Architettura degli Elaboratori
Input / Output
M. Dominoni
A.A. 2003/2004
Input/Output
A.A. 2003/2004
1
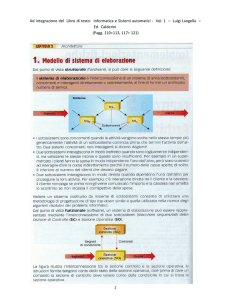
Struttura del Computer
• 4 componenti strutturali:
– CPU: controlla le operazioni
del computer
– Memoria Centrale:
immagazinamento dati e
codice
– I/O: muove dati tra il computer
e l’esterno
– Interconnesione del
sistema: qualche
meccanismo che permette la
comunicazione tra CPU,
Memoria e I/O
Input/Output
A.A. 2003/2004
2
1
Architettura degli Elaboratori
Input/Output
• Oltre ai componenti processore e memoria, il terzo
elemento chiave di un computer e’ un insieme di moduli
di I/O
• Ogni modulo e’ interconnesso con il processore e la
memoria e controlla uno o piu’ componenti esterni
• Il modulo I/O interagisce con il resto del computer per
mezzo delle tecniche di:
– I/O programmato
– I/O ad interrupt
– DMA - Direct Memomy Access
Input/Output
A.A. 2003/2004
3
Interfaccia tra Processore e Periferiche
• Design dello I/O influenzato da molti fattori (espandibilita’, affidabilita’)
• Prestazioni:
— latenza di accesso
— throughput
— connessione tra i dispositivi e il sistema
— gerarchia di memoria
— sistema operativo
• Una moltitudi di utenti diversi (ex: banche, supercomputer, fisici,…)
Processor
Interrupts
Cache
Memory– I/O bus
Main
memory
I/O
controller
Disk
Input/Output
Disk
I/O
controller
I/O
controller
Graphics
output
Network
A.A. 2003/2004
4
2
Architettura degli Elaboratori
Impatto dell’I/O sulle prestazioni del
sistema: Esempio
• Benchmark eseguito in 100 s:
– 90% CPU, 10% I/O
• Ogni anno prestazione CPU migliora del
50% mentre I/O non cambia
• Quanto migliora la prestazione del sistema
in 5 anni?
• Tempo di esecuzione = tempo CPU +
tempo I/O
Input/Output
A.A. 2003/2004
5
Esempio cont
Anno
CPU
I/O
Totale
I/O %
0
1
2
3
4
5
90 s
60 s (90/1.5)
40 s (60/1.5)
27 s (40/1.5)
18 s (27/1.5)
12 s (18/1.5)
10 s
10 s
10 s
10 s
10 s
10 s
100 s
70 s
50 s
37 s
28 s
22 s
10%
14%
20%
27%
36%
45%
•Miglioramento di prestazioni dopo 5 anni:
•CPU = 90/12 = 7.5
Input/Output
Sistema = 100/22 = 4.5
A.A. 2003/2004
6
3
Architettura degli Elaboratori
Tendenze tecnologiche
Capacita’
Velocita’ (latenza)
2x in 3 anni 2x in 3 anni
4x in 3 anni 2x in 10 anni
4x in 3 anni 2x in 10 anni
Logica:
DRAM:
Dischi:
anno
1980
1983
1986
1989
1992
1995
DRAM
Size
64 Kb
256 Kb
1 Mb
1000:1! 4 Mb
16 Mb
64 Mb
Input/Output
2:1!
Cycle Time
250 ns
220 ns
190 ns
165 ns
145 ns
120 ns
A.A. 2003/2004
7
Problema reale?
Differenza di prestazioni tra processore e DRAM (latenza)
Proc
60%/anno.
(2X/1.5anni)
1000
CPU
“Legge di Moore”
Processore-memoria
Performance Gap:
(cresce 50% / anno)
10
DRAM
DRAM
9%/anno.
