschio
Osservate = 24
Attese = 21.6
Osservate = 156
Attese = 158.4
180
36
264
300
E11
(120)(36)
14.4
300
Test χ² per l’indipendenza statistica
Esempio
La statistica test chi-quadrato è:
r
c
2
i1 j1
con
(Oij Eij )2
Regola di Decisione:
Eij
confrontare il p-value con
g.d .l. (r 1)(c 1)
dove:
Oij = frequenza osservate nella cella (i, j)
Eij = frequenza attesa nella cella (i, j)
r = numero di righe
c = numero di colonne
p-value = 0.32 > 0.05,
quindi accettiamo H0 e
concludiamo che sesso e
mano dominante non
sono associate
Test t per l’indipendenza lineare
Questo test verifica l’ipotesi di indipendenza lineare tra due
variabili, partendo dall’indice di correlazione lineare ρ. Si
ha:
• H0: indipendenza lineare tra X e Y (ρpopolaz=0)
• H1: dipendenza lineare tra X e Y (ρpopolaz ≠ 0)
La statistica test è distribuita come una t di Student con n-2
gradi di libertà, e tende a crescere all’aumentare
dell’ampiezza campionaria
t= ρ √(n-2)/ (1- ρ²)
Test t per l’indipendenza lineare
La regione di rifiuto è caratterizzata da valori relativamente
elevati di t in modulo; se il livello di significatività è al
5%, si rifiuta per |t| >t0,975
0,35
0,3
0,25
0,2
0,15
0,1
0,05
0
Regione di rifiuto
Regione di rifiuto
Test t per l’indipendenza lineare
Correlations
Qualità degli ingredienti
Genuinità
Leggerezza
Sapore/gusto
Pears on Correlation
Sig. (2-tailed)
N
Pears on Correlation
Sig. (2-tailed)
N
Pears on Correlation
Sig. (2-tailed)
N
Pears on Correlation
Sig. (2-tailed)
N
Qualità degli
ingredienti
1
**. Correlation is s ignificant at the 0.01 level (2-tailed).
Genuinità Leggerezza Sapore/gusto
.629**
.299**
.232**
.000
.000
.001
220
220
218
220
.629**
1
.468**
.090
.000
.000
.181
220
220
218
220
.299**
.468**
1
.030
.000
.000
.657
218
218
219
219
.232**
.090
.030
1
.001
.181
.657
220
220
219
221
Test F per la verifica di ipotesi sulla
differenza tra medie
Si prende in considerazione la scomposizione della varianza; qui
• H0: le medie sono tutte uguali tra loro
• H1: esistono almeno due medie diverse tra loro
La statistica test da utilizzare, sotto l’ipotesi H0, si distribuisce
come una F di Fisher con (c-1,n-1) gradi di libertà. Tende a
crescere all’aumentare della varianza tra medie e al diminuire
della variabilità interna alle categorie. Cresce inoltre
all’aumentare dell’ampiezza campionaria.
Test F per la verifica di ipotesi sulla
differenza tra medie
La regione di rifiuto cade nella coda di destra della distribuzione,
cioè è caratterizzata da valori relativamente elevati di F; se il
livello di significatività è 5%, si rifiuta per F> F0,95
0.8
0.7
0.6
0.5
0.4
0.3
0.2
Regione di rifiuto
0.1
0
0
0.7
1.4
2.1
2.8
3.5
4.2
4.9
Test F per la verifica di ipotesi sulla
differenza tra medie
Report
Measures of Association
Produzione artigianale
Età
18-25
26-35
36-50
Over 50
Total
Mean
5.01
5.53
6.00
6.09
5.55
Eta
N
78
55
41
47
221
Std. Deviation
2.224
2.609
2.098
2.320
2.352
Produzione
artigianale * Età
Eta Squared
.191
.036
ANOVA Table
Produzione
artigianale * Età
Between Groups
Within Groups
Total
(Combined)
Sum of
Squares
44.296
1172.356
1216.652
df
3
217
220
Mean Square
14.765
5.403
F
2.733
Sig.
.045
Produzione artigianale
Età
18-25
26-35
36-50
Over 50
Total
Mean
5.01
5.53
6.00
6.09
5.55
N
78
55
41
47
221
Std. Deviation
2.224
2.609
2.098
2.320
2.352
ANOVA Table
Produzione
artigianale * Età
Between Groups
Within Groups
Total
(Combined)
Sum of
Squares
44.296
1172.356
1216.652
df
3
217
220
Mean Square
14.765
5.403
F
2.733
Sig.
