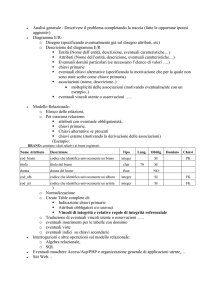
Progettazione - Modelli: concettuale, E/R e logico:
la definizione di un modello concettuale;
la definizione di un diagramma Entità/Relazione (E/R);
la definizione del modello logico
o definizione di attributi
o chiavi primarie e secondarie
o relazione molti a molti
L'importanza della progettazione
Quando si inizia la creazione di un DataBase la cosa più importante è la
progettazione.
In questa fase si stabilisce la forma che il DataBase avrà, quale sarà
l’oggetto e lo scopo.
Dopo aver verificato se la natura dei dati possa appartenere ad una delle
tipologie di Database si procede con l’identificazione di tutti gli elementi
necessari per la realizzazione dell’archivio e si valuta l’economicità della
presenza delle informazioni e si stabilisce il miglior modo di rappresentarle.
Quando tutte le problematiche che ci vengono poste dalla natura stessa
delle informazioni sono risolte si può passare alla creazione del DataBase
con l’ausilio del DBMS che maggiormente risponderà alle esigenze
funzionali e agli scopi che ci si è prefissati.
Il progetto è il punto di partenza di ogni DataBase e ne determina il
successo.
Sarà opportuno rivedere l’intero progetto riprendendolo dalle sue fasi iniziali
se durante la sua realizzazione si dovessero rilevare degli elementi nuovi
che arricchiscono o che cambiano alcune delle impostazioni e decisioni
precedentemente prese.
Le fasi della progettazione si distinguono per il grado di astrattezza che le
caratterizzano.
Si passa dalla definizione del modello concettuale (scelta del DBMS e, se si
trattasse di dati relazionali, definizione dello schema Entità-Relazione E.R.),
alla fase di definizione del modello logico (definizione di attributi e campi di
collegamento) per giungere infine alla realizzazione fisica del DataBase con
il modello Fisico.
Il modello concettuale
Fornisce una rappresentazione semplificata della realtà. Il grado di
semplificazione dipende dalle scelte che si impone chi sviluppa il modello.
Si tratta quindi di definire un insieme di dati presenti in natura e che
rappresentano la natura stessa delle informazioni che si vogliono archiviare.
I dati poi devono essere individuati in modo tale che rispondano allo scopo
per il quale si crea il modello.
Non esistono pertanto delle regole prefissate per l’individuazione dei dati e
per la loro selezione: ad uno scopo diverso corrisponde un insieme di dati
diverso e quindi un modello concettuale diverso.
A seconda quindi delle scelte che si operano si otterranno modelli
concettuali diversi
:: Esempio ::
OGGETTO
Un corso universitario viene frequentato da un gruppo di studenti.
Si stabilisce che per ogni a.a. per questo corso si svolgano:
1. esercitazioni di tipo pratico;
2. seminari;
3. elaborazione di tesine scritte.
Tali attività sono organizzate per gruppi.
Ogni gruppo viene seguito da un docente che stabilisce un programma per
ogni a.a. e gruppo seguito.
Ogni docente segue più di un gruppo in un a.a.
La valutazione del partecipante al corso avviene tramite una prova pratica,
una orale e una scritta.
Il docente valuta i partecipanti al corso a seconda dell’anno accademico di
frequenza e al programma svolto in quell’anno accademico.
Le valutazioni delle esercitazioni avvengono a cura del docente che ha
organizzato e seguito il corso.
SCOPI
Viene chiesto di sviluppare un DataBase in grado di archiviare tutte le
informazioni e dal quale si possa ottenere:
- liste dei partecipanti ai gruppi di esercitazioni e impegno dei singoli docenti
interessati;
- liste per le varie prove con la definizione dei programmi sui quali i
partecipanti al corso devono prepararsi e i dati del docente che ha valutato
la prova;
- liste dei risultati divisi a seconda del tipo di prova e media finale dei voti
delle tre prove;
- cronologia dei programmi per ogni anno accademico previsto con i dati dei
docenti
Diagramma/Modello Entità-relazione (ER)
Dopo aver formalizzato la semplificazione della realtà da studiare o
archiviare secondo gli scopi che si vogliono realizzare arriva il momento di
decidere a quale tipo di DataBase può appartenere il nostro archivio.
Nel caso proposto (un corso universitario …) la tipologia che meglio
permette di gestire le informazioni è il modello relazionale.
Essendo questo modello fortemente legato alla teoria degli insiemi si
procederà all’identificazione delle entità o insiemi di dati, che saranno
necessarie al database per realizzarne gli scopi.