(2X/10 anni)
2000
1998
1999
1997
1996
1995
1994
1993
1992
1991
1990
1989
1988
1987
1986
1985
1984
1982
1983
1981
1
1980
Prestazioni
100
Anno
Input/Output
A.A. 2003/2004
8
4
Architettura degli Elaboratori
Prestazioni di I/O
• Ampiezza di banda di I/O può essere
misurata in due modi differenti:
– Quanti dati possiamo muovere attraverso il
sistema in un certo tempo – data rate
– Quante operazioni di I/O possiamo fare per
unità di tempo – I/O rate
• Quale dei due modi sia quello giusto
dipende dalla particolare applicazione
Input/Output
A.A. 2003/2004
9
Prestazioni di I/O - Supercomputer
• Batch job (esecuzione in code)
• Pochi accessi a grossi file in lettura e
scrittura all’inizio e alla fine
• Durante l’esecuzione scittura di snapshot
per fissare lo stato di esecuzione a
quell’istante in caso di crash del sistema
• Misura di I/O = misura di throughput =
numero di byte per secondo trasferiti tra
memoria principale e dischi
Input/Output
A.A. 2003/2004
10
5
Architettura degli Elaboratori
Prestazioni di I/O - Transazioni
• Applicazioni di processi di transazione (TP)
coinvolgono sia:
– Tempo di risposta che prestazioni basate sul
troughput
– La maggior parte degli accessi di I/O sono piccoli
• Applicazioni TP sono misurate in numero di
accessi al disco per secondo
– I/O rate contrapposto al data rate precedente
• Benchmark usati: TPC-C e TPC-D
Input/Output
A.A. 2003/2004
11
I/O: Dispositivi
• Dispositivi molto diversi
–
–
–
comportamento (i.e., input vs. output)
partner (chi c’e’ dall’altro lato?)
data rate
Device
Keyboard
Mouse
Voice input
Scanner
Voice output
Line printer
Laser printer
Graphics display
Modem
Network/LAN
Floppy disk
Optical disk
Magnetic tape
Magnetic disk
Input/Output
Behavior
input
input
input
input
output
output
output
output
input or output
input or output
storage
storage
storage
storage
Partner
human
human
human
human
human
human
human
human
machine
machine
machine
machine
machine
machine
A.A. 2003/2004
Data rate (KB/sec)
0.01
0.02
0.02
400.00
0.60
1.00
200.00
60,000.00
2.00-8.00
500.00-6000.00
100.00
1000.00
2000.00
2000.00-10,000.00
12
6
Architettura degli Elaboratori
I/O Esempio: Dischi
• Per accedere ai dati:
— ricerca: posizionamento
della testina sopra la traccia
appropriata (8 to 20 ms -media)
— latenza di rotazione:
attesa per il settore desiderato
(.5 / RPM)
— trasferimento: portare i
dati (uno o piu’ settori) –
da 2 a 15 MB/sec
Input/Output
Platters
Tracks
Platter
Sectors
Track
A.A. 2003/2004
13
Esempio: tempo di lettura di un disco
• Determinare il tempo medio per leggere un
settore a 512 byte di un disco a 5.400 RPM
dove:
–
–
–
–
Tempo di ricerca medio = 12 ms
Transfer rate = 5MB/s
Controller overhead = 2 ms
Disco idle all’inizio del trasferimento
• Tempo medio di lettura = tempo di ricerca medio + latenza di
rotazione + tempo di trasferimento + controller overhead
• 12 ms + (0.5/5.400 RPM) + 0.5 KB/ 5MB/s + 2 ms =
12 ms +
5.6 ms
+
0.1 ms + 2 ms = 19.7 ms
Input/Output
A.A. 2003/2004
14
7
Architettura degli Elaboratori
BUS: Sistema di Interconnesione
• Un BUS e’ un canale di comunicazione che collega 2 o piu’
componenti: e’ un mezzo di trasmissione condiviso
• Piu’ componenti collegati al BUS: il segnale trasmesso da un
componente e’ disponibile per essere ricevuto da tutti gli altri
componenti collegati al bus
• Solo un componente alla volta puo’ trasmettere sul bus
• Bus costituito da un insieme separato di linee: le linee possono
essere classificate in tre gruppi funzionali:
– Linee dati
– Line di indirizzo
– Linee di controllo
Inoltre possono essere presenti linee di potenza per alimentare i moduli
connessi
Input/Output
A.A. 2003/2004
15
Esempio: operazione di input
C o n t r o l li n e s
M e m o ry
P ro c e s s o r
D a t a l in e s
D is k s
a.