.045
Report
Attenzione a bis ogni s pecifici
Età
18-25
26-35
36-50
Over 50
Total
Mean
4.05
4.53
5.00
5.83
4.73
N
78
53
41
47
219
Std. Deviation
2.772
2.791
2.837
8.168
4.536
ANOVA Table
Attenzione a bisogni
s pecifici * Età
Between Groups
Within Groups
Total
(Combined)
Sum of
Squares
97.921
4387.641
4485.562
df
3
215
218
Mean Square
32.640
20.408
F
1.599
Sig.
.191
Bivariate Analysis
Connection
Correlation
ANOVA
Descriptive
Tools
Contingency
Table
Scatter Plot
Means by
Classes
Descriptive
Indexes
Chi-Square
Kramer's V
Linear
Correlation
Coeffcient
Spearman
Coefficient
Statistical
Test
Chi-Square
test
Null
Hypothesis
Statistical
Indipend.
t-Test
No linear
relation
F-Test
Indipend. by
mean
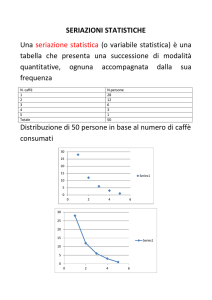
Caso Caffè
Università Carlo Cattaneo-LIUC 2010/2011
2.2. ANALISI BIVARIATA
Considerando la relazione tra
la compagnia con cui si
preferisce consumare caffè e la
concezione che si ha del
momento di consumo è
possibile avere un’idea più
completa sull’immagine da
trasmettere con la campagna
pubblicitaria. Seguendo le
analisi precedenti la maggior
parte del campione considera
il caffè un’abitudine e,
secondariamente, un rito.
TABELLA COMPAGNIA/DESCRIZIONE CONSUMO
Descrizione consumo
ABITUDIN BEVAND ESIGENZ RITO Totale
Compagnia
E
A
A
51
9
14
24
98
24.52
4.33
6.73
11.54 47.12
AMICI
52.04
9.18
14.29 24.49
53.13
36
41.18 45.28
9
6
6
3
24
4.33
2.88
2.88
1.44 11.54
COLLEGHI
37.5
25
25
12.5
9.38
24
17.65
5.66
19
4
8
16
47
9.13
1.92
3.85
7.69 22.6
FAMIGLIA
40.43
8.51
17.02 34.04
19.79
16
23.53 30.19
17
6
6
10
39
8.17
2.88
2.88
4.81 18.75
SOLO
43.59
15.38
15.38 25.64
17.71
24
17.65 18.87
96
25
34
53
208
Totale
46.15
12.02
16.35 25.48 100
27
Università Carlo Cattaneo-LIUC 2010/2011
Delle 96 persone che hanno scelto “abitudine” 51
preferisce berlo con gli AMICI, 19 con la FAMIGLIA, 17 da
SOLO e 9 coi COLLEGHI.
Delle 53 persone che hanno scelto “rito” 24 preferiscono
berlo con gli AMICI, 16 con la FAMIGLIA, 10 da SOLO e 3
coi COLLEGHI.
Risultati che indicano comunque come si preferisca
consumare una tazzina di caffè con gli amici e, in secondo
luogo, con la famiglia.
Infatti in generale la distribuzione marginale della
variabile “AMICI” è 98 su un totale di 208, seguita da un
47 della “FAMIGLIA”.
Questo porta l’azienda a conoscere le preferenze del
consumatore e quindi trasmettere l’immagine di un
prodotto non solo vissuto come un’abitudine o un rito,
ma da consumarsi circondato da amici o famigliari. La
campagna pubblicitaria dovrebbe basarsi su questi
elementi in modo da dare al consumatore ciò che vuole e
colpire la sua attenzione.
28
Università Carlo Cattaneo-LIUC 2010/2011
TEST CHI QUADRO
Per testare l’ipotesi di indipendenza statistica tra le due variabili qualitative luogo di consumo e
compagnia si deve fare il “test chi quadro”.
Il “chi quadro” risulta essere 0,0001. Si considera un livello di significatività di 0,05
Statistic
Chi-Square
Likelihood Ratio Chi-Square
Mantel-Haenszel Chi-Square
Phi Coefficient
Contingency Coefficient
Cramer's V
DF
6
6
1
Value
27.225
26.893
5.088
0.361
0.340
0.255
Prob
0.0001
0.0002
0.0241
0,0001<<0,05 si rifiuta, quindi, l’ipotesi nulla di indipendenza statistica e si può affermare che le
due variabili sono statisticamente dipendenti.