Le entità si definiscono come oggetti che possono essere identificati in modo
chiaro in un determinato contesto, le cui proprietà chiamate attributi sono
oggetto di archiviazione.
Bisogna fare molta attenzione al livello di astrazione ancora presente in
questa fase che prevede l’individuazione di insiemi di dati (oggetti) che
caratterizzano l’archivio e non si occupa di analizzare le singole
caratteristiche.
Diagramma E/R
Dopo aver identificato gli insiemi di dati da archiviare, si definiscono i legami
esistenti tra essi: le relazioni. Le relazioni rappresentano i legami o
dipendenze o associazioni di interesse informativo che esistono tra le entità
che compongono il DataBase. Tali legami sono definiti in base alla natura
stessa delle entità e verranno pertanto definiti tramite lo studio stesso dei
dati.
Le relazioni vengono classificate secondo la loro cardinalità in:
relazioni uno ad uno (1:1);
relazioni uno a molti (1:M) e
relazioni molti a molti (M:M
• La relazione uno a uno (1:1) significa che
ad un elemento dell’entità A corrisponde un solo elemento dell’entità
B e che
ad un elemento dell’entità B corrisponde ad un solo elemento
dell’entità A.
Ad esempio ad un singolo studente corrisponde un solo piano di
studi e a un piano di studi corrisponde un solo studente.
• La relazione uno a molti (1:M) significa che
ad un elemento dell’entità A corrispondono molti elementi dell’entità B e che
ad un elemento dell’entità B corrisponde ad un solo elemento dell’entità A.
Ad esempio ad un singolo corso di laurea corrispondono molti studenti
(iscritti a quel corso di laurea), a uno studente corrisponde un solo corso di
laurea (lo studente si iscrive esclusivamente ad un corso di laurea).
• La relazione molti a molti (M:M) significa che
ad un elemento dell’entità A corrispondono molti elementi dell’entità B e che
ad un elemento dell’entità B corrispondono molti elementi dell’entità A.
Ad esempio ad un singolo piano di studi corrispondono molti insegnamenti e
ad ogni insegnamento corrispondono molti piani di studio.
Nota bene. La definizione della relazione si stabilisce analizzando il
rapporto in maniera bidirezionale: A => B; A <= B. E’ molto importante
effettuare entrambe le verifiche altrimenti si rischia l’errata identificazione del
tip o di relazione
Nel nostro esempio la definizione di un diagramma ER si formalizza così:
1) un partecipante al corso partecipa a più esercitazioni – ad
un’esercitazione partecipano più partecipanti al corso - M:M
2) un’esercitazione è tenuto da un docente – un docente può tenere più
esercitazioni - 1:M
3) un partecipante al corso ottiene più risultati d’esame (orale, scritto,
pratico) – un risultato d’esame viene ottenuto da un solo partecipante al
corso - 1:M
4) in un’esercitazione si tratta un programma d’esame – un programma
d’esame viene trattato da più esercitazioni - 1:M
Modello logico
Questo modello permette di definire l’organizzazione dei dati, le modalità di
accesso e le viste, cioè gli schemi esterni.
In questa fase si svilupperà il modello logico relativo al tipo di database che
si ritiene più adatto alle informazioni da archiviare. Il modello logico dipende
quindi dal tipo di DBMS che i dati richiedono.
Nel caso di un DataBase di tipo relazionale, il modello logico si occuperà di
stabilire:
1. gli attributi relativi alle entità e
2. le chiavi interne (chiavi primarie) ed esterne per la concretizzazione delle
relazioni emerse dal diagramma E-R
Gli attributi
Definiamo inizialmente gli attributi che sono necessari per ogni entità.
Un’attributo rappresenta un’informazione relativa ad un insieme di dati
(entità). Quando si scelgono le informazioni da archiviare si valuteranno gli
scopi del DataBase ed in base all’uso che si desidera fare dei dati si
includeranno alcune informazioni e se ne escluderanno altre presenti nella
realtà.
Nel nostro esempio, per l’entità “partecipante al corso” può interressare
archiviare il Nome e il Cognome ma si tralascerà il colore dei capelli o il
numero dei fratelli/sorelle.
Nel caso di un Database dove si desidera ottenere informazioni sulla
relazione esistente tra il numero di studenti iscritti ad un determinato corso e
il numero dei fratelli o del colore dei capelli dello studente, ci si troverà in
una situazione completamente diversa. Ciò che si è escluso nella prima
ipotesi diventa fondamentale nella seconda.
