possono")
LINGUAGGIO SPECIFICO:
CPU ( Central Processing Unit ) Unità Centrale del processore
ALU (Arithmetic Logic Unit) Circuito combinatorio complesso programmabile che esegue
operazioni aritmetiche e logiche a scelta è all’interno della
CLOCK onda quadra che temporizza il lavoro del processore CPU
REGISTRO è una struttura che conserva indefinitamente dei bit ( il cui numero ne definisce il
parallelismo), finchè non ci si scrive sopra.
Se è valido un segnale di abilitazione che tutti i bit ricevono ( CK ) si può scrivere nel registro , se è
valido un segnale di lettura ( OE output enable) si può leggere dal registro.
RISC ( Reduced Instruction Computer)
CISC ( Complex Instruction Set Computer)
LM linguaggio macchina
B.D. Bus dati : via specifica per i dati con parallelismo pari ai registri dei dati
B.A. Bus address ( Bus indirizzi): con parallelismo pari ai registri degli indirizzi
RAM random access memory memoria centrale, accessibile per indirizzo, con tempo di accesso
uguale per qualsiasi indirizzo .
Istruzione: comando per il calcolatore costituito da un codice operativo ( esprime cosa il
calcolatore deve fare ) ed eventualmente da operandi ( dati su cui deve operare,
referenziati solitamente attraverso l’ indirizzo del “contenitore” in cui si
trovano, registro o locazione di memoria RAM )
Interpretazione : metodo di traduzione con cui un’istruzione viene letta , decodificata
( si interpreta il codice operativo) e immediatamente eseguita.. Le operazioni
dette vengono ripetute ogni volta che una specifica istruzione viene incontrata nel
programma ( più volte nei cicli).
Compilazione: con questo metodo di traduzione un programma scritto in un certo linguaggio
viene tradotto per intero in LM o in un altro linguaggio. Per ogni linguaggio di alto
livello sarebbe possibile la traduzione per interpretazione o per compilazione
( anche se quest’ultima è più usata), mentre per LM è possibile solo
l’interpretazione e l’interprete è l’hardware.
GERARCHIA NEI SISTEMI DI ELABORAZIONE
I sistemi di elaborazione sono molto complessi, poiché in essi interagiscono un gran numero di
elementi e c’è per di più interazione fra parti fisiche (hardware) e parti concettuali (software).
L’hardware è costituito dalla CPU ( circuiti elettronici combinatori e sequenziali ), dalla Memoria
nei suoi vari livelli, da una grande varietà di Unità di input /output e relative interfacce : in esso viene
fisicamente eseguito il lavoro di elaborazione e per esso “ il modo di ragionare” è quello dei vari
circuiti componenti ( dati binari in forma elettrica o magnetica, segnali binari di abilitazione, tempi di
risposta, temporizzazione discreta delle operazioni fornita dal’ orologio di clock ecc.) .
Per parlare del software con correttezza è necessario premettere che gli attuali calcolatori fanno
riferimento al modello di architettura di Von Neumann che non è l’unica possibile ma è così
semplice e potente da mantenerla tuttora in uso , con miglioramenti e potenziamenti rispetto al
progetto originario che è del 1946.
Il software, che ha il compito di rendere accessibile e utilizzabile l’hardware in forma “più umana”,
è strutturato a livelli:
- il più vicino all’hardware costituisce per così dire l’architettura della macchina e la rappresenta
dal punto di vista software.
L’interfaccia dell’architettura con l’esterno è il linguaggio macchina, numerico binario, realizzato
in forma cablata (calcolatori RISC) o microprogrammata (firmware) all’interno della CPU
( calcolatori CISC).
LM è costituito da un set di istruzioni che permettono di impartire al calcolatore comandi
effettivamente eseguibili dall’hardware: un programma in LM è una lista di istruzioni che , se
corrette e messe correttamente in sequenza, consentono di risolvere un problema.
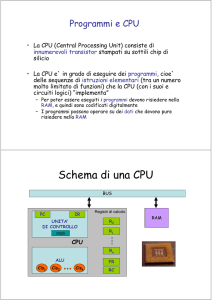
Durante l’esecuzione di un programma in LM ( detto eseguibile ) , dalla CU ( Control Unit) vengono
generati all’interno della CPU e verso l’esterno tutti i segnali che comandano e abilitano i vari
circuiti ( ALU, registri, memoria RAM ecc.) in modo che l’automa-calcolatore passando da uno stato
all’altro ( tutto ciò che è contenuto nei registri di CPU e nell’area dati in memoria RAM ) risolva il
problema di cui il programma è la traccia di soluzione che gli è comprensibile.
-
a un livello più alto si situano i linguaggi di traduzione ad alto livello che si rivolgono ai
programmatori
- al di sopra i pacchetti applicativi specifici che sono realizzati per gli utenti comuni.
