Kristian Lindgren
Evolutionary phenomena in simple dynamics
traduzione a cura di Fabio Ruini ([email protected])
Università degli Studi di Modena e Reggio Emilia
Facoltà di Scienze della Comunicazione e dell'Economia
(prima versione, dicembre 2004)
Presentiamo un modello di una popolazione di individui, che giocano una
variante iterata del “Dilemma del prigioniero”, nella quale il “rumore”
può portare i giocatori a commettere degli errori. Ciascun individuo agisce
in accordo ad una strategia a “memoria finita”, codificata nel suo
genoma. Tutti giocano contro tutti e, quelli che si comportano meglio,
raccolgono una discendenza più numerosa nella successiva generazione.
Le mutazioni permettono al sistema di esplorare lo spazio delle strategie,
e la selezione favorisce l'evoluzione di strategie cooperative e “nonexploitable”. Nelle simulazioni di questo modello, si incontrano diversi tipi
di fenomeni evolutivi, come periodi di stasi, equilibri punteggiati, ampie
estinzioni, causalità reciproca e strategie evolutive stabili.
Introduzione
Nella costruzione di modelli semplici relativi a sistemi evolutivi astratti,
la teoria dei giochi fornisce un ampio numero di concetti e di esempi di
giochi che possono essere usati per modellizzare l'interazione tra gli
individui all'interno di una popolazione. Originariamente, la teoria dei
giochi venne sviluppata da von Neumann e Morgenstern per l'applicazione
alla teoria economica, ma essa si è oggi altrettanto diffusa ad altre
discipline. Il lavoro di Maynard-Smith e Price ha portato ad un utilizzo
sempre maggiore della teoria dei giochi nell'ambito dell'ecologia
evoluzionista (evoluzione dell'ambiente). Nell'ambito delle scienze sociali, i
metodi legati alla teoria dei giochi sono stati accettati per lungo tempo. Un
rinnovato interesse relativo al “Dilemma del prigioniero” è seguito ai
lavori di Axelrod ed Hamilton, che hanno effettuato una dettagliata
analisi della versione iterata di questo gioco, la quale ha portato alla
nascita di diversi modelli teorici di giochi basati sul Dilemma del
Prigioniero iterato. Nelle grandi reti di computer, la presenza di agenti
interagenti può portare ad ecosistemi computazionali, che possono essere
analizzati da un punto di vista di gioco teorico.
Per una popolazione con un dato numero di specie, la selezione naturale
guida il sistema verso un punto fisso, un ciclo limite o un attrattore
strano, assumendo un ambiente stabile. Questo processo può essere
modellizzato dalle dinamiche della popolazione, dove si utilizza
solitamente il numero di individui delle differenti specie come variabile,
cosicché la dimensionalità del sistema sia uguale al numero delle specie.
1
Le dinamiche della popolazione modellizzano la riproduzione, la
sopravvivenza e la morte degli individui. Se il comportamento degli
individui (o delle specie) dipende da una descrizione genetica ereditata
dalla discendenza, l'introduzione delle mutazioni nel processo di
replicazione può totalmente cambiare il comportamento dinamico del
sistema. Un modo per descrivere un tale sistema dinamico è interpretare
le mutazioni che portano a nuove specie come creazioni di nuove variabili
e l'estinzione di specie come la scomparsa di variabili presenti. Ma in
entrambi i casi, questi eventi sono dovuti alla (stocastica) dinamica del
sistema stesso. Se non ci fossero limiti alla lunghezza della descrizione
genetica ed al numero di caratteri fenotipici codificati al suo interno, il
sistema potrebbe essere considerato come un sistema dinamico di
dimensioni potenzialmente infinite. L'evoluzione può essere vista come un
fenomeno transitorio in un sistema dinamico di dimensioni
potenzialmente infinite. Se i transienti continuano per sempre, abbiamo a
che fare con una “evoluzione open-ended”. Ovviamente, possiamo ottenere
lo stesso comportamento che si ha nelle dinamiche delle popolazioni senza
mutazione. Di conseguenza, uno dei problemi principali nella costruzione
di modelli evolutivi è come modellizzare le interazioni tra le specie (e/o con
l'ambiente) in modo tale che il transiente sia infinito o almeno
sufficientemente lungo affinché il fenomeno evolutivo abbia luogo. In
questa costruzione, ci si trova ad affrontare il problema di raggiungere sia
un'elevata complessità, necessaria affinché avvenga l'evoluzione, sia la
semplicità, che rende la simulazione possibile su scale di tempo evolutive.
Si noti che le dinamiche usate per modellizzare il comportamento
nell'evoluzione chimica sono solitamente una forma di dinamiche delle
popolazioni. Sistemi di questo tipo sono stati analizzati, ad esempio, da
Farmer, Schuster ed Eigen, nel contesto di modelli per l'evoluzione di
macromolecole.