Ecco alcune regole che aiutano nella scelta degli attributi:
1. non creare un campo che può essere calcolato da altri campi.
Ad esempio: un attributo “Età” in un entità che contiene la “data di nascita” è
un attributo che occupa spazio inutilmente dato che sarà facile estrapolare
l’informazione dal secondo atttributo operando la differenza tra la data
odierna e la data di nascita. Si noti inoltre che l’“età” è un’informazione
dinamica che dipende dal passare del tempo. Se si calcola il valore dell’età
in base alla “data di nascita” si ottiene un valore che dinamicamente
cambierà a seconda del giorno nel quale eseguo l’interrogazione all’archivio.
L’attributo “età” invece è rappresentata da un numero che deve essere
aggiornato manualmente con il passare del tempo.
2. un campo deve contenere un’unica informazione.
Per esempio se si crea un attributo “Cognome e nome” esso racchiude in se
due elementi diversi: il nome e il cognome. E’ buona norma separare le due
informazioni in due attributi diversi. Ciò permetterà un utilizzo più facile
dell’informazione e la possibilità di interrogazioni più semplici.
3. non creare campi che assumono un unico valore.
Se ad esempio inserisco l’attributo nazione nell’entità partecipanti al corso e
so che gli studenti sono tutti residenti nella provincia o regione dove si tiene
il corso tale campo assumerà sempre il valore Italia. Non è utile all’economia
del DataBase, occupa spazio senza offrire un’informazione utile
all’utilizzatore dell’archivio.
Ecco come potrebbe presentarsi il modello logico del
nostro esempio.
(Si tenga presente che per semplicità ci si limiterà solo ad alcuni attributi)
Le chiavi
Dopo aver stabilito gli attributi per ogni entità si creano le basi per la
realizzazione concreta delle relazioni individuate nel modello E-R. Si
prevedono pertanto, le chiavi primarie o interne e le chiavi esterne.
Le chiavi sono attributi che contengono dei dati (nella maggior parte
dei casi “codici numerici”) inseriti perché si possa in seguito
realizzare la relazione tra le entità.
Il computer elabora operazioni matematiche e in base a queste può
stabilire se un dato entra in dialogo o no con un altro. Il metodo
utilizzato è il confronto. Cioè si confronta il valore di un attributo
(chiave primaria) di un’entità con il valore di un attributo (chiave
secondaria) di un’altra entità. Se i due valori sono uguali e quindi il
confronto si risolve con un esito positivo, i dati sono legati tra loro
altrimenti non lo sono.
Nelle entità in esempio non esiste la possibilità di stabilire chi ha
sostenuto un esame. Per poter legare tra loro le informazioni contenute
nelle due entità potrei inserire il nome e cognome del partecipante
nell’entità Risultati degli esami.
Così facendo si è realizzata la possibilità di creare un legame tra i due
gruppi di informazioni. Rossi Mario (entità partecipanti al corso) ha sostenuto
tutti gli esami (entità risultati degli esami) dove risulta il suo nome e
cognome.
Escludendo la possibilità che ci siano due partecipanti al corso omonimi
(stesso nome e cognome), gli attributi Cognome e Nome dell’entità
partecipanti al corso identificano ogni singolo partecipante in maniera
univoca. I due attributi (cognome, nome) formano una chiave primaria
Nella entità risultati degli esami il nom_part e cogn_part, invece mi
informano su chi ha sostenuto l’esame. In questa entità gli attributi non
identificano univocamente l’oggetto dell’entità, come per partecipanti al
corso, ma si limitano a specificare l’identità di chi ha sostenuto l’esame. In
questo caso questa informazione non è univoca e viene ripetuta tutte le volte
che un partecipante sostiene un esame. I due attributi (cognome, nome)
formano una chiave secondaria
Chiavi primarie (interne) e chiavi secondarie (esterne)
Per poter effettuare il confronto e quindi stabilire una relazione tra entità, è
necessario predisporre uno o più attributi per ognuna delle due entità che
possiedano le potenzialità per entrare in relazione tra loro, cioè:
1 - avere la stessa natura
Si pensi a cosa accadrebbe in un confronto tra numeri e lettere o tra numeri
e date. Avremmo un alta probabilità di fallimenti delle relazioni.
2 - avere sempre un valore
Quando manca il valore, il confronto è impedito dall’impossibilità di
identificare un’informazione rispetto a tutte le altre.
3 - avere valori univoci in almeno uno degli attributi
Una chiave primaria identifica la parte della relazione “uno”. La parte dove
esiste un solo dato che entra in contatto con uno o più informazioni presenti
nelle altre entità. Risulta quindi importante che la chiave dove si poggia
questo lato della relazione risponda alle caratteristiche stesse della relazione
e ne tuteli e preservi la correttezza.
