Lezione 1 - I primi linguaggi: basso livello
Corso — Programmazione
Linguaggi di programmazione— Storia della programmazione
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Il primo linguaggio teorico
• Charles Babbage è stato il matematico e filosofo
britannico, che per primo ebbe l'idea di un calcolatore
programmabile (macchina differenziale e macchina
analitica)
• Ada Lovelace, discepola e collaboratrice di Babbage,
definì il primo linguaggio di programmazione (1837).
• Era un linguaggio di tipo assemblativo, ma lavorava su
una macchina teorica
• Introdusse il concetto di ciclo ripetuto e il concetto di
variabile indice.
• La realizzazione della macchina analitica non fu mai
portata a termine.
Primi calcolatori (1)
• Lo Z3 è il primo calcolatore totalmente programmabile e
totalmente automatico (ideato dall'ingegnere tedesco
Konrad Zuse) (1941)
• Nel 1998 è stato dimostrato che lo Z3 è Turing completo (
stesso potere computazionale di una macchina di Turing
universale)
• Zuse fu il primo programmatore della storia ad agire su
una macchina realmente programmabile
• Lo Z3 fu utilizzava il codice binario
• Utilizzava una tecnologia Elettromeccanica
• Atanasoff-Berry Computer (ABC) completamente
elettronico
• Non era Turing completa
• Elaborazione e memorizzazione separati
Primi calcolatori (2)
• Electronic Numerical Integrator and Computer
• Il primo computer elettronico general purpose della storia
• Costruito dal 1943 al 1945
• Programmazione definita da circuiti elettrici
• L'ENIAC era decimale mentre lo Z3 era già binario.
• Programmare l'ENIAC voleva dire riscrivere il programma
mentre lo Z3 poteva caricarlo da nastro perforato.
• Tutti gli attuali computer hanno un disegno progettuale
che ricorda più lo Z3 che l'ENIAC.
• La macchina non aveva un programma registrato: sei
donne erano impegnate a muovere commutatori e
connettere cavi.
Linguaggio di programmazione concreto
• Konrad Zuse, sviluppò il Plankalkül (1943 1945 ).
• Sviluppò il linguaggio mentre se ne stava nascosto sulle
Alpi della Baviera in attesa della fine della Seconda Guerra
Mondiale.
• Usò il suo linguaggio come opponente nel gioco degli
scacchi sul suo computer Z3.
• Il linguaggio era già in grado di gestire sia tabelle che
strutture di dati.
• Il Plankalkül rimase seppellito in qualche archivio in
Germania per molto tempo.
Linguaggio macchina(1)
• Una sequenza di bit. LOAD 8 potrà essere rappresentata
in una macchina reale come 00110100, dove 0011 è la
rappresentazione interna del codice operativo LOAD
• I linguaggi di programmazione coincidevano con l'insieme
delle istruzioni eseguibili dall'hardware.
• Enorme sforzo richiesto per codificare algoritmi semplici.
Linguaggio macchina(2)
• Sono specifici della macchina.
• Ogni CPU ha il proprio linguaggio macchina.
• Occorre conoscere l architettura della macchina per
scrivere programmi.
• I programmi non sono portabili.
• I codici sono illeggibili all' uomo.
• I programmatori si specializzano nel cercare efficienza su
una macchina specifica, anziché concentrarsi sul
problema.
Linguaggio assembly
• Codifica di tipo simbolico, anziché binaria, dei programmi:
è meglio risparmiare il tempo dell'uomo anche a costo di
sprecare tempo macchina (una parte del tempo è dedicata
alla traduzione di programmi, non alla loro esecuzione
diretta)
• In assembly ogni istruzione è identificata da una sigla
piuttosto che da un numero e le variabili sono
rappresentate da nomi piuttosto che da numeri.
• I programmi scritti in assembly necessitano di un apposito
programma assemblatore per tradurre le istruzioni tipiche
del linguaggio in istruzioni macchina.
• Oggi si utilizza l' assembly solo se esistono vincoli
stringenti sui tempi di esecuzione.
Lezione 2 - I primi linguaggi: alto livello
Corso — Programmazione
Linguaggi di programmazione— Storia della programmazione
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Linguaggi ad alto livello
• Tra gli anni 50 e 60 si passo ai linguaggi ad alto livello,
anche se qualche concetto era già stato introdotto prima
• Si tratta di un passaggio stabilito da un maggior uso di tali
linguaggi
• Essi richiedono un compilatore o un interprete che sia in
grado di tradurre le istruzioni del linguaggio di alto livello
in istruzioni macchina di basso livello le uniche eseguibili
dal calcolatore
• Compilatori ed interpreti sono di gran lunga più complessi
di un assemblatore
FORTRAN
• Il FORmula TRANslator è stato sviluppato da un gruppo di
programmatori della IBM guidati da John Backus e
pubblicato per la prima volta nel 1957.
• Era stato progettato per facilitare la traduzione in codice
di formule matematiche.
• Data la sua semplicità di scrittura i programmatori
riuscivano ad essere fino a 500 volte più veloci in
FORTRAN che in altri linguaggi. E stato il primo linguaggio
``problem oriented'' anziché ``machine oriented''.