C o n t r o l li n e s
M e m o ry
P ro c e s s o r
D a t a l in e s
b.
Input/Output
D is k s
A.A. 2003/2004
16
8
Architettura degli Elaboratori
Esempio: operazione di output
C o n tr o l lin e s
M e m o ry
P ro c e s s o r
D a t a l in e s
D is k s
a .
C o n tr o l lin e s
M e m o ry
P ro c e s s o r
D a t a l in e s
D is k s
b .
C o n tr o l lin e s
M e m o ry
P ro c e s s o r
D a t a l in e s
D is k s
c.
Input/Output
A.A. 2003/2004
17
Struttura del Bus - cont
• Linee dati: collettivamente sono chiamate
bus dati –
– Esempio:
• PCI:
– Ampiezza bus dati: 32 / 64 bit
• SCSI
– Ampiezza bus dati: 8-32 bit
Input/Output
A.A. 2003/2004
18
9
Architettura degli Elaboratori
Struttura del Bus – cont 2
• Linee di indirizzo: permettono di designare la sorgente e la
destinazione dei dati sul bus dati - puo’ essere usato il bus dati per
trasmettere l’indirizzo
• Linee di controllo: sono usate per controllare l’accesso e l’uso delle
linee dati e di indirizzo –
Tipiche linee di controllo includono:
–
–
–
–
–
–
–
–
–
–
–
Memory write
Memory read
I/O write
I/O read
Transfer ACK
Bus request
Bus grant
Interrupt Request
Interrupt ACK
Clock
Reset
Input/Output
A.A. 2003/2004
19
Struttura del Bus – cont 3
Backplane bus
Processor
•
Memory
Gerarchia di Bus
I/O devices
a.
Processor-memory bus
Processor
Memory
Bus
adapter
Bus
adapter
I/O
bus
Bus
adapter
I/O
bus
I/O
bus
b.
Processor-memory bus
Processor
Memory
Bus
adapter
Bus
adapter
I/O bus
Bus
adapter
I/O bus
Backplane
bus
c.
Input/Output
A.A. 2003/2004
20
10
Architettura degli Elaboratori
Struttura del Bus – cont 4
• Bus classificati in tre tipi:
– Bus processore–memoria:
• sono spesso specifici (proprietari)
• Sono corti, ad alta velocità
• Massimizzano l’ampiezza di banda tra cpu e mem
– Bus di I/O:
• Sono lunghi
• molti dispositivi attaccati
• Ampio intervallo di ampiezza di banda dei dispositivi
– Bus di backplane
– Questi due ultimi tipi di bus sono spesso standard
Input/Output
A.A. 2003/2004
21
Struttura del Bus – cont 5
• Bus Sincrono: include un clock nelle linee
di controllo ed un protocollo prestabilito
per la comunicazione
– Adatto per bus molto veloci
– due principali svantaggi:
• Tutti i device sul bus devono funzionare allo stesso
clock
• Se sono particolarmente veloci non possono
essere molto lunghi
– Esempio: bus processore- memoria
Input/Output
A.A. 2003/2004
22
11
Architettura degli Elaboratori
Struttura del Bus – cont 6
• Bus Asincrono:
– Puo’ accogliere una grande varieta’ di device (con clock diversi)
– Non ci sono problemi di lunghezza
• Per coordinare la trasmissione dei dati si usa un
protocollo di “handshaking”:
• Consiste in una serie di passi in cui sender e receiver
procedono al successivo passo solo se entrambe le parti
concordano
• Bus asincrono scala meglio con I cambiaenti tecnologici
e supporta una ampia varietà di dispositivi e velocità
• Bus di I/O sono spesso asincroni
Input/Output
A.A. 2003/2004
23
Struttura del Bus – cont 7
• Esempio di funzionamento del bus
asincrono:
ReadReq
1
3
Data
2
2
4
6
4
Ack
5
7
DataRdy
Input/Output
A.A. 2003/2004
24
12
Architettura degli Elaboratori
Bus sincrono: esempio
•
•
•
•
ciclo clock = 50 ns (20 MHz)
Ogni trasmissione richiede 1 ciclo di clock
Bus dati = 32 bit
Trovare l’ampiezza dati per una lettura di una
word da una memoria da 200 ns
1. Invio dell’indirizzo di memoria = 50 ns
2. Lettura della memoria = 200 ns
3. Invio dei dati al dispositivo = 50 ns
tempo totale = 300 ns
Ampiezza di banda = 4 byte/300 ns = 13.3 MB/s
Input/Output
A.A. 2003/2004
25
Bus asincrono: esempio
•
Handshake = 40 ns
– Step 1 = 40 ns
– Step 2, 3, 4 = max(3x40 ns , 200 ns)
– Step 5, 6, 7 = 3x40 ns
•
•
Tempo totale = 360 ns
Ampiezza di banda = 4 byte/ 360 ns =
11.1 MB/s
Input/Output