Chiavi primarie o interne
Gli attributi che posseggono tutte e tre le caratteristiche vengono chiamati
chiavi primarie o interne.
Chiavi secondarie o esterne
Vengono chiamati chiavi secondarie o esterne se rispondono alle prime due
caratteristiche ma non necessariamente alla terza.
Le chiavi esterne infatti sono la base di appoggio del lato “molti” della
relazione ed è corretto che l’attributo che permetterà il dialogo con le altre
entità possa assumere più volte lo stesso valore. In caso contrario non
sarebbe possibile ottenere il lato “molti” di una relazione.
Ovviamente il ragionamento è diverso se si tratta di una chiave esterna in
una relazione uno a uno. In tal caso è preferibile che la chiave esterna
preveda l’inserimento di soli valori univoci (terza caratteristica).
Nell’esempio precedente si sono utilizzati gli attributi Nome e Cognome in
partecipanti al corso come chiave primaria e nom_part e cogn_part in
risultati degli esami come chiave secondaria
Le chiavi sono formate da attributi che
hanno la stessa natura (testo),
hanno sempre un valore
(un esame è sempre sostenuto da un partecipante al corso i cui dati
devono sempre essere presenti),
a) in partecipanti al corso esisterà solo uno studente con quel nome
e cognome (primarietà della chiave - parte della Relazione 1),
b) in risultati degli esami il legame con i partecipanti (cogn_part,
nom_part) avrà tanti valori quanti sono gli esami sostenuti dal
partecipante al corso (secondarietà della chiave - parte della
Relazione M)
Nell’esempio proposto abbiamo poggiato l’univocità della chiave primaria sul
presupposto che non ci possano essere due partecipanti al corso con lo
stesso nome e cognome ma questa ipotesi nella realtà si può verificare e
non prevederla potrebbe causare problemi di gestione del Database.
Cognome e nome non rappresentano quindi un attributo adatto per poggiare
la parte della relazione 1.
Mancano cioè di una reale univocità.
Un attributo sicuramente univoco potrebbe essere il codice fiscale o il
numero di matricola. Si possono aggiungere al modello logico appena
sviluppato anche se inizialmente non erano stati previsti.
Se si utilizza il codice fiscale o il numero di matricola come chiave primaria,
nell’entità risultati degli esami devono essere eliminati gli attributi cogn_part
e nom_part perché le informazioni in essi contenuti non sono utili ne’ alla
relazione, ne’ all’archivio in quanto già inseriti nell’entità partecipanti al
corso.
Verranno sostituiti da un attributo (chiave secondaria) che può prendere il
nome di CF_part (se la chiave primaria è costituita dal codice fiscale) o
Matr_part (se la chiave primaria è costituita dalla matricola).
Identificatore (ID)
Se i dati di una determinata entità non hanno attributi univoci “naturali”
si possono predisporre dei codici appositi. Il tipo di attributo (chiave
primaria) più adatto allo scopo è un Identificatore (ID) numerico: un
numero progressivo, univoco. Come chiave secondaria si utilizzarà un
attributo numerico anch’esso ma non necessariamente univoco, che
potrebbe chiamarsi cod_part.
Spesso per questioni di dimensioni del file (spazio di occupazione del
disco fisso), si preferisce quest’ultima soluzione anche quando tra gli
attributi si trovano dei codici univoci “naturali” (codice fiscale o
matricola).
La si preferisce perchè:
i valori numerici occupano meno spazio su disco rispetto ai valori
testuali
il DBMS normalmente mette a disposizione un numero univoco di
identificatore (ID) creato direttamente e quindi esente da errori,
soprattutto da errori di duplicazione del codice o di digitazione
l’identificatore del DBMS è sicuro perché il gestore crea sempre un
valore senza un’azione specifica dell’utente e quindi non verrà mai a
mancare
Ecco un esempio di chiavi espesse tramite valori numerici
Unico aspetto negativo potrebbe essere rappresentato dalla difficoltà di
memorizzazione dei codici identificativi creati dal DBMS.
Questa difficoltà viene superata grazie a strumenti grafici semplici e intuitivi
o grazie ad un’opportuna programmazione. Ciò potrà essere previsto e
realizzato nella fase esecutiva del progetto.
Il grado di fruibilità del Database è molto legato alla capacità del gestore e di
chi realizza il database di fornire o prevedere l’uso di strumenti quali :
o di prevedere le esigenze degli utenti e fornire gli strumenti più adatti a
soddisfarle.