COBOL
• Sviluppato nel 1959 da un gruppo di professionisti riuniti
alla Conference on Data Systems Languages (CODASYL).
• Da allora ha avuto molte modifiche e miglioramenti. Nel
tentativo di superare le numerose incompatibilità tra le
varie versioni, l'American National Standards Institute
(ANSI) annunciò uno standard nel 1968, che produsse
l'ASN-COBOL.
• Il linguaggio continua ad evolversi ancora oggi, che è
disponibile in una versione object-oriented inclusa nel
COBOL 2002
LISP
• Nel 1958 John McCarthy fu incaricato di creare una lista di
specifiche per creare l'elaborazione simbolica.
• Il List Processing Language fu integrato come estensione
nel FORTRAN stesso.
• LISP segue i paradigma funzionale
• Un programma LISP può modificare se stesso crescendo
• Sia i dati sia i programmi sono delle liste. Per questo
motivo un programma in LISP può trattare altri
programmi al suo interno.
• E utilizzato nello studio della intelligenza artificiale.
Contiene il concetto di Garbage Collector
Linguaggi degli anni 60
• Algol - ALGOrithmic Language
Primo linguaggio con una sintassi formalmente definita
(BNF)
Primo linguaggio basato sui principi della programmazione
strutturata
Evoluzione: Algol 58, 60 e 68, parente del C e del PASCAL
Introdusse concetti fondamentali come il
record di attivazione
• BCPL Basic Combined Programming Language erede
di CPL mai decollato e progenitore di B e quindi anche di C
• Simula-67
Introduce il concetto di classe e oggetto
E' il progenitore del Java e di tutti i linguaggi orientati agli
oggetti
Linguaggi degli anni 70
• Pascal
Sviluppato per l' insegnamento
Ha avuto un grande successo anche nel mondo dell'
industria
Ha visto svilupparsi di versioni visuali (Delphi)
• Prolog
Introduce la programmazione logica
Si basa sul calcolo dei predicati del primo ordine
• Smalltalk
Prime interfacce grafiche
Object Oriented
• C
Concepito inizialmente come una sorta di assembler
strutturato
E diventato il linguaggio più affermato nella
programmazione di sistema
Linguaggi degli anni 80
• Ada
Omaggio alla prima programmatrice
ADA doveva rappresentare il punto di maturazione perfetta
di tutti i principi di costruzione del software e dei relativi
meccanismi linguistici elaborati negli anni precedenti.
• C++
Uno dei più usati linguaggi Object Oriented fino all'avvento
di Java
E' un'estensione del C, sviluppato da Bjarne Stroustrup
presso i Bell Laboratories.
Linguaggio Basic
• Evoluzione del Basic
Sviluppato nel 1964 presso l'Università di Dartmouth
Fu progettato per essere un linguaggio semplice da
imparare, nacque come linguaggio per principianti
Originariamente progettato come linguaggio compilato,
molte delle sue versioni più note sono interpretate
Una delle più famose versioni è il Microsoft BASIC,
sviluppato da Bill Gates, Monte Davidoff e Paul Allen
Il BASIC ha subito notevoli evoluzioni e cambiamenti,
diventando un linguaggio strutturato con potenzialità molto
simili a quelle di altri linguaggi più evoluti (e.g. Visual
Basic)
Nonostante le carenze si diffuse molto grazie ai personal
computer (Comodore64 basic, Atari e Amiga basic ecc.)
Basic versioni
• Non strutturato
10 LET C = A2 * A3 - A2
15 IF C = 0 THEN 55
20 READ D1, D2
• Strutturato
DO
INPUT Inserisci un numero , Num
LOOP WHILE num > 0
• A oggetti
PUBLIC SUB Button1Click()
DIM Num, Name AS String
IF TextBox1.Text <> `` THEN
Name = TextBox1.Text
ENDIF
END
Lezione 3 - Linguaggi attuali
Corso — Programmazione
Linguaggi di programmazione— Storia della programmazione
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Linguaggi degli anni 90
• Il linguaggio Java è derivato da un linguaggio chiamato
OAK, che fu sviluppato nei primi anni '90 alla Sun
Microsystem come linguaggio piattaforma indipendente
predisposto per applicazioni di intrattenimento come
console per video game e VCR per comunicazioni.
• OAK fu impiegato per la TV via cavo, per ordinare i
programmi da vedere.
• Mentre quel tipo di spettacolo on-demand tramontava, il
World Wide Web, invece, riscontrava sempre più interesse.
A quel punto i tecnici sviluppatori di OAK ci si buttarono a
capofitto, trasformando il programma OAK nel nuovo Java.
Java
• J. Gosling e A. Van Hoof si trovavano spesso ad un caffè
presso il quale discutevano del linguaggio stesso. E così il
linguaggio prese il nome da tale abitudine (Java è una
qualità di caffè dell'omonima isola dell'Indonesia).
• Il magic number che identifica un file .class è 0xCAFEBABE
(probabilmente riferendosi alla cameriera che li serviva).