- per consentire un uso agevole del calcolatore a utenti generici, ad un livello intermedio è inserito
il S.O. (Sistema Operativo).
Il S.O. è intermedio fra l’architettura e gli alti livelli menzionati e offre servizi essenziali
come l’interfacciamento con le periferiche esterne, la gestione della memoria secondaria ,
la gestione dei processi (che sono i programmi in esecuzione) , la gestione dei dati per la loro
memorizzazione permanente in files ( file system ) e servizi accessori come interfacce grafiche ,
editor , programmi per collegamenti remoti ecc.
Gli utenti possono fare uso del S.O. a vari livelli secondo la loro competenza.
Il software di S.O. viene scritto in linguaggi di vario livello e se occorre riferirsi all’architettura
specifica si possono scrivere frammenti in assembler che vengono inclusi e tradotti
separatamente in LM.
ARCHITETTURA VON NEUMANN
Secondo questa architettura un calcolatore è costituito da una memoria ( a vari livelli di accessibilità
e velocità) e da un processore ( CPU ).
Nella memoria sono contenuti ( insieme ma ad indirizzi ovviamente separati) dati e programmi.
Il processore deve estrarre le istruzioni del programma dalla memoria, interpretarle ed eseguirle
una dopo l’altra sino alla soluzione del problema. ( in questo modo il programma che è una struttura
statica “ prende vita”e diventa un processo di soluzione).
I dati vengono trasformati via via dallo stato iniziale allo stato finale che è rappresentato dai risultati.
In memoria deve essere riservato spazio per i dati di ingresso e per quelli di uscita.
I dati in uscita possono eventualmente essere sovrascritti nel corso della loro generazione ai dati in
ingresso ( cancellandoli) , sotto la personale responsabilità di chi ha scritto il programma.
N.B. La lettura di un dato non lo cambia, mentre la scrittura è distruttiva.
Si presume che la memoria di programma sia utilizzata in sola lettura ( in linea di principio
può anche non essere così ).
Le istruzioni fanno parte di un set che può essere costituito da poche istruzioni ( qualche decina)
o tante istruzioni (più di 200) appartenenti ad alcune categorie fondamentali (per ognuna è definito il
codice operativo e il formato):
- di trasferimento per lo spostamento di dati fra registri, fra registri e memoria ecc.
- aritmetico-logiche per effettuare operazioni aritmetiche e logiche, confrontare dati
verificare la verità di enunciati
- salti per interrompere la sequenza delle operazioni ( scegliere fra due alternative, ripetere più
volte istruzioni nei cicli in base a condizioni definite)
I/O e istruzioni di servizio
- eventualmente istruzioni per il trattamento di strutture dati complesse
Il meccanismo di funzionamento del processore per ogni istruzione, si articola nelle seguenti fasi
logiche:
fetch : il processore estrae dalla memoria un’istruzione (quella il cui indirizzo è nel
contatore di programma ( PC program counter) e copia il codice operativo in un
registro interno, il registro istruzione ( IR instruction register)
- decode : individua il codice dell’istruzione
- execute :esegue l’istruzione ( cerca i dati su cui operare, esegue l’operazione, memorizza il
risultato )
- determina la prossima istruzione da eseguire .
Queste fasi sono fra loro sovrapponibili nel tempo per istruzioni successive se sono soddisfatte certe
condizioni : concetto alla base delle architetture pipeline .
a) I metodi possibili per l’ultima operazione sono due: il PC viene incrementato in modo da
raggiungere l’indirizzo dell’istruzione successiva per istruzioni in sequenza, (questo
incremento viene anticipato sempre appena dopo il fetch)
b) il PC viene forzato ad un indirizzo contenuto all’interno dell’istruzione se si tratta di un salto
( la sequenza si interrompe e inizia a partire da quell’indirizzo) o di una chiamata di
procedura.
I salti, che possono essere non condizionati o condizionati, permettono di variare la rigida
sequenza di esecuzione in base a condizioni che si possono verificare in esecuzione ( risultato
dell’ultima istruzione aritmetica o logica eseguita = 0, segno positivo o negativo di un risultato,
overflow, parità pari o dispari, carry ecc.) e si deducono da registri speciali a un bit della ALU detti
flag .
Con i salti si realizzano le alternative e i cicli.
I dati su cui la CPU opera in lettura o scrittura (operandi) possono trovarsi:
- nei registri interni ( locazioni di memoria ad accesso molto.veloce)
- in memoria RAM ( lettura da memoria o scrittura in memoria)
I dati diretti in memoria o provenienti dalla memoria ( dati o istruzioni) transitano per un registro di
interfaccia col BUS DATI detto Memory Data Register ( MDR )e l’indirizzo di memoria ( di dato o
di programma ) che la CPU usa in un certo istante si trova in Memory Address Register (MAR) che
si affaccia sul BUS ADDRESS ( bus degli indirizzi ) e lo alimenta elettricamente.