Nota bene
Un buon DataBase non richiede conoscenze informatiche
particolarmente avanzate agli utenti che lo devono utilizzare.
Se si interroga un Database in internet, per esempio chiedendo il
preventivo di un computer personalizzato, non è nemmeno previsto
che si conoscano i database. E’ sufficiente seguire le istruzioni sullo
schermo, il più delle volte elementari, per raggiungere lo scopo: il
preventivo di un computer.
Se si interroga il Database di una biblioteca, il gestore dei dati ci
guiderà nella scelta del tipo di interrogazione e delle chiavi di ricerca
necessarie e si raggiungerà lo scopo senza avere la sensazione
dell’elaborazione effettuata dal DBMS e del numero di informazioni
valutate.
Relazione molti a molti
Per realizzare una relazione molti a molti non è sufficiente predisporre una
chiave primaria e una chiave esterna nelle due tabelle che entrano in
relazione.
Se si deve creare un database con una relazione molti a molti sarà utile
conoscere le regole di normalizzazione dei DataBase. Ciò permetterà di
comprendere appieno i motivi che spingono colui che progetta il database a
sviluppare entità non previste nel modello concettuale o logico ma
necessarie al buon funzionamento dell’archivio e alla creazione delle
relazioni molti a molti.
Normalizzazione:
Ridondanza e incoerenza nei rapporti di coerenza tra entità
Un esempio di relazione molti a molti risolta seguendo le forme di
normalizzazione
Forme normali
o prima forma normale;
o seconda forma normale;
o terza forma normale
Normalizzazione
Alcune semplici regole aiutano chi progetta il database nella realizzazione di
uno strumento agile ed efficiente. Dopo aver stabilito le entità e gli attributi
delle entità che si ritengono opportune per lo scopo e la natura dei dati che
si vuole archiviare è utile procedere alla normalizzazione dello schema
realizzato.
Le regole di normalizzazione sono l’esplicitazione teorica di alcuni problemi
che possono emergere durante l’utilizzo, l’interrogazione e la gestione dei
dati in un DataBase e che possono impedire o rendere complicato l’uso delle
informazioni archiviate in esso.
Non è sempre possibile applicare le regole di normalizzazione. In tali casi si
dovranno risolvere i problemi provocati dalla mancata normalizzazione che
possono presentarsi, oppure è possibile che il DBMS che si utilizza sia in
grado di fornirci strumenti che gestiscono le situazioni reali senza bisogno di
applicare le regole di normalizzazione.
Le regole o forme normali sono numerose anche se in genere si ritiene che
l’applicazione delle prime tre forme normali permetta di raggiungere un
adeguato grado di efficienza del DataBase.
Le regole prendono i seguenti nomi:
•
•
prima forma normale (presenza di dati aggregati);
seconda forma normale (dipendenza parziale dalla chiave
primaria);
•
terza forma normale (dipendenza indiretta dalla chiave primaria).
Oltre a queste prime tre forme normali, ne sono state formalizzate altre
come: forma normale Boyce/Codd; quinta forma normale; forma normale
Strong Join-Protection; forma normale Over-Strong Join-Protection; forma
normale Domain –Key.
L’applicazione delle forme normali permette di eliminare i problemi di
ridondanza dei dati e i problemi di incoerenza nei rapporti di dipendenza dei
dati.
La ridondanza comporta che alcune informazioni vengono ripetute
all’interno del DataBase in entità diverse.
Questa ripetizione complica le fasi di correzione e modifica dei dati e
rappresentano uno spreco di tempo in fase di immissione dati ed infine
occupano inutilmente spazio e memoria.
L’incoerenza nei rapporti di dipendenza tra entità creano difficoltà di
raggiungimento dei dati o impossibilità di raggiungimento di determinate
informazioni.
Le relazioni esistenti tra i dati creano la possibilità di raggiungere tutte le
informazioni contenute nel DataBase rispettando i vincoli naturali che le
legano tra loro.
Quando si verificano incoerenze nei rapporti di dipendenza alcuni dati si
ritrovano slegati dal resto delle informazioni e non sono più raggiungibili.
Diventa pertanto inutile la loro presenza e uno spreco inutile l'uso di spazio e
memoria per il loro mantenimento all'interno del DataBase
Nota bene.
L’applicazione delle regole è graduale. Inizialmente il DataBase deve
soddisfare la prima forma normale.
Solo dopo aver verificato che questa regola è rispettata si può applicare la
seconda forma normale e in seguito la terza
:: ESEMPIO ::
Prendiamo in considerazione i dati relativi ai partecipanti al corso raccolti
dalla segreteria in schede personali relative ai singoli studenti.