A.A. 2003/2004
26
13
Architettura degli Elaboratori
Bus - Sommario
• Link di comunicazione condivisa (una o piu’ linee)
• Difficolta’ di disegno:
— puo’ essere un collo di bottiglia
— lunghezza del bus
— numero dei dispositivi
— buffer per una maggiore ampiezza di banda aumentano la latenza
— connessione a dispositivi differenti
— costo
• Tipi di bus:
— processore-memoria (corto, alta velocita’, specifico)
— backplane (alta velocita’, spesso standard -> PCI)
— I/O (lungo, differenti dispositivi, standard -> SCSI)
• Sincrono vs. Asincrono
— uso di un clock e di un protocollo sincono, veloce e piccolo
ma ogni dispositivo deve operare alla stessa velocita’
— non si usa un clock -> invece si usa il protocollo di handshaking
Input/Output
A.A. 2003/2004
27
Accesso al Bus
• Bus master – slave
B u s re q u es t lin e s
M em o ry
P ro c e s s or
Bus
D is ks
a.
B u s re q u es t lin e s
M em o ry
P ro c e s s or
Bus
D is ks
b.
B u s re q u es t lin e s
M em o ry
P ro c e s s or
Bus
c.
Input/Output
D is ks
A.A. 2003/2004
28
14
Architettura degli Elaboratori
Bus Arbitration
• Bus Arbitration: decidere quale bus master
puo’ iniziare ad usare il bus
• Gli schemi di arbitrato devono bilanciare
due fattori nel decidere quale device ha
accesso al bus:
– Priorita’ sul bus: I device con maggiore
priorita’ devono potere accedere prima al bus
– Ogni device sul bus deve potere accedere
Input/Output
A.A. 2003/2004
29
Bus Arbitration – cont 2
• Arbitrato si puo’ dividere in quattro classi
generali:
• Arbitrato centralizzato, parallelo: esempio bus
PCI
un arbitro centralizzato sceglie tra I device che
devono accedere al bus e notifica al prescelto
che e’ stato nominato bus master –
Lo svantaggio e’ che richiede un arbitro
centralizzato che puo’ divenire il collo di bottiglia
Input/Output
A.A. 2003/2004
30
15
Architettura degli Elaboratori
Bus Arbitration – cont 3
• Daisy Chain:
– Vantaggio semplicita’
– Svantaggio: non assicura l’accesso a tutti
Highest priority
Device 1
Lowest priority
Device 2
Grant
Bus
arbiter
Grant
Device n
Grant
Release
Request
Input/Output
A.A. 2003/2004
31
Bus Arbitration – cont 4
• Arbitrato distribuito per auto-selezione: tutti device sul
bus inviano una richiesta di accesso indicando la relativa
priorita’: non c’e’ bisogno di un arbitro centralizzato –
esempio NuBus su Apple Macintosh II
• Arbitrato distribuito per analisi di collisione: ogni device
sul bus richiede accesso – multiple richieste simultanee
generano collisione – Ethernet usa questo schema
Input/Output
A.A. 2003/2004
32
16
Architettura degli Elaboratori
Punti Importanti
• Bus Arbitration:
– daisy chain
– Arbitrato centralizzato (richiede un arbitro) => PCI
– Auto-selezione => NuBus usato in Macintosh
– collision detection => Ethernet
• Sistema operativo:
– Polling
– Interrupt
– DMA
Input/Output
A.A. 2003/2004
33
CPU vs I/O
• CPU deve inviare un comando ad un
dispositivo di I/O
• ci sono due metodi di indirizzamento
– Memory mapped I/O
– I/O isolato
• Alternativa all’I/O memory mapped e’ l’uso dedicato
di istruzioni di I/O nel processore
• specificano sia il dispositivo che il comando
Input/Output
A.A. 2003/2004
34
17
Architettura degli Elaboratori
Memory mapped I/O
• una porzione dello spazio di indirizzamento e’ assegnata
ai dispositivi di I/O
• l’accesso al dispositivo di I/O avviene in maniera
analoga all’accesso in memori
– Esempio: operazione di scrittura puo’ essere usata per per
inviare dati al dispositivo di I/O che saranno interpretati come
comandi – il sistema di memoria ignora l’operazione perche’
l’indirizzo indica una porzione dello spazio di memoria dedicata
all’I/O. Il controllore del dispositivo vede la richiesta, registra i
dati che invia al dispositivo come comandi.