Abbiamo costruito un modello di una popolazione di individui che giocano
il Dilemma del Prigioniero nella sua versione iterata. Il gioco è modificato
in modo tale che il rumore possa disturbare le azioni intraprese dai
giocatori, il che rende più complicato il problema di individuare la
strategia ottimale. Questo aumenta la possibilità di ottenere transienti
lunghi, che mostrano comportamenti evolutivi. Costruiamo un'appropriata
codifica per tutte le strategie deterministiche a memoria finita e facciamo
sì che questo codice sia utilizzato come genoma per un individuo che gioca
la strategia corrispondente. Aggiungendo le mutazioni alle dinamiche
della popolazione, otteniamo un sistema dinamico di dimensioni
potenzialmente infinite, all'interno del quale l'evoluzione è possibile.
All'interno del modello, la selezione “artificiale” è determinata dal
risultato del gioco – gli individui che ottengono punteggi più alti avranno
anche una fitness maggiore.
L'idea di utilizzare il Dilemma del Prigioniero iterato nelle situazioni
2
evolutive non è nuova, si vedano ad esempio gli studi di Axelrod e Miller,
ed una varietà di altri tipi di modelli evolutivi può essere trovata in
Langton. L'approccio innovativo di questo studio è dato dalla
combinazione di giochi con rumore, semplici dinamiche della popolazione,
interazioni analiticamente risolvibili e possibilità di incrementi nella
lunghezza del genoma, che sembra portare ad una ricchezza nel
comportamento evolutivo mai osservata in alcun modello precedente.
Il Dilemma del Prigioniero
Il dilemma del prigioniero è un gioco a due persone ed a somma non-zero,
che è stato utilizzato sia nella sperimentazione, sia nelle ricerche teoriche
sul comportamento cooperativo. Il gioco è basato sulla seguente situazione.
Due persone sono state catturate e sono sospettate di aver commesso un
crimine insieme. Non ci sono abbastanza prove per dimostrarlo, a meno
che uno dei due confessi. Così, se entrambi non parlano (cooperano, C)
saranno rilasciati. Se uno confessa (tradimento, D) ma l'altro non lo fa,
quello che ha confessato sarà rilasciato e ricompensato, mentre l'altro
subirà una severa punizione. Infine, se entrambi confessano, saranno
imprigionati, ma per un periodo di tempo più breve. Si assume che essi
prendano la loro decisione d'azione simultaneamente, senza conoscere la
decisione dell'altro.
Questo problema è formalizzato assegnando dei valori numerici a ciascuna
coppia di scelte. Un esempio di matrice dei payoff per i giocatori è
mostrata nella tabella 1.
Giocatore 2
Giocatore 1
Coopera
Tradisce
Coopera
(3,3)
(0,5)
Tradisce
(5,0)
(1,1)
Tabella 1 – La matrice dei payoff che utilizziamo nel dilemma del prigioniero è la stessa utilizzata da Axelrod.
La coppia (s1,s2) denota rispettivamente i risultati dei giocatori 1 e 2.
Se il gioco viene visto come un evento singolo, ciascun giocatore individua
nel tradimento il comportamento ottimale, indipendentemente dall'azione
dell'avversario. Tuttavia, se è altamente probabile che i due giocatori si
incontreranno nuovamente nello stesso tipo di gioco, la questione su quale
sia la scelta d'azione ottimale diventa più delicata. Questo tipo di
“dilemma del prigioniero iterato” è stato studiato intensamente da
Axelrod. Dai risultati di un torneo simulato a computer, egli ha scoperto
che una semplice strategia chiamata Tit-for-Tat (TFT) evidenzia la
performance migliore nel gioco iterato. La Tit-for-Tat inizia con la
cooperazione e successivamente ripete l'ultima azione dell'avversario. In
3
questo modo, due giocatori TFT che si affrontano in una serie di giochi,
condividono la ricompensa totale più alta possibile ed ognuno di essi
totalizza un punteggio medio pari a 3.
Nel nostro modello lasciamo che il rumore interferisca con le azioni dei
giocatori. Con probabilità p, l'azione compiuta è l'opposto di quella voluta.
(Dobbiamo assumere che la lunghezza media T del gioco sia molto più
ampia del tempo medio tra azioni modificate dal rumore, T >> 1/(2p).).
Per due giocatori che utilizzano la strategia TFT, la presenza del rumore
fa sì che essi alterneranno tre diversi comportamenti. Primo, essi
giocheranno le azioni ordinarie della strategia TFT (C,C), ma appena vi
sarà un errore cambieranno alternando (C,D) e (D,C). Il terzo
comportamento possibile è infine il giocare sequenze di (D,D). Le
probabilità medie di ottenere queste tre modalità sono rispettivamente
1/4, 1/2 ed 1/4, che forniscono una ricompensa media complessiva pari a
9/4. Nessuna delle strategie del torneo di Axelrod è in grado di affrontare
il rumore e di resistere all'exploitation, e la TFT continua così ad essere la
migliore all'interno di questo insieme. Una semplice strategia più
resistente al rumore è la Tit-for-Two-Tats, dove si ha il tradimento di un
giocatore soltanto se l'avversario tradisce per due volte consecutive, ma
questa strategia è vulnerabile a strategie di exploiting e, in un contesto
evoluzionista, risulta meno performante rispetto a quella originale. Un
altro modo di diminuire la sensibilità al rumore è consentire alle strategie
di scegliere tra azioni diverse, in funzione di certe probabilità (strategie
miste). Questo approccio è stato analizzato da Molander, il quale ha
scoperto che una strategia che combina TFT ed ALLC (always cooperate)
può raggiungere un punteggio medio molto vicino a 3. Nel nostro modello
assumiamo che le strategie siano però deterministiche (strategie pure) e
nelle simulazioni vedremo che esistono strategie deterministiche nonexploitable e resistenti al rumore che riescono a raggiungere un punteggio
medio pressoché uguale a 3.