C#
• La Microsoft propose alla Sun un accordo per apportare
modifiche al linguaggio, la Sun rifiuta, allora Microsoft
dichiara guerra alla Sun sviluppando il linguaggio C#
(siamo nel 2000), sviluppato sulla base di JAVA (ovvero
java con le modifiche che Microsoft aveva proposto alla
Sun che rifiutò)
Linguaggi di scripting
• Sono dei linguaggi di programmazione interpretati,
destinati in genere a compiti di automazione del sistema
operativo, lavori batch o usato per programmazione web
• La vera evoluzione si ebbe con l'introduzione del Common
Gateway Interface (CGI)
• Il CGI permise ai linguaggi di scripting di controllare i web
server per generare web dinamico
• Linguaggi famosi per questi scopi sono PHP, JSP e ASP,
Ruby e Python
• Perl iniziò come linguaggio di script ma poi si evolse in un
linguaggio adatto a coprire problematiche più ampie
Conclusioni unità
• In questa unità abbiamo visto rapidamente la storia della
programmazione fino quasi ai giorni nostri
• Abbiamo ripercorso una strada già vista nelle scorse
lezioni attraverso l'approccio evoluzionistico adottato nel
corso
• Da notare come concetti ad oggi affermati siano nati
molto tempo prima ma abbiano richiesto molto tempo per
concretizzarsi in un linguaggio effettivamente utilizzato
dalla massa dei programmatori
• L'evoluzione è un processo lento ma inesorabile e pilotato
dalle necessità
Lezione 1 - Introduzione
Corso — Programmazione
Linguaggi di programmazione— Compilatori ed interpreti
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
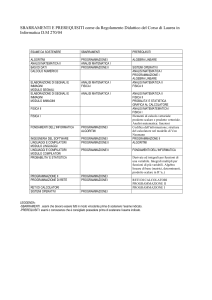
Traduttori(1)
• La macchina astratta per la quale è scritto un programma
ad alto livello viene implementata sulla macchina reale
attraverso un traduttore
• Esistono 3 tipologie di traduttori: Compilatori, Interpreti,
Traduttori ibridi
• Compilatore: È un programma che traduce un
programma scritto in linguaggio ad alto livello in un
programma equivalente nel linguaggio macchina (della
macchina dove verrà eseguito)
Traduttori(2)
• Interprete: È un programma che simula direttamente la
macchina astratta sulla macchina concreta attraverso i
seguenti passi alcuni dei quali in comune con un
compilatore:
1. Verifica correttezza sintattica
2. Effettua la traduzione
3. Esegue il codice tradotto
Libro consigliato per approfondimenti: Compilers Principles, Techniques, and tools
Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman
Discende dal famosissimo libro chiamato Dragon book: Principles of Compiler Design
(difficile da reperire)
Compilatori (1)
• Genericamente traducono da un linguaggio ad un altro e
si occupano di controllare eventuali errori nel linguaggio
sorgente rispetto alla sua grammatica
• Quasi sempre traducono i programmi (sorgente) in
codice macchina specifico per una determinata
architettura hardware (oggetto)
• L'oggetto viene poi assemblato con altre funzioni di
libreria, o altri programmi, utilizzate dal programma
stesso tramite un linker formando l' eseguibile
Compilatori (2)
• Un programma per essere eseguito deve essere caricato
in memoria, il loader, si occupa del caricamento
• Abbiamo visto come è definito lo spazio di memoria
allocato al programma nel momento che viene eseguito
(dipende dal S.O.)
• La compilazione non genera obbligatoriamente il
linguaggio macchina della macchina ospite
(cross-compilatori)
• La cross-compilazione permette di creare eseguibili per
una piattaforma non dotata di un compilatore installato
• Esistono moltissimi tipi di compilatori (singolo passo, multi
passo...) nonostante questo i mattoni base son sempre gli
stessi
Compilatori (3)
Interpreti (1)
• Gli interpreti devono essere sempre attivi durante
l'esecuzione del programma principale
• Precisamente l'interprete è l'unico programma in
esecuzione, ed esegue il programma interpretato
• Esistono due tipologie di interpreti:
Machine Interpreters: simulano l'esecuzione di un
programma compilato per una particolare architettura es
Java usa un interprete bytecode e la Java Virtual Machine
(JVM)
Language Interpreters: simulano l'effetto
dell'esecuzione di un programma (senza compilarlo) scritto
per un particolare set di istruzioni. Una forma di
Intermediate Representation (IR), per esempio un AST
viene utilizzato per l'esecuzione es Ruby
Interpreti (2)
Vantaggi:
• Fase di debug (interattivo) facilitata permettendo
l'aggiunta o modifica di codice durante l'esecuzione
• Gli interpreti supportano a pieno l'indipendenza dalla
macchina
Svantaggi:
• Non si può ottimizzare il codice
• Esecuzione molto lenta
• Il tempo di startup ingombrante soprattutto per piccoli
programmi
• Sostanziale overhead di spazio
• Gli interpreti sono sfruttati prevalentemente per il debug e
lo sviluppo del programma, mentre e i compilatori per la
produzione dell'applicazione.
Interpreti (3)
• Le fasi di un interprete possono essere mappate sulle fasi
relative ad un parser che produca un output in formato
intermedio eseguibile dall'interprete
• Parsing: Analisi lessicale, sintattica e trasformazione in
rappresentazione intermedia spesso come albero AST.