L’azienda dovrebbe considerare questo aspetto, durante la campagna pubblicitaria, in modo da offrire
un messaggio coerente (es. creare l’immagine di un bar insieme a degli amici).
29
Università Carlo Cattaneo-LIUC 2010/2011
TABELLA LUOGO DI CONSUMO/COMPAGNIA
Compagnia
Luogo di consumo
AMICI COLLEGHI FAMIGLIA
45
7
7
21.63
3.37
3.37
BAR
66.18
10.29
10.29
45.92
29.17
14.89
29
5
29
13.94
2.4
13.94
CASA
35.37
6.1
35.37
29.59
20.83
61.7
24
12
11
11.54
5.77
5.29
DISTRIBUTORE
41.38
20.69
18.97
24.49
50
23.4
98
24
47
Totale
47.12
11.54
22.6
SOLO
9
4.33
13.24
23.08
19
9.13
23.17
48.72
11
5.29
18.97
28.21
39
18.75
Totale
68
32.69
82
39.42
58
27.88
208
100
Anche da questa tabella risulta evidente che in qualsiasi luogo si beva il caffè prevale
l’opzione AMICI. Solo a CASA è rilevante anche la compagnia della FAMIGLIA con una
frequenza di 29 pari a quella degli amici.
Quindi, dalle tabelle di contingenza analizzate, risulta come qualsiasi sia la concezione che
si ha del momento del consumo di caffè e in qualsiasi luogo lo si beva, la compagnia
preferita sia la stessa.
30
Università Carlo Cattaneo-LIUC 2010/2011
ANALISI DI CORRELAZIONE TRA LA VARIABILE ETA`
E LA VARIABILE NUMERO DI CAFFE` CONSUMATI
L’analisi è svolta per capire se esiste una relazione tra le due variabili e se è di tipo positivo o negativo.
In questo modo l’azienda, attraverso il risultato ottenuto, può concentrarsi su un’eventuale target di
clienti divisi per fascia di età.
Bisogna considerare il coefficiente di correlazione
per capire che tipo di relazione intercorre tra le due
variabili quantitative.
In questo caso il suo valore è pari a 0.03451. E’ un
coefficiente positivo, ma molto prossimo allo 0 e
quindi si può affermare che non esiste relazione tra
le due variabili.
Pearson Correlation Coefficients, N =
208
Prob > |r| under H0: Rho=0
NUMERO
ETA'
CAFFE'
ETA'
1
0.03451
ETA'
0.6207
NUMERO
0.03451
1
CAFFE'
NUMERO
0.6207
CAFFE'
Come
si può osservare nel grafico, non vi
MEDIA
CAFFE’
è una correlazione lineare, né tantomeno
positiva, tra le variabili età e numero di
caffè bevuti.
ETA’
31
Università Carlo Cattaneo-LIUC 2010/2011
ANALISI DI CORRELAZIONE TRA LE VARIABILI
QUANTITATIVE ETA` E PROPENSIONE ALL’ACQUISTO
Questa analisi può essere utile per capire se la sensibilità al prezzo possa variare con il
variare dell’età.
Nel caso in questione il coefficiente
Coefficienti di correlazione di Pearson, N = 208
di correlazione risulta essere Prob > |r| con H0: Rho=0
0.19727, valore negativo che ci porta
ETA
SPESABAR
a dire che esiste una relazione
ETA
1
-0.19727
lineare negativa tra le due variabili:
ETA
0.0043
SPESABAR
-0.19727
1
all’aumentare dell’età diminuisce la
SPESABAR
0.0043
disponibilità a pagare.
L’azienda può usare questi dati per
capire in che modo l’età influisca sulla
sensibilità al prezzo e, di conseguenza,
decidere che strategie di prezzo
assumere in base al target su cui ci si
focalizzerà.
80
60
E
T
A
40
20
1
2
3
SPESABAR
32
Università Carlo Cattaneo-LIUC 2010/2011
TEST T
Infatti, eseguendo il test t, considerando il valore 0.0043 e prendendo come livello di
significatività il valore 0.05 risulta essere 0.0043<0,05.
Si rifiuta quindi l’ipotesi nulla di indipendenza lineare. Le due variabili età e spesa al bar sono
dipendenti.
Coefficienti di correlazione di Pearson, N = 208
Prob > |r| con H0: Rho=0
ETA
ETA
SPESABAR
1
-0.19727
ETA
0.0043
SPESABAR
-0.19727
SPESABAR
0.0043
1
33
Università Carlo Cattaneo-LIUC 2010/2011
TEST F
Col test F si può considerare la relazione tra variabili indicanti le caratteristiche del campione
( età, professione) e le abitudini di consumo del caffè.