Qui sotto appaiono le schede così come sono archiviate dalla segreteria.
In tali schede sono raccolti i dati che si desidera archiviare nel DataBase.
Seguendo l’esempio proposto ecco un esempio di entità che possa
raccogliere i dati contenuti nelle schede personali degli studenti
ma …
Secondo la definizione della Prima
forma normale:
Un’entità deve contenere attributi che contengono una sola
informazione e che siano “atomici”.
L’informazione già contenuta in un attributo non deve essere contenuta
all’interno dell’entità in altra forma o in un attributo con nome diverso.
L’esempio illustrato si nota la presenza di dati aggregati.
Orario1, orario2, orario3
contengono la stessa informazione ma in tre attributi con nome diverso
come anche
tipo1, tipo2, tipo3
Un partecipante al corso partecipa a molti gruppi di esercitazioni ma definire
tanti attributi quanti si pensa possano essere i gruppi ai quali partecipa uno
studente non è corretto.
Difficoltà
La prima difficoltà la si incontra per esempio se si cerca di reperire le
informazioni di tutti gli studenti iscritti ad esercitazioni di laboratorio. Per
ottenere questo dato è necessario interrogare tutti gli attributi coinvolti.
Un’altra difficoltà è rappresentata dalla staticità della decisione che un
partecipante ai corsi può frequentare non più di tre gruppi di
esercitazioni.
Nel caso di studenti (vedi Verdi Carlo) che partecipino a quattro o più
gruppi si dovrà ristrutturare l’entità aggiungendo gli attributi necessari
per il 4° corso frequentato (orario 4, a.a. 4, tipo 4, front./auto 4, id_doc
4, id_prog. 4) oppure creare un inserimento supplementare (la
seconda riga con le informazioni di Verdi Carlo) come nell’esempio,
per inserire le informazioni che mancano.
Anche tutti gli strumenti di interrogazione o di visualizzazione o di
stampa, predisposti successivamente che si appoggiano ad essa
dovranno essere modificati.
Si creano inoltre molte celle vuote che vengono create inutilmente e
che occupano memoria senza aggiungere informazioni al DataBase.
Non è quindi corretto creare una entità come
nell’esempio.
Applicare la prima forma normale nell’esempio significa eliminare tutti gli
attributi sovrabbondanti (orario2, 3, a. a.2, 3, tipo 2, 3, front./auto 2, 3,
id_doc 2, 3, id_prog 2, 3).
Per inserire le informazioni relative al corso si produrranno gli attributi:
orario, a. a., tipo, front./auto, id_doc, id_prog.
Si noti che per inserire tutte le informazioni relative a Rossi Mario si devono
creare due istanze o tuple, per le informazioni di Verdi Carlo se ne creano
quattro e per Bianchi Maria due.
Entità: Dati originali
Entità: Dati originali
Vantaggi
Agendo in questo modo si ottiene:
•
è molto più semplice interrogare i dati perchè si deve interpellare
un solo attributo.
Nell’esempio per sapere quanti corsi sono di tipo seminariale è sufficiente
interrogare l’attributo tipo
•
la struttura dell’entità non ha necessità di essere modificata e si adatta
con più elasticità alla realtà dei dati.
Nel caso in cui uno studente partecipi a 5 o 10 o 20 corsi, per memorizzare
le informazioni sarà sufficiente creare tante istanze quanti sono i corsi
frequentati senza incidere sul numero o tipo di attributi che compongono
l’entità.
•
l’istanza o tupla viene creata solo in presenza di informazioni relative
al corso frequentato che devono essere memorizzate.
Non verranno quindi create celle vuote e non si occuperà memoria
inutilmente.
Entità: Dati originali
Difficoltà
Ma nell’esempio accade che avrò sovrabbondanza di informazioni
(ridondanza) relative ai partecipanti ai corsi ma anche di informazioni
relative ai gruppi di esercitazioni.
Si dovrà agire per risolvere tale problema applicando la seconda forma
normale.
Conseguenze della ridondanza dei dati
•
dover digitare ripetutamente un informazione aumenta la
probabilità di errori “umani” quali gli errori di digitazione. Si pensi che se
invece di digitare Rossi si digita Rosi, quando si interroga il database
chiedendogli a quali gruppi partecipa “Rossi”, il dato scritto erroneamente
non viene selezionato e non entra nel computo dell’interrogazione proposta.
•
si presentano inoltre problemi di memoria. Le informazioni
duplicate occupano memoria senza che da questo ne nasca un beneficio.