• Esecuzione: La rappresentazione intermedia viene
eseguita in accordo con la semantica del linguaggio
• Esistono interpreti per un linguaggio scritti in un altro
linguaggio es Lispy (lisp interpretato con Python)
Traduttori ibridi
• Alcune versioni di Lisp permettono l'esecuzione di
programmi parzialmente interpretati e compilati
• Un approccio ancora più interessante è quello che sfrutta
il bytecode es. Java.
• E' un linguaggio macchina che però non è fruibile
direttamente dal processore, ma deve essere interpretato
dalla Java Virtual Machine (JVM), la quale non è altro che
un ulteriore strato di software che si interpone tra la
macchina reale ed il programma.
• Questo rende quindi il programma indipendente dal
processore (molto utile per il deploy su cellulari purchè
dotati di una JVM compatibile)
Compilazione ed interpretazione in
RAPTOR(1)
• RAPTOR permette di eseguire il flow chart del progetto in
due modalità
• Interpretazione: modalità nella quale le singole istruzioni
vengono interpretate blocco per blocco. Utile per il debug
e per i primi programmi semplici
• Compilazione: il flow chart viene pseudo-compilato e può
essere eseguito all'interno di raptor in maniera più
performante. Le performance derivano soprattutto dal
fatto che non viene più gestita la visualizzazione del flusso
del flow chart, ma viene direttamente eseguito
Compilazione ed interpretazione in
RAPTOR(2)
• RAPTOR permette anche di fare il packaging delle
applicazioni nella modalità standalone. In tale modalità
viene generato un eseguibile del programma associato
alle librerie di raptor basilari per la sua esecuzione.
Conclusioni
• Un programmatore deve sapere bene come funziona il
traduttore del linguaggio che utilizza
• Agli albori era fondamentale per poter scrivere codice
ottimizzato
• Ad oggi meno determinante per l'ottimizzazione dato che i
traduttori possono ottimizzare il codice
• Fondamentale comunque per capire il meccanismo delle
librerie, la portabilità del codice
• Interessante applicazione di tecniche di programmazione
evolute
• Steve Yegge: <<If you don't know how compilers work,
then you don't know how computers work>>
Lezione 2 - Compilatori parte I
Corso — Programmazione
Linguaggi di programmazione— Compilatori ed interpreti
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Compilatori
• Il compilatore è esso stesso un programma (i primi furono
scritti in assembler)
• I compilatori Pascal e C sono detti auto-compilanti perchè
furono scritti negli stessi linguaggi (Il primo compilatore
auto-compilato, fu creato per il linguaggio Lisp da Hart e
Levin 1962)
• Ovviamente il primo compilatore di quel linguaggio deve
essere per forza scritto in un altro linguaggio (problema
del bootstrapping) oppure compilato facendo operare il
compilatore come un interprete
• Storicamente furono scritti con grandi ``ottimizzazioni''
date le limitate capacità dei calcolatori
• I compilatori consentono ai programmatori di ignorare i
dettagli machine-dependent della programmazione
(compilatori visti come delle black-box)
Compilatori: obiettivi
• Correttezza (errori ortografici e logici) e Sicurezza (Java
Bytecode Verifier)
• Protezione della proprietà intellettuale (parziale se non
espressamente offuscati)
• Efficienza
• Supportare l'espressività del linguaggio
• Offrire un ``ambiente di programmazione''
• Consentono indirettamente di sfruttare le opportunità
offerte dai dettagli architetturali di basso livello: Scelta
delle istruzioni, Metodi di indirizzamento, Pipelines, Uso
della cache, Parallelismo a livello di istruzione
I compilatori sono necessari per coprire il gap tra i linguaggi di alto livello e quelli di
basso
Sistema di processazione del linguaggio
Struttura di un compilatore(1)
• Ci sono due fasi fondamentali in un compilatore: Analisi e
Sintesi
• Analisi: viene spezzato il sorgente nei suoi pezzi
costituenti e creata una rappresentazione intermedia del
programma sorgente attraverso analisi Lessicale,
Sintattica, Semantica ed un
Generatore di codice intermedio.
• Sintesi: viene creato, partendo dalla rappresentazione
intermedia, il programma target equivalente attraverso il
generatore di codice e l' ottimizzatore.
Struttura di un compilatore(2)
Struttura di un compilatore(3)
• Due attività vengono utilizzate in quasi tutte le fasi
appena viste e questi sono:
• Symbol table: Una funzione essenziale di un compilatore
è quella di registrare gli identificatori usati e i loro
attributi. Si tratta di una struttura dati contenente un
record per ogni identificatore con i relativi attributi. La
fase lessicale individua le entry della tabella ma non gli
attributi che vengono definiti nelle fasi successive. Gli
attributi vengono usati in fasi come l'analisi semantica e la
generazione del codice intermedio.
• Gli attributi della symble table vengono aggiornati durante
i vari passaggi
Struttura di un compilatore(4)
• Error Handler: In ogni fase possono capitare errori che
devono essere gestiti per evitare che ad esempio si
termini la fase di compilazione troppo frettolosamente. Gli
errori sono soprattutto gestiti dalle fasi sintattiche e
semantiche.
Lessicale: valuta se i token appartengono al linguaggio.