La professione potrebbe influenzare il numero di caffè bevuti giornalmente: per esempio una
persona che svolge turni di notte potrebbe bere caffè per l’esigenza di mantenersi sveglio.
Anche l’età è un fattore rilevante che potrebbe spingere le persone ad avere diverse abitudini
e diverse preferenze.
Col test F si può capire se sussiste realmente questa relazione accettando o rifiutando
l’ipotesi nulla di uguaglianza tra medie. All’azienda è utile per avere idee chiare e prendere
decisioni relative al consumatore target e alla comunicazione più idonea da farsi.
34
Università Carlo Cattaneo-LIUC 2010/2011
Test F tra le variabile qualitativa professione e la variabile quantitativa numero
di caffè bevuti in un giorno
Source
Model
Error
Corrected Total
DF
5
202
207
Sum of Squares
30.3848377
457.3026623
487.6875
Mean Square F Value Pr > F
6.0769675
2.68 0.0225
2.2638746
R-Square
Coeff
Var
Root MSE
NUMCAF Mea
n
0.062304
53.49752
1.504618
2.8125
Possiamo constatare il valore di 0,0225. Valore che è minore del livello di significatività 0,05:
0,0225<0,05.
Questo porta a rifiutare l’ipotesi nulla e ad affermare l’esistenza di una relazione di dipendenza
in media tra le due variabili.
Il valore di Eta quadro, 0.06, è positivo quindi indica dipendenza in media, ma risulta essere
debole in quanto il dato è molto prossimo allo zero.
35
Università Carlo Cattaneo-LIUC 2010/2011
Test F tra la variabile quantitativa età e la variabile qualitative marca preferita
Source
Model
Error
Corrected Total
R-Square
0.037211
DF
7
200
207
Sum of Squares
1673.44718
43298.2259
44971.67308
Coeff
Var
37.58827
Mean Square F Value Pr > F
239.06388
1.1
0.3618
216.49113
Root MSE
ETA Mean
14.71364
39.14423
Possiamo constatare il valore di 0.3618. Valore che è maggiore del livello di significatività 0.05:
0.3618>0,05.
Questo porta ad accettare l’ipotesi nulla e ad affermare l’inesistenza di una relazione di
dipendenza in media tra le due variabili.
36
Percorsi di Analisi
Tipo di analisi
ANALISI UNIVARIATA
Cosa è?
La statistica descrittiva univariata ha come
obiettivo lo studio della distribuzione di
ogni variabile, singolarmente considerata,
all’interno della popolazione. Fornisce
strumenti per la lettura dei fenomeni
osservati di rapida ed immediata
interpretazione.
Strumenti
- DISTRIBUZIONI DI FREQUENZA
- INDICI DI POSIZIONE (MISURE DI TENDENZA CENTRALE E MISURE
DI TENDENZA NON CENTRALE)
- INDICI DI DISPERSIONE
- MISURE DI FORMA DELLA DISTRIBUZIONE
La statistica descrittiva bivariata si occupa
Due variabili qualitative o quantitative discrete:
dello studio della distribuzione di due
TABELLA DI CONTINGENZA E INDICI CHI QUADRO E V DI CRAMER
variabili congiuntamente considerate.
TEST CHI QUADRO PER L'INDIPENDENZA STATISTICA
Due variabili quantitative continue:
ANALSI BIVARIATA E TEST STATISTICI I test statistici per lo studio
INDICE DI CORRELAZIONE DI PEARSON (ρ) E COVARIANZA
PER LO STUDIO DELL'ASSOCIAZIONE dell'associazione tra variabili ci
TRA VARIABILI
permettono di formulare delle ipotesi e TEST t PER L'INDIPENDENZA LINEARE
verificarle tramite i dati campionari. I dati Una variabile qualitativa e una quantitativa continua:
campionari sono utilizzati per stabilire se INDICE η2
tale ipotesi è ragionevolmente accettabile TEST F PER L'INDIPENDENZA IN MEDIA
o rifiutabile.
ANALISI MULTIVARIATA
L'analisi statistica multivariata e' l'insieme
di metodi statistici usati per analizzare
simultaneamente più variabili. Esistono
molte tecniche diverse, usate per
risolvere problemi anche lontani fra loro.
- ANALISI FATTORIALE
- REGRESSIONE LINEARE
- REGRESSIONE LOGISTICA
- SERIE STORICHE