Entità: Dati originali
Per risolvere i problemi dovuti alla ridondanza dei dati
viene in aiuto la Seconda forma normale la cui definizione è:
Un’entità risponde alla seconda forma normale
quando tutti i suoi attributi dipendono dalla
chiave primaria dell’entità.
Si ricorda che per poter applicare la seconda forma normale si deve aver già
applicato la prima forma normale
Nell’esempio si evidenzia una dipendenza parziale dalla chiave primaria.
Si noti infatti che per identificare univocamente ogni istanza (tupla o
ennupla) non esiste una chiave univoca “naturale” a meno che non si
prendano in considerazione un numero considerevole di attributi: Nome,
cognome, orario, a.a.
Ma le informazioni legate a nome e cognome (indirizzo, […]) non hanno
nessun legame con le informazioni relative al gruppo di esercitazione.
Viceversa le informazioni legate a orario e a.a. (tipo, front/auto, id_doc,
id_prog.) non hanno nessun legame con le informazioni relative ai
partecipanti al corso.
Per soddisfare la seconda forma normale, non rimane altra strada che
dividere i gruppi di informazione iniziando col dividere le informazioni dei
Partecipanti da quelle dei Dati originali
Dopo aver diviso le due entità è necessario definire il modello E/R (entità /
relazione).
In questo modo mantengo i collegamenti tra le informazioni esistenti in
natura, cioè nella realtà dei dati così come si presentano nelle schede
cartacee.
Se non predispongo i campi per le relazioni e cioè le chiavi primarie e le
chiavi secondarie, quando divido le informazioni perdo il legame che esiste
tra esse.
Che relazione esiste tra i partecipanti al corso e i Dati originali?
Si tratta di una relazione
1:M
- un partecipante può legarsi ad una o più informazioni dell’entità Dati
originali mentre ognuna delle informazioni archiviate nell’entità Dati originali
si riferisce ad un unico partecipante al corso.
Si procede quindi a stabilire le chiavi primarie e
secondarie
Analizzando le entità partecipanti al corso e Dati originali ci si rende conto
che mancando dei codici “naturali” adatti a fungere da chiave primaria
Si ricorda che la chiave primaria è un dato univoco (senza duplicati)
sempre presente che permetta di identificare una determinata informazione
e solo quella.
Si procede quindi ad utilizzare dei codici numerici identificatori (ID) per
l’identificazione univoca delle singole istanze nelle due entità:
•
•
ID partecipante nell’entità partecipanti al corso;
ID dati originali nell’entità Dati originali
Predispongo infine la chiave secondaria per rendere fattibile la relazione.
Inserisco cioè un attributo in grado di contenere il dato di collegamento delle
informazioni dei Dati originali con le informazioni in partecipanti al corso
Ecco come le informazioni si presentano
Se analizziamo ora le due entità si scopre che l’entità partecipanti al corso
risponde alla definizione della seconda forma normale ma che l’entità dati
originali non è ancora “normalizzata”.
Infatti nell’entità partecipanti al corso tutti gli attributi (indirizzo, data di
nascita, luogo di nascita, residenza ec.) sono legati alla chiave primaria che
è id_partecipante. Cioè un valore di Id_partecipante identifica uno studente
con tutte le informazioni che lo riguardano.
Nell’entità Dati originali non tutti gli attributi presenti si identificano con la
chiave primaria (id dati originali
Per esempio se si analizzano le informazioni contenute in orario o a.a. o tipo
si scopre che un corso che si tiene nell’orario 5 è di tipo seminario nell’a.a.
97/98 con lezioni frontali ed è tenuto dallo stesso docente che ha la
matricola 45, il quale svolge un programma che è archiviato con il codice 3.
Questo è valido sia per lo studente Rossi Mario (vd. prima riga dell’entità
dati originali) sia per lo studente Verdi Carlo (vd. terza riga dell’entità dati
originali) ed infine per lo studente Bianchi Maria (vd. settima riga dell’entità
dati originali).
Nell’entità dati originali, uno stesso corso risulta associato a più valori della
chiave primaria. Non è quindi rispettata la seconda forma normale
Per “normalizzare” l’entità si dovrà procedere con il dividere gli attributi
relativi ai gruppi da quelli relativi alla chiave primaria e al cod_partecipante.
Nel dividere le entità si procederà come nell’esempio relativo ai dati dei
partecipanti ai corsi.
Cioè si definirà il modello E/R (Entità / Relazione) per mantenere il legame
esistente tra i dati in natura.