Sintattica valuta se le stringhe di token validi violano le
regole strutturali del linguaggio.
Semantica valuta se le strutture sintatticamente corrette
hanno un significato valido per gli operatori coinvolti
Programmi a supporto (1)
• Preprocessore: Genera l'input per il compilatore
Processa le macro
Inclusioni di file esterni
Preprocessatori razionali che aggiungono a vecchi linguaggi
non ben strutturati, costrutti per il controllo di flusso più
attuali attraverso macro specifiche non appartenenti al
linguaggio
Estensioni al linguaggio che permettono di aggiungere
capacità al linguaggio attraverso macro
Programmi a supporto (2)
• Assemblatore: Alcuni compilatori generano codice
assembler che viene quindi passato ad un assemblatore
per la generazione di codice macchina rilocabile da
passare al linker/loader
Primo passo: trovo tutti gli identificatori che indicano una
locazione di storage e li inserisco in una symble table (non
la stessa del compilatore) indicando anche la locazione
Secondo passo: rifaccio la scansione e trasformo le
operazioni nella sequenza di bit relativa che rappresenta
l'operazione nel linguaggio macchina usando anche le
locazioni della symble table trasformate in indirizzi
Programmi a supporto (3)
• Loader e linker: Agisce sul codice rilocabile associandolo
ad un area di memoria usando un indirizzo di base o
modificando gli indirizzi relativi nel codice macchina.
• Il linker permette di associare più codici macchina in un
unico programma. Per far questo occorre tener traccia dei
riferimenti esterni
• I riferimenti esterni vengono risolti nelle chiamate corrette
Front end Back end
• Le fasi possono anche essere logicamente raggruppate nel
momento in cui si vuole sviluppare un compilatore:
• Front end: include fasi lessicale, sintattica, creazione
della symble table, semantica, generazione del codice
intermedio (anche una parziale ottimizzazione a volte),
error handling che riguarda queste fasi
• Back end: tutta la parte specifica della macchina target e
che non dipende dal linguaggio di programmazione ma dal
linguaggio intermedio. Ottimizzazione specifica,
generazione del codice, symble table e error handling di
queste fasi
• Cross compilazione: stesso front end ma back end
specifici
• Front end multipli per la stessa macchina (non molto
successo date le differenze tra linguaggi)
Classificazione di un compilatore (1)
• Numero di passi: compilatori a singolo passo compilatori a più passi
• Ottimizzazione: di tempo spazio e potenza dissipata
• Linguaggio oggetto prodotto
Pure machine code: generato senza assumere la
presenza di un particolare sistema operativo o libreria di
funzioni
Classificazione di un compilatore (2)
• Augmented machine code: generato per un particolare
set di istruzioni macchina arricchito considerando la
presenza di un sistema operativo o di una collezione di
routine di supporto ad esempio all' I/O e per l' allocazione
di memoria. Differenza tra codice virtuale generato e
hardware
• Virtual machine code: composto esclusivamente da
codice virtuale, permette di generare codice eseguibile
indipendente dall'hardware.
Un compilatore ``Just in Time'' (JIT) può tradurre porzioni di virtual code in codice
nativo per velocizzare l'esecuzione.
Classificazione di un compilatore (3)
• Formato target prodotto:
Assembly Language: viene prodotto un file di testo
contenente il codice sorgente assembler. Alcune decisioni
di generazione vengono lasciate all'assemblatore (symbolic
format). Il fatto che si generi codice assemply semplifica il
dubug e la comprendione di come funziona un copilatore
(approccio didattico)
Relocatable Binary Format: il codice può essere
generato in un formato binario con riferimenti esterni e con
gli indirizzi dei dati non ancora soggetti a vincoli. La
determinazione degli indirizzi avviene rispetto all'indirizzo
di base dell'oggetto o rispetto ad una unità denominata
simbolicamente. Il linker consente di aggiungere le librerie
di supporto e altre routine compilate separatamente
producendo un formato binario assoluto ed eseguibile del
programma.
Classificazione di un compilatore (4)
• Memory-Image: il codice compilato può essere caricato
in memoria ed immediatamente eseguito. La possibilità di
utilizzo di librerie può essere limitata. Il programma deve
essere ricompilato per ogni esecuzione (Absolute Binary)
Compilatori a due passi
• Sfrutta l'aggregazione front end, back end
• Front end: il compilatore traduce il sorgente in un
linguaggio intermedio dipende dal linguaggio sorgente,
ma è indipendente dalla macchina target
• Back end: generazione del codice oggetto e
l'ottimizzazione, indipendente dal linguaggio sorgente, ma
dipende dalla macchina target
Implicazione della compilazione a due passi : rende più semplice la costruzione di un
compilatore per un nuovo processore (retargeting), in aggiunta consente di progettare
compilatori con multipli front-end.
Lezione 3 - Compilatori parte II
Corso — Programmazione
Linguaggi di programmazione— Compilatori ed interpreti
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Analisi Lessicale
• Legge il programma sorgente carattere per carattere e
ritorna i token del programma sorgente. I token sono gli
elementi minimi di un linguaggio (parole chiave, nomi di
variabili, operatori).