Memoria finita e giochi infiniti
Codifica genetica delle strategie
Nel modello abbiamo adottato strategie deterministiche a memoria finita.
Questo significa che una “storia” finita determina la successiva intenzione
di agire, benché l'azione intrapresa possa poi essere modificata dal
rumore. Una storia di lunghezza m consiste in una serie di azioni
precedenti, che hanno inizio con l'ultima azione dell'avversario a0, per poi
proseguire con l'ultima propria azione a1, la penultima scelta
dell'avversario a2, ecc... Introducendo una codifica binaria per le azioni, 0
per il tradimento ed 1 per la cooperazione, possiamo rappresentare una
storia di lunghezza m mediante un numero binario:
4
hm = (am-1, ..., a1, a0).
Poiché una strategia deterministica di memoria m associa un'azione a
ciascuna storia di lunghezza m, la strategia può essere specificata tramite
una sequenza binaria:
S = [A0, A1, ..., An-1].
Questa sequenza costituisce il codice genetico della strategia che sceglie
l'azione Ak quando si verifica la storia k. La lunghezza n del genoma è
uguale a 2m.
Nelle dinamiche della popolazione ammettiamo tre tipi di mutazioni:
mutazioni puntuali, duplicazioni geniche e “split mutations”. La
mutazione puntuale cambia un simbolo nel genoma, ad esempio [01] ->
[00], la duplicazione genica incolla una copia del genoma in coda al
genoma stesso, ad esempio [01] -> [0101], mentre la split mutation
rimuove casualmente la prima o la seconda metà del genoma, ad esempio
[1001] -> [01]. Si noti che la duplicazione genica non modifica il fenotipo.
La capacità di memoria è aumentata di uno, ma l'informazione
addizionale non viene utilizzata nella scelta dell'azione da intraprendere.
Per la mutazione puntuale abbiamo usato il tasso di 2x10-5 per simbolo e
genoma; le altre mutazioni hanno luogo con probabilità 10-5 per genoma.
Osservando una posizione del genoma come un “locus” ed un simbolo come
un allele piuttosto che come una coppia di basi, il tasso di mutazione
puntuale che utilizziamo ha lo stesso ordine di grandezza di quello che è
stato stimato per il tasso di mutazione dei luoghi nei sistemi viventi.
Per le strategie a memoria uno, le storie sono etichettate come 0 ed 1,
corrispondenti rispettivamente al tradimento ed alla cooperazione da
parte dell'avversario. Le quattro strategie a memoria 1 sono [00], [01], [10]
ed [11]. La strategia [00] tradisce sempre (ALLD), [01] coopera soltanto
quando si verifica la storia 1 (ossia quando l'avversario coopera) e
possiamo riconoscerla come Tit-for-Tat, [10] opera all'opposto e possiamo
quindi chiamarla Anti-Tit-for-Tat (ATFT), mentre [11] coopera sempre
(ALLC). Utilizziamo proporzioni uguali di queste strategie come stato
iniziale delle simulazioni.
Risolvendo il gioco
Se la lunghezza del gioco è infinita, la distribuzione stazionaria lungo le
storie finite può essere risolta analiticamente. Questa soluzione è unica se
è presente il rumore che disturba le azioni. Nonostante il gioco sia infinito,
le strategie possono prendere in considerazione soltanto storie finite
quando devono scegliere un'azione di gioco, il che significa che il gioco
infinito è un processo Markoviano. Il punteggio medio totalizzato da due
5
giocatori che si incontrano in questo gioco può essere derivato a partire
dalle probabilità p00, p01, p10 e p11 per tutte le possibili coppie di azioni (11),
(10), (01) e (00). Questo può essere individuato se risolviamo l'equazione:
H=MH
dove HT = (h0, h1, ..., hn-1) è il vettore delle probabilità per le differenti
storie 0, 1, ..., n-1 ed M é una matrice di trasferimento. Gli elementi di M
sono determinati dalle strategie impiegate nel gioco, inclusa la possibilità
di commettere errori. La dimensione minima n della matrice è data dalla
dimensione di memoria delle strategie impiegate ed è uguale a 2m se la più
ampia memoria utilizzata è m (o 2m+1 se m è dispari ed entrambi i giocatori
hanno la stessa dimensione di memoria). E' quindi possibile ottenere pij
sommando le componenti appropriate in H ed il punteggio medio risulta
essere:
s = 3p11 + 5p01 + p00
in accordo con la matrice dei payoff vista nella tabella 1.