• L’indirizzo codifica sia l’identità del dispositivo che il tipo
di trasmissione tra CPU e dispositivo stesso.
Input/Output
A.A. 2003/2004
35
Schema a Blocchi di un dispositivo esterno
Input/Output
A.A. 2003/2004
36
18
Architettura degli Elaboratori
Schema a blocchi di un modulo di I/O
Input/Output
A.A. 2003/2004
37
I/O -1
• Tre tecniche possibili per le operazioni di
I/O:
– I/O Programmato
– I/O ad Interrupt
– Direct Memory Access (DMA)
Input/Output
A.A. 2003/2004
38
19
Architettura degli Elaboratori
I/O Programmato
• Dati sono scambiati tra la CPU e il modulo I/O
• CPU esegue un programma che le assegna il controllo diretto sulla
operazione di I/O:
– Stato del dispositivo
– Read e Write command
– Trasferimento di dati
• Polling: e’ il modo piu’ semplice con cui il device comunica con il
processore – I/O device mette le informazioni in uno registro di stato
e il processore deve venire ad ottenere l’informazione
• Il controllo e’ completamente del processore
• Lo svantaggio di questa tecnica e’ quello di sprecare un gran numero
di cicli del processore: CPU e’ molto piu’ veloce delle periferiche di
I/O
Input/Output
A.A. 2003/2004
39
I/O programmato – cont 2
• CPU a 500MHz
• Numero di cicli per operazione di polling 400
– Mouse: campionato 30 volte al secondo
– cicli di clock per secondo per polling=30x400=12.000
– Frazione di cicli di clock consumata: 12K/500M=0,002%
– Floppy che trasferisce dati in unita’ di 16 bit a 50kB/s
Frazione del processore consumata=2%
– Disco che trasferisce a 4MB/s
Frazione del processore consumata=20%
Input/Output
A.A. 2003/2004
40
20
Architettura degli Elaboratori
Ciclo di istruzione con Interrupt
Input/Output
A.A. 2003/2004
41
I/O ad interrupt
• CPU trasmette il comando al modulo di I/O e passa a fare altro
• Il modulo I/O interrompe la CPU con una richiesta di servizio quando
e’ pronto a scambiare I dati
• La CPU esegue il trasferimento di dati e ritorna ai processi in corso
• I/O ad interrupt e’ piu’ efficiente di quello programmato: elimina la
necessita’ dell’attesa della CPU.
• E’ comunque un metodo che consuma ancora molta CPU: ogni word
di dati che e’ trasferita dalla memoria al modulo di I/O e viceversa
deve passare attraverso la CPU
Input/Output
A.A. 2003/2004
42
21
Architettura degli Elaboratori
I/O ad interrupt – cont 2
• CPU a 500MHz
• Numero di cicli per operazione di
trasferimento 500
• Disco trasferisce dati solo per il 5% del
tempo
Disco che trasferisce a 4MB/s
Frazione del processore consumata durante un
trasferimento =25%
Frazione del processore consumata in media 5%
Input/Output
A.A. 2003/2004
I/O ad Interrupt: design
•
•
43
1
Ci sono più moduli I/O: come fa la CPU a
determinare quale device ha alzato l’interrupt?
