Indici Inversi
Alla ricerca del testo ...
Marco Gori, Università di Siena
anno accademico 2004-2005
1
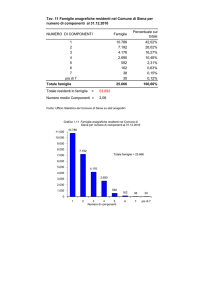
Indici per Database Relazionali
Name
Dipendente
Gori
Tabella dipendenti
Università di Siena..
Gori
Query:
Nome = “Gori”
SQL: create index EmpNmX on Employee(Name)
Strutture: hashing, B+-tree
Marco Gori, Università di Siena
anno accademico 2004-2005
2
Indici Inversi
Indice documento
Posizioni all’interno
di D1
D1
D2
computer
grafo
D1, 21, 88, 109 D3, 41
D2, 5 D3, 30
D3
Match parziale: ’%database% ’, wildcards
Ricerca frasi: che documento contiene “computer
graph”
Marco Gori, Università di Siena
anno accademico 2004-2005
3
Indici inversi
Informazione
ausiliaria, e.g.,
posizione parole, num.
occorrenze
Index terms/
vocabulary
architecture
D1, a1
computer
Q = term1, term2, term3, ...
database
D1, a1
...
retrieval
Index/
Index files/
index database
D1, a1
Postings lists
Il file indice può essere implemen. in modo diverso
Marco Gori, Università di Siena
anno accademico 2004-2005
4
Boolean Retrieval
Query Booleana: n termini connessi con operatori
Boolean, e.g., “computer AND news AND NOT
newsgroup” Le parentesi si possono usare per def.
precedenze.
A and B
Combin. Risultati (isomorfismo):
AND: intersezione insiemi
OR: fusione insiemi
NOT: differenza (NOT x è difficile da valutare;
x AND NOT y è chiaro!)
Marco Gori, Università di Siena
anno accademico 2004-2005
A
B
5
Problemi indici inversi
Grande overhead di spazio! (50% - 150% - 300%)
Alto costo per updates, insertions, deletions
Il costo di elaborazione incrementa con il numero degli
operatori Boolean
Domande:
Perché si arriva ad overhead oltre il 100%?
Sarebbe possibile 2-3% storage overhead?
In sostanza: serve comprimere!
Marco Gori, Università di Siena
anno accademico 2004-2005
6
Vincoli di Distanza
Condizioni di adiacenza e.g.,
“database” immediatamente seguito da “systems”
i.e., cerca “database systems”
“database” e “systems” non più lontani di 3 parole
“database” e “architecture” nella stessa frase.
Richiede estensioni:
Gli indici invertiti mantengono le locazioni di
keywords dentro documenti, e la locazione di
documenti (titolo, paragrafi, ecc...)
Marco Gori, Università di Siena
anno accademico 2004-2005
7
Vincoli di Distanza
8th sentence
di D350
localizzazione sentence:
database
D345, 25 D348, 37
D350, 8
file
...
systems
D123, 5
D128, 25 D345, 25
locazione paragraph,sentence,word:
database
D345, 2,3,5
8th paragraph,
12th sentence,
1st word of D350
D348, 37,5,9 D350, 8,12,1
file
...
systems
D123, 5,4,3 D128, 25,1,12 D345, 2,3,6
Marco Gori, Università di Siena
anno accademico 2004-2005
8
Estensione: Pesi nel posting
Memorizzazione della frequenza
database
D345, 10
D348, 20
D350, 1
D123, 82
D128, 8
D345, 12
file
...
systems
“systems” è
il 20% più
frequente
di
“database”
in D345
Il secondo componente di “posting” potrebbe anche essere
qualcosa di più sofisticato di una semplice frequenza ...
Marco Gori, Università di Siena
anno accademico 2004-2005
9
Estensione: Pesi nel posting
Se si memorizza la posizione delle parole allora
il termine frequenza si trova contando le
posizioni
Due parametri importanti:
term frequency: Numero di volte che il “term”
appare in un documento
Document frequency: Numbero di documenti
contenenti un certo “term”
Marco Gori, Università di Siena
anno accademico 2004-2005
10
Sinonimi
Sono importanti per incrementare la “coverage” di una
query.
Possono essere aggiunti all’indice con puntatori
database
D345, 2,3,5
D348, 37,5,9 D350, 8,12,1
databases
dataset
...
systems
D123, 5,4,3 D128, 25,1,12 D345, 2,3,6
Marco Gori, Università di Siena
anno accademico 2004-2005
11
Troncamento (suffisso)
Troncamento suffisso: semplice forma di
stemming:
comput* : computer, computing, computation, etc.
Può essere gestita facilmente se l’indice invertito è
implementato mediante un trie
Gestione problematica mediante hash!
Alcuni sistemi forzano la lunghezza minima del
prefisso conosciuto per limitare lo spazio.
Marco Gori, Università di Siena
anno accademico 2004-2005
12
Troncamento et al.
Truncamento prefisso
*symmetry: symmetry, asymmetry,...
Molto difficile da gestire; perfino un trie non può … non
c’è un “punto di partenza”
E’ in generale difficile fare il match di parti di una
parola
Rapprentazioni con wild card
wom*n: woman,women;
wom* then check if last character is “n”
Marco Gori, Università di Siena
anno accademico 2004-2005
13
Conclusioni
L’overhead dell’indice può arrivare al 300%.
Il costo di retrieval cresce con la complicazione
delle strutture dati con i postings (e.g., pensa ai
sinonimi)
Indici inversi: buoni per ambiente relativamente
statico! (pochi inserimenti e cancellazioni)
Marco Gori, Università di Siena
anno accademico 2004-2005
14
Complementi per la lezione
Indici inversi:
I.H. Witten, A. Moffat, and T.C. Bell, “Managing Gigabytes,
Compressing and Indexing Documents and Images,”
Morgan kauffmann, 1999
chapter 3
Fondamenti di Informatica:
Tecniche di ricerca su tabelle
liste, alberi, grafi
funzioni hash
Marco Gori, Università di Siena
anno accademico 2004-2005
15