Dinamiche della popolazione
Consideriamo un sistema costituito da una popolazione di N individui, che
interagiscono tra loro in accordo al dilemma del prigioniero, iterato e con
rumore. Ciascun individuo agisce secondo una certa strategia codificata
nel suo genoma. Possiamo immaginare il sistema come una popolazione
che condivide la stessa nicchia, combattendo o cooperando con tutti gli
altri per ottenere una parte delle risorse disponibili per la sopravvivenza e
la riproduzione. In ciascuna generazione, tutti gli individui giocano il
dilemma del prigioniero iterato infinitamente contro tutti, ed il risultato si,
per l'individuo i viene comparato con il punteggio medio della popolazione.
Gli individui con un punteggio superiore alla media avranno una più
ampia discendenza nella generazione successiva. Nella riproduzione, le
mutazioni possono portare alla comparsa di nuove strategie.
Modellizziamo questa situazione come segue. Primo, identifichiamo i
differenti genotipi presenti nella popolazione e lasciamo che si incontrino
nel gioco descritto sopra. Assumiamo che gij sia il risultato conseguito
dalla strategia del genotipo i giocando contro la strategia di j, e che xi sia
la frazione della popolazione occupata dal genotipo i. Quindi, il punteggio
si per un individuo con genotipo i è:
6
ed il risultato medio è:
La fitness wi di un individuo è definita come la differenza tra il suo
punteggio individuale ed il punteggio medio:
Da una generazione t alla successiva generazione t+1 assumiamo che, per
via del risultato delle interazioni, la frazione xi della popolazione per il
genotipo i cambi secondo la formula:
dove d è una costante di crescita. Questa equazione può anche essere
scritta nella forma seguente:
che è un'equazione logistica per una popolazione di specie in competizione.
La capacità di carico è normalizzata ad 1 ed i coefficienti di competizione
per le specie i sono sj/si (j=1, 2, ...). Si osservi che questa equazione di
crescita conserva la dimensione totale della popolazione. Se xi scende al di
sotto di 1/N per un certo genotipo j, impostiamo sj = 0 e quella specie è
morta. Quando ciò accade, la frazione xi deve essere ri-normalizzata
affinché la dimensione della popolazione rimanga costante.
Quando sono presenti mutazioni, si ha un termine stocastico addizionale
mi all'interno dell'equazione della crescita. Se il tasso di mutazione è basso
(pp + pd +ps << 1/N), il termine addizionale è bene approssimato dalla
formula:
dove Qij è una variabile stocastica che assume il valore 1 se un gene j muta
in un gene i ed il valore 0 nel caso opposto. La probabilità che Qij sia
uguale ad 1 è:
7
dove qij è la probabilità che il genotipo j muti in i, ottenuta dal tasso di
mutazione e dai genotipi i e j. (Questa mutazione può essere ottenuta da
una duplicazione genica e da diverse mutazioni puntuali, anche se ciò è
meno frequente). Per la presenza del termine mi, nell'evoluzione temporale
possono apparire nuovi genotipi, dando così luogo ad un modello con uno
spazio degli stati potenzialmente infinito.
Risultati della simulazione e discussione
Il sistema descritto qui sopra consiste in una popolazione di N individui
tra loro interagenti in accordo al Dilemma del Prigioniero iterato, con una
probabilità p di errore (rumore). Gli individui che totalizzano i punteggi
più alti ottengono una maggior discendenza nella generazione successiva,
rispetto a quelli che conseguono punteggi più bassi. In questa riproduzione
ammettiamo che possano avere luogo mutazioni e che nuove strategie
possano entrare in gioco.
Modellizziamo le dinamiche del sistema mediante le equazioni 6-9. I
parametri che inseriamo sono il tasso di crescita d, i tasso di mutazione pp,
pd e ps, la dimensione N della popolazione e la probabilità di errore p.
Nell'esempio di simulazione, i valori dei parametri sono N = 1000, p =
0.01, pp = 2 x 10-5, pd = ps = 10-5 e d = 0.1 ed abbiamo inoltre ristretto la
lunghezza del codice genetico ad un massimo di 32 bit, vale a dire ad un
massimo di strategie di memoria 5. Per la prima generazione abbiamo
scelto frazioni uguali delle quattro strategie a memoria uno, cioé: x00 = x01
= x10 = x11 = 1/4..
Praticamente tutte le simulazioni hanno in comune il fatto che durante
l'evoluzione il sistema passa attraverso diversi stati duraturi metastabili
(periodi di stasi) che appaiono secondo un certo ordine. Questi periodi sono
solitamente interrotti da veloci transizioni verso comportamenti dinamici
instabili o verso nuovi periodi di stasi. Più sotto discuteremo i fenomeni
evolutivi osservati in una tipica simulazione del modello. Nei quattro
periodi di stasi più comuni troviamo esempi di coesistenza tra le specie,
exploitation, emergenza spontanea di mutalismi (simbiosi) e cooperazione
non-exploitable.