• Implementato come automa a stati finiti deterministico
• Programma di scan o scanner
• Identificatori memorizzati nella symble table assieme agli
attributi rilevabili
Esempio: 32+29 +10 diventa <num,32>
<+,><num,29><+,><num,10> con num il token che
rappresenta gli interi
L'attributo non ha ruolo nel parsing ma serve
successivamente
Fase di analisi Lessicale(1)
• Vengono eliminate le informazioni non necessarie presenti
nel codice sorgente (commenti)
• Vengono processate le direttive di compilazione (include,
define, etc)
• Vengono scoperti eventuali errori nel lessico
• Si tiene traccia nell'error handling della riga in cui è stato
rilevato l'errore
a = b ∗ 10
token:
a identificatore
:= assegnamento
b identificatore
* operatore moltiplicazione
10 numero
Fase di analisi Lessicale(2)
• Indentificatori: Utilizzati come nomi per variabili
funzioni ecc
Per una grammatica un identificatore è un token
contatore := contatore + incremento per la grammatica è
una cosa del tipo id := id + id
I lessemi (contatore e incremento) servono per capire a
che istanza è associato il token e vengono inseriti nella
symble table
Un lessema è una sequenza di caratteri che genera un
match con un pattern per le generazione di token
I lessemi vengono scritti nella symble table e un puntatore
ai lessemi viene associato al token id come attributo
• Keyword: identificano i costrutti, sono costruiti secondo
le regole che generano un identificatore
Problema: capire se un lessema è un identificatore o una
keyword
Si risolve con le keyword riservate
Una keyword è generata da un pattern unico per ogni
keyword
• Pattern: Un token tipo relazione è espresso dall'elenco
Fase di analisi Lessicale(3)
• L'analizzatore lessicale quindi legge i caratteri li associa in
lessemi e passa i token formati dai lessemi con i relativi
attributi allo stage successivo del compilatore
• A volte per farlo deve leggere avanti. Esempio se legge <
deve leggere il prossimo carattere per capire se si tratta di
<=
• A livello lessicale solo pochi errori possono essere
identificati, data la visione molto localizzata
dell'analizzatore lessicale
• Esempio fi (a==f(x))... è un if scritto male o un
identificativo di funzione?
Fase di analisi Lessicale(4)
• Grammatica:
stmt → if expr then stmt | if expr then stmt
else stmt | expr → term relop term | term
term → id | num
• I terminali in grassetto sono generati da espressioni
regolari
if → if; then → then; else → else
relop → <|>|<=|>=|!=|=
letter → A|B|· · · |Z|a|· · · |z
digit → 0|1|· · · |9
id → letter(letter|digit)∗
num → digit + (. digit + )?(E(+|-)?digit + )?
• L'operatore ? indica zero o una istanza
• Notazione esponenziale 6.44E-5
• Questo num rappresenza interi senza segno e valori reali
con notazione esponenziale stile Pascal
Fase di analisi Lessicale(5)
• Considerando i lessemi separati da spazi bianchi allora
servirebbero anche le definizioni di questi spazi
delim → blank | tab | newline
ws → delim+
• Se l'analizzatore lessicale trova un ws non torna token
Fase di analisi Lessicale(6)
• Dato che si usano le espressioni regolari lo strumento che
serve per riconoscerle è la ASFD a volte uno strumento
analogo chiamato transition diagram
• Il transition diagram permette di ritornare in modo
esplicito anche l'attributo associato al token che in questa
fase potrebbe essere:
Un puntatore alla symbol table per identificatori (id) e
numeri (num)
Una costante simbolica che dice cosa fa il simbolo letto es:
LT per il simbolo < con token relop
Fase di analisi Lessicale(7)
• Le tecniche usate per la scrittura di un analizzatore
lessicale possono essere usate in molti altri ambiti
• Il problema è quello di specificare e progettare programmi
che eseguono azioni scatenate da pattern (linguaggi
specifici pattern programming come lex)
• Descrizione di pattern tramite espressioni regolari
• Tool per la generazione di un analizzatore lessicale
Fase di analisi Lessicale:tool(1)
• Un tool per la generazione di analizzatori lessicali molto
famoso è il Lex
• Si usa il linguaggio lex per definire le specifiche
dell'analizzatore lessicale
• Tali specifiche vengono compilate dal compilatore lex che
genera un programma c che compilato a sua volta
produce il programma che fa da analizzatore lessicale
Fase di analisi Lessicale:tool(2)
• Il linguaggio Lex prevede:
Parte dichiarativa: con variabili costanti e espressioni
regolari
Regole di traduzione: che consistono in una espressione
regolare ed una azione (in lex scritta in C) associata che
l'analizzatore deve compiere nel momento che il pattern
regolare è riconosciuto
Procedure ausiliarie: procedure richieste dalle azioni
• Nota: l'analizzatore lessicale se pur trattato come
elemento separato dall'analizzatore sintattico coopera
fortemente tanto che a volte cede il controllo al parser
subito dopo aver compiuto l'azione relativa ad un token
riconosciuto
Lezione 4 - Compilatore parte III
Corso — Programmazione
Linguaggi di programmazione— Compilatori ed interpreti
Marco Anisetti
e-mail: [email protected]
web: http://homes.di.unimi.it/anisetti/
Università degli Studi di Milano — Dipartimento di informatica
Struttura di un compilatore
Fase di analisi sintattica (1)
• Si tratta del procedimento di costruzione della derivazione
di una frase rispetto ad una data grammatica. Usa i token
ed esegue il controllo sintattico attraverso una CFG
(Context Free Grammar), spesso nella forma di BNF. Il
risultato di questa fase è un albero sintattico
• Cerca errori sintattici e raggruppa i token in frasi
grammaticali
• Implementata come un parser che riceve i token dallo
scanner (analisi lessicale)
Fase di analisi sintattica (2)
• Le regole di una CFG, come la BNF vista nelle precedenti
lezioni, sono ricorsive.