Ci sono quattro tecniche:
1.
2.
3.
4.
Input/Output
Linee di Interrupt multiple
Software poll
Daisy Chain (hardware poll, vettorizzato)
Bus arbitration (vettorizzato)
A.A. 2003/2004
44
22
Architettura degli Elaboratori
I/O ad Interrupt: design
1.
1
Linee di Interrupt multiple
–
–
2.
Tra CPU e moduli di I/O
Problema: non è pratico dedicare più che poche line del bus o
pin della CPU a linee di Interrupt – è probabile che su
ciascuna linea ci siano più moduli di I/O
Software poll
–
–
CPU intercetta un Interrupt
Attiva le routine di servizio di interrupt: viene contattato ogni
modulo di I/O per determinare chi ha alzato l’Interrupt
Problema: è “time consuming”
–
Input/Output
A.A. 2003/2004
45
Interrupt vettorizzato - design 2
3.
Daisy Chain (hardware poll, vettorizzato)
–
–
–
–
Fornisce un efficiente hardware poll (vedi fig. precedente – pg.31)
Tutti i moduli I/O condividono la medesima line di Interrupt
Quando la CPU sente una richiesta di Interrupt, invia un ACK
Il modulo che ha alzato l’Interrupt intercetta l’ACK e risponde mettendo una
word sulle linee dati
Word – detta vettore – contiene o l’indirizzo del modulo I/O o qualche
elemento di identificazione univoco – usato dalla CPU per avviare le
appropriate routine di servizio proprie del dispositivo
Evitato l’uso intermedio di una routine di servizio generica
Tecnica chiamata di Interrupt vettorizzato
Problema: e’ possibile che i dispostivi di I/O con priorità più bassa non
riescano mai ad essere serviti dalla CPU
–
–
–
–
4.
Bus arbitration (vettorizzato)
–
–
–
–
Input/Output
Modulo I/O deve prima ottenere il controllo del bus prima di potere alzare la
linea di Interrupt
Solo un modulo alla volta può alzare l’Interrupt
CPU risponde con ACK –
Modulo pone il suo vettore sulle linee dati
A.A. 2003/2004
46
23
Architettura degli Elaboratori
DMA
• DMA coinvolge un modulo aggiuntivo sul bus di systema
• Il modulo DMA e’ in grado di riprodurre il comportamento della CPU
al riguardo – riceve il controllo del sistema dalla CPU
• Quando la CPU vuole leggere o scrivere un blocco di dati invia una
istanza al modulo DMA con le seguenti informazioni:
– Se write o read
– Indirizzo del dispositivo I/O coinvolto
– Locazione iniziale della memoria su cui fare read/write
– Numero di word da leggere/scrivere
• Quando il trasferimento e’ completo il modulo DMA invia un segnale
di interrupt alla CPU
• LA CPU E’ COINVOLTA SOLO ALL’INIZIO E ALLA FINE DEL
TRASFERIMENTO
Input/Output
DMA
Input/Output
A.A. 2003/2004
47
- schema a blocchi
A.A. 2003/2004
48
24
Architettura degli Elaboratori
DMA: Configurazioni Alternative
Input/Output
A.A. 2003/2004
49
DMA: overhead
• Stesso disco e processore degli esempi precedenti
• CPU:
500MHz
• Ipotesi:
– Setup iniziale del DMA = 1000 cicli clock CPU
– Completamento = 500 ciclo clock CPU
• Transfer rate: 4MB/s
• Per ogni trasferimento di 8KB
– dura 8KB/4MB s = 2 ms
• Trasferimento DMA:
– [(1000+500)x clock cycle/trasf] / [2ms/trasf] = 750 x 103 clock cycle/ s
• Frazione processore consumata= 750 K/ 500 M = 0,2 %
Input/Output
A.A. 2003/2004
50
25
Architettura degli Elaboratori
Le tre tecniche a confronto
Input/Output
A.A. 2003/2004
51
26