L'evoluzione delle strategie a memoria 1
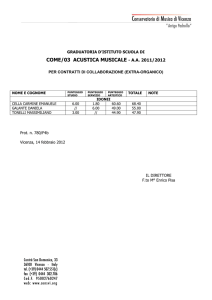
Nella figura 1 è mostrato lo sviluppo della popolazione per le prime 600
generazioni. Durante le prime 150 generazioni, le dinamiche guidano il
sistema delle 4 strategie verso una popolazione composta principalmente
8
da strategie TFT. La strategia All-D [00] exploits la strategia di tipo All-C
[11] e la strategia ATFT [10], aumentando di conseguenza la propria
proporzione all'interno della popolazione. Quando le strategie [11] ed [10]
sono estinte, il punteggio medio di All-D si avvicina ad 1 e la strategia Titfor.Tat, maggiormente cooperativa, si impone sulla popolazione.
Figura 1 – L'evoluzione di una popolazione di strategie, che inizia con uguali frazioni di strategie
a memoria uno [00], [01], [10] ed [11], è mostrata in merito alle prime 600 generazioni.
La frazione di diverse strategie è vista come una funzione del tempo (generazione).
Ad ogni modo, la Tit-for-Tat raggiunge soltanto un punteggio medio di 9/4,
poiché il rumore interferisce con l'interazione. Allora, attraverso una
mutazione puntuale [01] -> [11], la strategia All-C entra di nuovo sulla
scena. La mutante ottiene un punteggio medio vicino al 3 ed in questo
modo la frazione di [11] incrementa rapidamente. Il terreno diventa così
fertile per la sopravvivenza di una mutante [11]->[10], siccome ATFT
exploits ALLC e gioca discretamente bene contro TFT. Attualmente, ATFT
ottiene lo stesso punteggio s = 9/4 della TFT quando gioca contro ATFT o
TFT. Quando la popolazione di ATFT è cresciuta sino a diventare
sufficientemente grande, le mutazioni da [01] ed [10] verso [00]
sopravvivono e la frazione di ALLD incrementa ancora. Il sistema oscilla,
guidato da dinamiche della popolazione relativamente veloci, in
combinazione con le mutazioni puntuali.
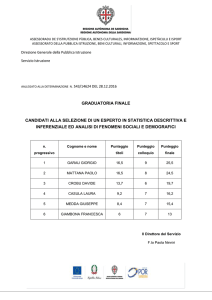
Nella figura 2 la scala temporale è compressa di un fattore pari a 50 ed è
mostrata l'evoluzione delle prime 30'000 generazioni. Il disegno che
abbiamo ottenuto è una storia con periodi stabili, interrotti da transizioni
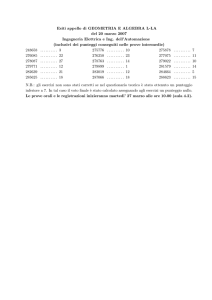
veloci o dinamiche instabili. Il punteggio medio per la stessa simulazione è
tracciato nella figura 3, che mostra come non vi sia una tendenza generale
verso punteggi più alti, nonostante la simulazione sembri terminare in
uno stato stabile e ad alto punteggio. Nella stessa figura è mostrato, il
numero di specie per generazione, evidenziando come la dimensionalità
del sistema possa aumentare o diminuire nel corso dell'evoluzione.
Figura 2 – La simulazione di figura 1 è proseguita per 30'000 generazioni, mostrando che nell'evoluzione
appaiono quattro periodi di stasi. Le oscillazioni osservate in figura 1 sono attutite ed il sistema raggiunge un
periodo di stasi con la coesistenza tra [01] (TFT) e [10] (ATFT). Questa stasi è inframmezzata da un numero di
strategie a memoria 2 e, dopo un periodo di comportamento instabile, il sistema lentamente si stabilizza
quando la strategia [1001] aumenta nella popolazione. Questa strategia coopera se entrambi i giocatori
9
compiono la stessa azione nell'ultimo periodo di tempo. Per due individui che utilizzano questa strategia, un
tradimento accidentale di uno dei giocatori, porta entrambi i giocatori a tradire al tempo successivo, ma al giro
successivo essi ritornano ad un comportamento cooperativo. Di conseguenza, la strategia [1001] è cooperativa e
stabile di fronte agli errori, ma può essere exploited da strategie non-cooperative. Attualmente, uno dei suoi
mutanti [0001] exploits la tipologia di [1001], che risulta in un lento aumento di [0001] nella popolazione.
Questo porta ad una stasi duratura, dominata dal comportamento non-cooperativo di [0001]. Una più lenta
crescita del gruppo di strategie a memoria 3 è generato allora dalla mutazione e la presenza di queste specie
provoca l'oscillazione delle strategie [0001] e [1001]. Due delle strategie a memoria 3, M1 = [10010001] ed M2 =
[00011001] operano per imporsi sulla popolazione, guidando verso un nuovo periodo di stasi. Né M1 né M2
possono gestire errori quando giocano contro individui del loro stesso tipo, ma se M1 incontra M2 essi sono in
grado di tornare ad un comportamento cooperativo dopo un tradimento accidentale. Questo polimorfismo è un
esempio di mutualismo che emerge spontaneamente nel modello. La stasi viene destabilizzata da un gruppo di
mutanti ed otteniamo una veloce transizione verso una popolazione di strategie a memoria 4, che sono sia
cooperative che non-exploitable.