• Ecco le regole BNF che stanno dietro il parse tree della
slide precedente
< assegnamento > ::= < identificativo > ``←''
< espressione >
< espressione > ::= < identificativo > | < numero > |
< expressione > < operazione > < expressione >
< operazione > ::= ``*''
< identificativo > ::= ``a'' | ``b''
< numero > ::= ``10''
Fase di analisi sintattica (3)
• In relazione a come viene creato il parse tree,ci sono
differenti tecniche, che possono essere divise in due
gruppi:
• Top-Down Parsing: analisi sintattica discendente, viene
anche definita ``predittiva'' dato che la costruzione del
parse tree inizia dalla radice e procede verso le foglie.
Recursive Predictive Parsing, Non-Recursive
Predictive Parsing (LL Parsing: Left to right, Left most).
Si parte dal simbolo iniziale e si procede applicando
produzioni successive per arrivare alla stringa target
Fase di analisi sintattica (4)
• Bottom-Up Parsing: analisi sintattica ascendente, viene
anche definita ``shift-reduce parsing'' dato che la
costruzione del parse tree inizia dalle foglie e procede
verso la radice. Operator-Precedence Parsing (LR
Parsing: Left to right, Right most). Si parte dalla stringa
target e si procede a ritroso per riduzioni verso il simbolo
iniziale. Durante il parsing è fattore chiave riuscire a
determinare quando effettuare una riduzione e quale
produzione applicare affinchè il parsing possa proseguire
Backtracking
• Tecnica che prevede di enumerare tutte le soluzioni in
ricerca di quella che soddisfa dei vincoli
• Navigazione in strutture ad albero tenendo traccia delle
visite effettuate
• Molto complesso e lento, a volte integra euristiche per
velocizzarlo
Recursive descent parsing
• Nel caso di recursive descent parsing può capitare di
dover tornare su una decisione presa (una derivazione
scelta) perchè non porta ad un risultato
• Questa azione è il backtracking, che nel caso dei parser
non è poi così frequente, o meglio si può evitare
• Bisogna star attenti a come è definita la grammatica se
esiste una left-recursion allora potrebbe innestarsi un
ciclo infinito
• Grammatica left-recursive: A → Aα|β esiste anche la
left-recursive indiretta
Predictive parsing
• La predizione serve per cercare di evitare il backtracking
• La predizione si basa su un lookahead del simbolo
seguente che disambigua le scelte possibili
• A volte continuano ad esistere delle ambiguità anche con
il lookahead
• Esempio: stmt → if expr then stmt else stmt | if expr
then stmt
• Se leggo il simbolo lookahead if per in non terminale stmt
comunque ho due alternative
• La soluzione è l'utilizzo della fattorizzazione sinistra
• In un linguaggio di programmazione le keyword aiutano la
predizione
LL parsing
• Derivazione LL Parsing (derivazione canonica sinistra) =
derivazione in cui ad ogni passo si espande il simbolo non
terminale più a sinistra della forma di frase corrente
[ESEMPIO]
Grammatica G con regole di produzione
F = S → AB|cSc,A → a,B → bB|b
Derivazione canonica sinistra della stringa cabbc:
S => cSc => cABc => caBc => cabBc => cabbc
• Al terzo passo di derivazione si espande il simbolo non
terminale A invece del non terminale B
Top-down Parsing: non ricorsivo(1)
• Come si potrebbe fare a sviluppare un algoritmo non
ricorsivo quando il problema sembra inerentemente
ricorsivo?
• L'algoritmo di parsing non ricorsivo mantiene esplicito lo
stack contenente i simboli della grammatica
• Si basa anche su una tabella di parsing
Top-down Parsing: non ricorsivo(2)
• Parsing predittivo: l'alternativa corretta deve essere
rilevabile guardando soltanto al primo simbolo che deriva
• Considero X il primo simbolo nello stack e a il primo
simbolo da parsare
• Questi due simboli determinano quello che il parser farà
1. Se X=a=# allora ho terminato
2. Se X=a!=# allora X viene tolta dallo stack e mi sposto sul
prossimo simbolo
3. Se X è un non terminale allora controllo la tabella nella
entry M[X ,a], la quale contiene le produzioni da usare o un
simbolo di errore
4. Se in M[X ,a] ho la produzione X → UVW allora rimpiazzo X
nello stack con WVU (ovvero U per ultimo)
• Come output indico le produzioni usate
Top-down Parsing: non ricorsivo(3)
• Esempio tratto da Compilers: principles, techniques and
tools
Bottom-Up Parsing
• Shift-reduce parsing: la costruzione del parse tree
inizia dalle foglie e procede verso la radice. Si parte dalla
stringa target e si procede a ritroso per riduzioni verso il
simbolo iniziale
• Ad ogni riduzione una particolare sottostringa che fa
match con la parte destra di una produzione è rimpiazzata
dal simbolo sinistro della produzione
• La sottostringa deve essere scelta bene tra le possibili
• L'algoritmo di parsing più famosi di questa categoria è l'LR
(left to right scanning of the input, rightmost reduction)
• Gestisce una più amplia classe di grammatiche rispetto ai
predictive parser
• Difficile da costruire a mano ma si possono usare i tool di
generazione
Bottom-Up Parsing: riduzione
Per definizione una riduzione è il passo inverso della
procedura di derivazione (attraverso la quale un non terminale
era sostituito dal corpo di una produzione, durante la
generazione di una stringa).