E infine si procederà alla creazione delle chiavi
primarie ed esterne
e ne risulterà questo modello logico
Si noti come dopo aver posto da una parte i dati dei partecipanti dall’altra
quelli del gruppo, tra i due si è formata un’entità (Dati originali) composta
solamente dagli attributi che identificano le istanze dell’entità (ID dati
originali) e le due chiavi esterne (cod_part e cod_gruppo).
La formalizzazione delle relazioni che mettono in comunicazione i tre gruppi
di informazioni e ne stabilisce la natura identifica due relazioni:
•
•
partecipanti al corso - Dati originale
gruppi di esercitazioni - Dati originale
1:M
1:M
La formalizzazione delle relazioni che mettono in comunicazione i tre gruppi
di informazioni e ne stabilisce la natura identifica due relazioni:
•
•
partecipanti al corso - Dati originale
gruppi di esercitazioni - Dati originale
1:M
1:M
Nella parte di questo corso dedicata alla progettazione di un DataBase il
modello logico formalizzato tra i partecipanti e i gruppi di esercitazioni
evidenziava una relazione di tipo molti a molti.
Rispettando le regole di normalizzazione siamo giunti ad una
formalizzazione corretta di questo tipo di relazione
Per risolvere una relazione molti a molti in modo tale che il computer sia in
grado di accettarla si devono risolvere i legami esistenti tra le due entità in
una terza entità che si interpone tra le due spezzando la relazione molti a
molti in due relazioni di tipo uno a molti.
La terza entità utilizzata per esplicitare nel nostro esempio, i legami tra
partecipanti al corso e gruppi di esercitazioni contiene le sole chiavi esterne
legate alle chiavi primarie che univocamente identificano un partecipante e
un gruppo.
Le regole di normalizzazione aiutano a comprendere come la soluzione di
una relazione molti a molti nasca dall’esigenza di evitare le difficoltà che
proprio tali regole mettono in evidenza:
nel caso della prima forma normale una molteplicità di attributi contenenti il
medesimo tipo di informazioni con grandi difficoltà nell’interrogazione e nella
adattabilità futura del database;
nel caso della seconda forma normale una molteplicità di ripetizioni di
informazioni con problemi di errori di digitazione, occupazione dello spazio di
memoria e di interrogazione dei dati.
L’entità dati originali spiega il legame di uno studente e di un gruppo di
esercitazioni.
Non sempre questa entità è composta da due soli codici.
Analizzando la natura delle istanze (ad esempio l’istanza 1: partecipante 1 e
gruppo 1; oppure l’istanza 4: partecipante 2 gruppo 4) si scopre che
l’incontro dei codici identifica la frequenza ad un gruppo di esercitazioni di un
dato studente.
Tale entità, se lo si ritiene opportuno potrebbe contenere le informazioni
relative alla presenza in aula dello studente (percentuale di frequenza)
oppure il risultato di prove di verifica parziali o la partecipazione a seminari o
attività collegate a quel gruppo di esercitazione.
L'entità Dati originali può prendere il nome Frequenza ai corsi.
Dopo aver applicato la prima e la seconda si può passare all’applicazione
della Terza forma normale
la quale stabilisce che:
la dipendenza tra gli attributi deve essere basata sulla
chiave primaria e non su altri attributi.
Guardando al nostro esempio si nota una dipendenza indiretta alla chiave
primaria.
Nell’entità gruppi di esercitazione si nota che il tipo di esercitazione descritto
con gli attributi: tipo, frontale/autoistruzione non è legato alla chiave primaria
ID gruppo anche se l’informazione rimane legata (indirettamente) al gruppo
di esercitazione. La definizione della tipologia e del tipo di lezioni tenute non
dipende dall’istanza relativa al gruppo di esercitazioni.
Sarà più opportuno togliere gli attributi tipo, front/auto dall’entità gruppi di
esercitazioni e costruire un’entità tipo esercitazioni dove memorizzare
queste informazioni.
Ciò permetterà di evitare una molteplicità di ripetizioni di informazioni con
problemi di errori di digitazione, occupazione dello spazio di memoria e di
interrogazione dei dati
Eccone la formalizzazione
Si noti la creazione delle chiavi primarie e secondarie per la
fattibilità delle relazioni
Il modello logico iniziale si trasforma quindi nel modo
seguente
Le relazioni:
1:M
tabella originale
partecipanti al corso
1:M
risultati degli esami
gruppi di esercitazioni
1:M
tabella originale
tipo esercitazioni
1:M
gruppi di esercitazioni
docenti
1:M
gruppi di esercitazioni
programmi d’esame
1:M
gruppi di esercitazioni
partecipanti al corso