Il susseguirsi delle fasi suddette fino all’istruzione di fine-programma ( Halt ) determina l’esecuzione
del programma.
Il lancio del programma è determinato dall’inserimento in PC del suo indirizzo di inizio e questa
operazione viene demandata data la sus importanza al S.O.
Se in fase di lancio si sbagliasse indirizzo, il processore si sforzerebbe di interpretare come istruzioni
le configurazioni di bit che trova e con probabilità altissima si impianterebbe.
Il parallelismo del B.D. che è lo stesso dei registri di dato della CPU determina la quantità di dati in
bytes a cui il processore fa riferimento in un ciclo di memoria( durata uno o più cicli di clock ), il
parallelismo del B.A. in bit determina il numero di indirizzi di memoria accessibili direttamente dalla
CPU con istruzioni di LM ( sono 2n) ed è lo stesso dei registri indirizzo di CPU ( es. PC , MAR ).
I registri PC, IR, MDR,.MAR, non sono referenziabili dal programmatore ma sono manipolabili solo
dall’architettura e si dicono “ trasparenti” al programmatore , i flag sono referenziabili solo
indirettamente dal programmatore nelle istruzioni di salto condizionato .
GERARCHIA DI MEMORIA
Dati e programmi possono essere in grande quantità . Nella loro gestione si deve tener conto di alcuni
criteri generali:
- I dati di lunga durata sono al momento dell’accensione del calcolatore su disco o CD, compreso
il S.O e devono comunque essere letti . Il S.O. viene letto in RAM da un piccolo programma
cablato in una ROM ( read only memory) detto bootstrap ( è un driver di lettura da disco).
Viene letta solo la parte necessaria il resto viene letto quando se ne presenta la necessità..
- i dati su cui si opera direttamente con l’ALU devono essere nei registri interni di CPU.
( tempo di accesso praticamente nullo). Se un dato viene utilizzato più volte conviene stia in un
registro interno per evitare continui accessi alla RAM ( tempi dell’ordine dei nanosecondi)
- quando un programma è in esecuzione il segmento di codice che contiene le istruzioni deve
trovarsi in RAM.
- è consigliabile che un programma si trovi se possibile in RAM perché la gestione della memoria
secondaria che è delegata al S.O. richiede tempi lunghi in confronto ai tempi di CPU
( ordine dei millisecondi)
-
-
per incrementare le prestazioni della CPU e ridurre le attese riguardanti il tempo di accesso alla
memoria è opportuno inserire fra CPU e memoria centrale una memoria accessibile più
velocemente ( SRAM , RAM statica ad alte prestazioni) detta cache dove vengono tenuti dati e
programmi ( o pezzi di programma) utilizzati frequentemente con il criterio della vicinanza nel
tempo e nello spazio.
Si presume infatti che i dati vicini nello spazio ( istruzioni contigue e dati vicini perché inseriti in
strutture vicine) e recentemente utilizzati cioè vicini nel tempo, abbiano più probabilità di altri di
essere utilizzati in futuro.
La memoria centrale può essere realizzata in DRAM ( dinamica) o anche SRAM con
prestazioni in velocità di accesso inferiori alla cache (e minor costo).
La DRAM deve però essere periodicamente rinfrescata ( con letture) perché i dati tendono
a decadere essendo memorizzati in condensatori che con il tempo si scaricano.
-
Lo scambio di dati fra CPU, cache e RAM è gestito dall’architettura, mentre lo scambio fra
RAM e memoria secondaria è gestito dal S.O.
Un programma ,scritto in un qualsiasi linguaggio, deve essere tradotto per forza in Lm con il metodo
della compilazione o della interpretazione ; la traduzione si esegue con un programma traduttore
( per cui i dati in ingresso sono le sequenze di caratteri che formano le istruzioni del linguaggio di
partenza e i dati in uscita sono le istruzioni del linguaggio di arrivo).
Con un traduttore di tipo compilatore una istruzione del linguaggio corrisponde a più istruzioni
macchina e il criterio di traduzione dipende del compilatore.
Il programma è più facile da scrivere, ma l’esecuzione può essere più o meno efficiente.
Per chi vuole scrivere programmi che siano traducibili in LM uno-uno ci sono i linguaggi
Assembler (specifici per ogni macchina) , di tipo compilatore ,che consentono di trascrivere
in simbolico il linguaggio numerico e forniscono servizi di dichiarazione delle variabili e di
specifiche per la traduzione ( pseudo-istruzioni ) .
 possono")