< exp > ::= < exp > ``*'' < G > | < G >
< G > ::= < G > ``+'' < F > | < F >
< F > ::= ``(''< exp > ``)'' | ``a''
Riduzione vs Derivazione
• Si consideri la grammatica BNF
S ::= 'a'< A >< B >'e'
A ::= < A >'b'c' |'b'
B ::= 'd'
• Data la stringa: abbcde
• La riduzione si ottiene:
abbcde (A→b A→ < A >bc B→d S→aABe)
abbcde, aAbcde, aAde, aABe, S
• La derivazione si ottiene:
S ⇒ aABe ⇒ aAde ⇒ aAbcde ⇒ abbcde
Fase di analisi semantica(1)
• Si occupa di controllare il significato delle istruzioni
presenti nel codice in ingresso. Il type checking ad
esempio dipendente solamente dalle regole semantiche
del linguaggio sorgente mentre è indipendente dal
linguaggio target.
• L'analisi semantica integra l'analisi sintattica o traduce
alberi sintattici in strutture utili alle elaborazioni
successive es AST
• Si appoggia sulla tabella dei simboli e i relativi attributi
• Generalmente vengono effettuati controlli statici: Divisioni
per 0, Controlli sul flusso, Controlli di unicità es. verificare
dichiarazioni multiple delle variabili in uno scope
[ESEMPIO]
a := b + 10
Il tipo dell'identificatore a deve corrispondere con il tipo
dell'espressione b + 10
Fase di analisi semantica(2)
• Le informazioni semantiche non possono essere
rappresentate con un semplice parse tree, ma serve
associarvi degli attributi
• Le produzioni vengono integrate, come già visto con
annotazioni di regole ( a volte frammenti di codice)
• Tali regole o frammenti sono eseguiti quando la
produzione viene utilizzata durante l'analisi sintattica
• Le regole servono per il calcolo degli attributi dei nodi
coinvolti
• Syntax-directed Translation: L'esecuzione dei
frammenti di codice, nell'ordine determinato dall'analisi
sintattica
Generatore codice intermedio(1)
• L' AST rappresenta la prima forma di Intermediate
Representation (IR) del programma sorgente.
• In generatore di codice traduce ciò che è semanticamente
corretto catturandone il significato a run-time
[ESEMPIO]
L'AST di un ciclo contiene due sotto-alberi, uno per
controllare l'espressione di controllo, e l'altro per il corpo
del ciclo. Nulla nell'AST dimostra che un ciclo ``itera'',
solo la sua traduzione lo palesa
• La Intermediate Representation esplicita la nozione di
verifica del valore dell'espressione di controllo e
dell'esecuzione del corpo del ciclo
Generatore codice intermedio(2)
• Three-address code(TAC o 3AC): Codice di basso livello
simile al linguaggio macchina che si può generare da un
AST
• Ogni istruzione nella forma 3AC può essere descritta dalla
quadrupla (operatore, operando1, operando2, risultato),
nella forma y = x op z
• Se ho più di una operazione fondamentale op in una
espressione allora la scompongo
• Si parla solo di una sola operazione di calcolo, un
confronto oppure un salto.
Generatore codice intermedio(3)
Generatore codice intermedio(4)
• Alcuni compilatori prevedono una IR di alto livello (source
oriented) e una IR a basso livello (target oriented)
• Chiara separazione fra dipendenze derivanti dal sorgente
e dal target
1.
2.
3.
4.
5.
a := b ∗ c + 2
id1 := id2 ∗ id3 + 2
MULT id2,id3,temp1
ADD temp1,#2,temp2
MOV temp2,id1
Compilatori: fase di sintesi
• Generatore codice: Mappa il codice IR prodotto dal
traduttore nel codice macchina target (di una specifica
architettura)
• Il codice target è un codice oggetto rilocabile contenente
codice macchina
• Si basa sulla definizione di template che mettano in
corrispondenza le istruzioni low-level IR con le istruzioni
target
• Ottimizzatore: cerca di migliorare il codice per limitare il
tempo di esecuzione e la memoria necessaria
• Esempio per l' IR precedente:
1.
2.
3.
4.
a := b ∗ c + 2
id1 := id2 ∗ id3 + 2
MULT id2,id3,temp1
ADD temp1,#2,id1