Dopo alcune migliaia di generazioni, le oscillazioni osservate in figura 1
sono smorzate ed il sistema si stabilizza con un mix di TFT [01] e ATFT
[10]. Se vengono prese in considerazione soltanto le quattro strategie più
semplici, questa situazione è facilmente analizzabile.
Assumiamo che la popolazione sia divisa in due frazioni, una composta da
TFT ed una da ATFT, e che x denoti la prima di queste frazioni. Allora,
per un'ampia popolazione, se x < 7/16 una mutante [00] inizierà a
replicarsi; se x > 3/4, ogni mutazione verso [11] sopravviverà e si
replicherà. Ma, se 7/16 < x < 3/4 si ha uno stato metastabile, caratterizzato
da un mix di TFT ed ATFT. Questo stato è duraturo, perché nessuna delle
mutazioni “one-step” [00], [11], [0101] e [1010] sono in grado di disturbare
il sistema. Attualmente, una dettagliata analisi mostra che l'unica
strategia con memoria 2 che può invadere questa popolazione da sola e
sopravvivere è la strategia [1100], che alterna tra C e D,
indipendentemente dall'azione dell'avversario. Tuttavia, questo non è il
modo abituale attraverso cui le stasi collassano, poiché sono necessarie
una duplicazione genica e due mutazioni puntuali per ottenere [1100] da
[01] o [10]. Solitamente, un certo numero di strategie, tutte aventi piccole
frazioni della popolazione, hanno un effetto combinato e causano la
destabilizzazione dell'intero sistema.
Figura 3 – Il punteggio medio s (linea continua) ed il numero di genotipi n (linea spezzettata) sono mostrati
per la simulazione di figura 2. Quando la strategia exploiting di memoria 2 domina la scena, il punteggio medio
crolla divenendo prossimo ad 1.L'ultima stasi, popolata da strategie a memoria 4 evolutivamente stabili,
sembra avere più mutanti che sopravvivono ed il numero di genotipi aumenta, suggerendo che la maggior
parte dell'evoluzione ha luogo in questi intervalli.
10
L'evoluzione delle strategie a memoria 2
Le prime stasi sono solitamente seguite da un periodo di comportamento
instabile, come esemplificato in figura 2. Quando il sistema si stabilizza la
strategia A = [1001] opera per dominare la popolazione per qualche tempo.
Questa strategia sceglie C quando l'ultima coppia di azioni (la propria e
quella dell'avversario) era CC o DD, il che significa che due individui, che
giocano entrambi questa strategia, ottengono un punteggio vicino a 3
quando giocano contro tutti gli altri. Una storia tipica include un'azione
non voluta D simile alla seguente (CC, CD, DD, CC, CC, ...), mostrando
che la strategia non è sensibile al rumore. D'altro canto, la strategia può
essere exploited da una delle sue mutanti, B = [0001]. Quando la strategia
A gioca contro B, si hanno due modalità di comportamento, esemplificate
dai seguenti tipi di storie: (CC, CC, CC, ...) e (DD, CD, DD, CD, ...) dove la
seconda azione in ciascuna coppia è dovuta a B. La seconda modalità
compare con frequenza 0.80 ed il suo punteggio medio è 3 per B e soltanto
1/2 per A. Sebbene le strategie A e B abbiano comportamenti totalmente
differenti (rispettivamente cooperativi e non-cooperativi), i punteggi che
esse totalizzano sono molto vicini. Questo porta ad un lento incremento di
B, mentre A diminuisce nella popolazione (vedi figura 2). Anche un piccolo
gruppo di mutanti può quindi influenzare i loro risultati in modo tale che
la strategia dominante accumuli un punteggio più basso rispetto alle
specie rivali, il che spiega spiega il pattern oscillatorio che ne consegue.
L'evoluzione delle strategie a memoria 3
Durante il periodo di tempo dominato dalle strategie a memoria 2, un
gruppo di mutanti contenenti strategie a memoria 3 cresce lentamente. In
figura 2 vediamo due nuove strategie M1 = [10010001] ed M2 = [00011001]
diffuse nella popolazione. Una nuova stasi é raggiunta tra M1 ed M2 ed
analizzeremo più in dettaglio il comportamento delle due. Le storie qui
sotto esemplificano come queste strategie agiscono quando una singola
azione D, indotta dal rumore, ha luogo:
11
Gli individui che giocano contro lo stesso tipo di strategia non sono in
grado di gestire il rumore, ma quando le strategie M1 ed M2 giocano contro
ogni altra, esse operano per tornare ad una modalità cooperativa dopo una
serie di azioni intermedie. Le strategie rispondono ad un disturbo D con
un certo schema di azioni, che si adegua alle azioni dell'avversario. Questo
porta ad una ricompensa prossima a 3 quando si incontrano, ma la
ricompensa, quando M1 incontra M1 è S1:1 = 2.17 ed è anche peggio per M2,
s2:2 = 1.95, poiché M2 possiede anche una modalità costituita da una serie
di azioni di tradimento. Ovviamente, questo mix di strategie é un esempio
di mutualismo. Il successo di una di queste dipende dal successo dell'altra.
In figura 2 vediamo che esse si diffondono simultaneamente nella
popolazione.
L'evoluzione delle strategie a memoria 4
Durante la stasi delle due strategie simbiotiche, si forma un gruppo di
mutanti e la loro frazione nella popolazione aumenta lentamente. La stasi
finisce con una veloce transizione verso un nuovo stato metastabile,
caratterizzato da due strategie dominanti a da un crescente gruppo di
mutanti. Tutte queste strategie hanno memoria 4, ossia prendono in
considerazione le azioni attuate da entrambi i giocatori nei due time steps
precedenti. Esistono diversi genotipi che possono assumere il ruolo di
dominanti durante questa transizione, poiché è presente una classe di
codifiche genotipiche all'interno dei fenotipi o delle strategie che hanno
praticamente lo stesso comportamento. Esse sono tutte cooperative e, se
un giocatore accidentalmente tradisce, entrambi i giocatori tradiscono due
volte prima di tornare nuovamente alla modalità cooperativa. Questo
assicura che la strategia non possa essere exploited da strategie dannose
ed allo stesso tempo che gli errori fanno diminuire solo marginalmente il
punteggio medio. Nel genoma schematico E = [1xx10xxx0xxxx001] sono
mostrate le posizioni utilizzate più frequentemente ed ogni x corrisponde
ad una storia che accade con probabilità dell'ordine di p2 o inferiore. Ci
sono 512 strategie che corrispondono a questo schema, il che spiega la
formazione di un'ampia varietà genetica in questa popolazione, nonostante
alcune di queste possano avere imperfezioni che possono essere exploited
da altre strategie. Un tipico gioco che coinvolge un'accidentale azione di
tradimento D è mostrato qui sotto:
12
In figura 2, la strategia [1001000100010001] si è imposta sulle altre, ma
ne sono presenti di diverse nel gruppo crescente di quasi-specie. Il fatto
che la frazione dei genotipi dominanti decresca, può essere spiegato dalla
piccola differenza tra la strategia dominante e varie di quelle diffuse tra i
mutanti. Dovrebbe essere notato che, siccome la lunghezza del genoma
raddoppia ogni qualvolta che la capacità di memoria viene aumentata di 1,
la probabilità di una mutazione puntuale raddoppia a sua volta.
Un importante criterio di stabilità per una strategia in un modello delle
dinamiche della popolazione è dato dal concetto di strategia
evolutivamente stabile. Assumiamo che tutti gli individui presenti in
un'ampia popolazione giochino una certa strategia S. La strategia S è
evolutivamente stabile se qualsiasi gruppo di strategie invasore
sufficientemente piccolo si estingue. E' stato visto che, nel dilemma del
prigioniero iterato e senza rumore, la strategia Tit-for-Tat non è
evolutivamente stabile, poiché esistono altre strategie che giocano alla
pari con TFT ed allo stesso tempo ottengono punteggi migliori contro altre
strategie. E' stato visto da Boyd e Loberbaum che non esiste una strategia
pura che sia evolutivamente stabile nel dilemma del prigioniero iterato.
Una generalizzazione dei loro risultati mostra che ciò vale per qualsiasi
mix di popolazioni finite di strategie pure.
Per il dilemma del prigioniero iterato usato nel nostro modello, la
presenza di rumore implica che ogni strategia possa essere considerata
come un mix di due strategie pure opposte, il che consente alle strategie
evolutivamente stabili di esistere. Attualmente, la strategia dominante in
figura 2 è evolutivamente stabile. Una strategia più semplice da
analizzare è E0 = [1001000000000001], che tradisce ogni qualvolta il
comportamento devii dal pattern dell'esempio di gioco qui sopra. Ciò
implica che nessuna strategia può exploitarla e che nessuna strategia può
invadere una popolazione composta da esse cercando di essere più
cooperativa, poiché ogni tentativo di questo tipo risulterebbe favorevole a
E0 e ridurrebbe la ricompensa per l'intruso. (Si noti che E0 attualmente
exploits la strategia di tipo [11].) Ad ogni modo, anche se le mutanti onestep giocano leggermente peggio delle specie
padrona, il tasso di
mutazione può essere abbastanza ampio da permettere un aumento netto
di queste mutanti, che portano verso un gruppo crescente di quasi-specie.
Nella simulazione del nostro modello troviamo la formazione di un ampio
13
gruppo di quasi-specie.
Strade per un'evoluzione open-ended?
Lo scenario descritto qui sopra, che attraversa periodi di stasi dominati da
strategie di memoria crescente e successivamente rimane bloccato nelle
stasi evolutive stabili, si verifica con una probabilità di circa 0.9. Ci sono
comunque percorsi evolutivi che prevengono il comparire di strategie a
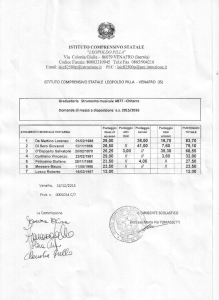
memoria 4 evolutivamente stabili. In figura 4 è mostrato un esempio di
questo tipo, dove invece di ottenere la stasi della specie simbiotica (si veda
la figura 4(a)) il sistema prende una nuova strada nello spazio degli stati.
In figura 4(b) troviamo che la popolazione è dominata da strategie a
memoria 4, non presenti nelle simulazioni ordinarie. Il diagramma più in
basso nella figura 4(b) mostra che il numero di genotipi (la maggior parte
dei quali sono anche differenti fenotipi) può aumentare a più di 200. Nella
figura si osserva che il sistema subisce un collasso nel quale la maggior
parte dei genotipi scompare nel corso di poche centinaia di generazioni.
Estinzioni simili hanno luogo anche in figura 4(c), ma esse non
coinvolgono che alcuni genotipi. In tutti questi eventi, il punteggio medio
del sistema diminuisce velocemente, suggerendo che le estinzioni siano
dovute ad una mutante che exploits le strategie presenti, ma che non è in
grado di stabilire un comportamento cooperativo con la sua stessa specie.
14
Figura 4 – Da (a) a (c) è mostrata l'evoluzione di un sistema che non passa per stasi stabili di memoria 4 per
più di 80'000 generazioni. I grafici più sotto mostrano il punteggio medio ed il numero di genotipi (si veda la
figura 3).
(a). In questa simulazione il sistema non raggiunge mai la stasi simbiotica, ma trova altre strade nello spazio
degli stati che portano a nuove strategie che dominano la popolazione.
(b). Appaiono diverse nuove strategie a memoria 4 e dominano la popolazione. Il sistema raggiunge una
dimensionalità superiore a 200 e poi incontra un collasso, dove la maggior parte dei genotipi scompare. Allo
stesso tempo, il punteggio medio crolla, indicando che questo ampia estinzione è causata da una mutazione
parassitaria che exploit la specie presente.
(c). Avviene qualche altra ampia estinzione ed alcune di queste sono accompagnate da una diminuzione dei
punteggio medio.
Conclusioni
La presenza di mutazioni nelle dinamiche della popolazione porta a
cambiamenti intrinseci nella
dimensionalità del sistema. Il
comportamento dinamico osservato è altamente complicato e con
transienti estremamente lunghi. Una caratteristica importante del
modello è che il gioco teorico utilizzato è sufficientemente complicato da
far evolvere strategie complesse, ma allo stesso tempo é possibile risolvere
il gioco analiticamente, simulando le dinamiche della popolazione lungo
scale di tempo evolutive. Se si utilizzasse invece il dilemma del prigioniero
iterato senza rumore, la possibilità di ottenere transienti evolutivi sarebbe
essenzialmente persa. Un altro aspetto importante è che, se utilizziamo
una maniera efficace di codificare le strategie nei genomi, il genoma può
venire facilmente modificato dalle mutazioni. Tenendo in mente questi
aspetti, sarebbe possibile modellizzare altrettanto bene altre situazioni,
quali modelli evoluzionistici con assunzioni più realistiche, incluse ad
esempio dipendenza spaziale e riproduzione sessuale.
Dal punto di vista del gioco teorico, abbiamo trovato che quando il
Dilemma del Prigioniero iterato è modificato dal rumore, vi è una
strategia non-exploitable che è cooperativa. La simulazione evolutiva, che
15
é in questo caso un tipo di algoritmo genetico utile per individuare buone
strategie per il rumoroso ed iterato Dilemma del Prigioniero, indica che la
memoria minima per questo tipo di strategie è 4, ossia la strategia
dovrebbe prendere in considerazione l'azione di entrambi i giocatori nei
due precedenti time steps. Rispondendo ad un singolo tradimento
tradendo due volte, la strategia è prevenuta dall'exploitation da parte di
intrusi.
Abbiamo trovato periodi di stasi inframmezzati da rapide transizioni verso
nuove stasi o verso periodi di dinamiche instabili. Queste rapide
transizioni sono un richiamo all'equilibrio punteggiato e sembra che la
destabilizzazione sia solitamente dovuta ad un gruppo di mutanti che
cresce più lentamente nel raggiungere un livello critico. La causalità
reciproca emerge spontaneamente e serve come esempio di un più alto
livello di cooperazione rispetto alle azioni che avvengono ad un livello di
singolo ciclo riproduttivo. L'apparire di una strategia evolutivamente
stabile è interessante dal punto di vista del gioco teorico, ma nella
costruzione di modelli caratterizzati da evoluzione open-ended si tende ad
eliminare questi fenomeni stabilizzanti. Di conseguenza, dal punto di
vista evolutivo, si dovrebbe prestare maggiore attenzione ai percorsi
evolutivi meno probabili, che evitano queste stasi evolutive stabili. In
particolare, le ampie estinzioni che appaiono in queste simulazioni
dovrebbero essere studiate in maggior dettaglio, siccome questi collassi
sono innescati dal sistema dinamico stesso e non necessitano di eventi
catastrofici esterni per lo loro spiegazione. Le analisi dei risultati sono in
corso a verrano riportate da qualche altra parte. Il maggior risultato
conseguito da questo modello è che esso accerta il fatto che diversi
fenomeni evoluzionistici, come quelli descritti sopra, possono emergere a
partire da dinamiche molto semplici.
16