
INTRODUZIONE ALLA GENETICA.
Un po’ di storia.
Aristotele asserisce che dalla femmina deriva la materia, la sostanza, mentre al maschio è dovuto il
movimento.
Lucrezio sostiene che tra i due genitori il contributo maggiore all’eredità è determinato da quello
dei due semi che “prevale”. Infatti i figli talvolta somigliano al padre, talvolta alla madre.
Quindi la nozione che ci siano dei caratteri trasmissibili dai genitori alla prole è antica,
antichissima.
Storicamente i primi tentativi di dimostrazione scientifica si trovano però nella seconda metà del
‘700 con Pierre – Louis Moreau de Maupertuis e Georges – Louis Leclerc de Buffon. Ipotizzarono
che ogni essere vivente fosse costituito dall’unione di un certo numero di “particelle” tutte già
presenti nel seme e nell’uovo dei genitori. Anomalie nella provvista di particelle o errori di
combinazione al momento della formazione dell’embrione possono provocare la comparsa di
individui varianti rispetto ai genitori.
Alla fine del ‘700 Lamarck propone la sua teoria della trasmissibilità dei caratteri acquisiti (si
ritrova, sotto altre forme, anche in Aristotele e in Ippocrate).
C’era anche la credenza, non solo popolare, che i caratteri ereditari si trasmettessero col sangue e
che un neonato avesse in sé una miscela del sangue dei genitori (di qui i detti del linguaggio
corrente: principe di sangue reale, sangue del mio sangue, purosangue ecc.).
Weissmann (1834 – 1914) demolì definitivamente la teoria della trasmissione dei caratteri acquisiti,
distinguendo tra cellule destinate alla riproduzione (gameti o cellule germinali) e cellule destinate a
formare il corpo (somatiche). Le cellule germinali servono alla conservazione della specie e
riproducendosi perpetuano sempre la stessa sostanza ereditaria.
Darwin fu ossessionato dal problema relativo all’eredità dei caratteri. Eppure, mentre giungeva alla
formulazione finale della teoria dell’evoluzione (pubblicata il 24. 11. 1859 - 1250 copie della prima
edizione esaurite il primo giorno) e non trovava lo schema o ordine di ereditarietà che era certo
esistesse, Mendel aveva iniziato già da molti anni, otto o nove, la sua serie di esperimenti che lo
portò a scrivere nel 1864 il suo lavoro, letto nel febbraio 1865 alla Società per lo Studio delle
Scienze Naturali di Brunn (Brno) e pubblicato nel 1866, con l’invio delle copie a più di 120
organizzazioni scientifiche e universitarie d’Europa e d’America.
La moderna genetica trova le sue basi nelle tre celebri leggi enunciate dal Mendel, ma Darwin non
conobbe mai i risultati di queste ricerche; eppure aveva un disperato bisogno di uno schema
razionale sulla trasmissione dei caratteri dai genitori alla discendenza e dovette invocare le piccole
variazioni che si hanno nella prole, punto debole della sua costruzione filosofica evoluzionistica.
Intanto Miescher scopre nel 1869 il DNA (la nucleina), ma anche questo risultato, come quelli di
Mendel, non è apprezzato dalla scienza. Si dovrà attendere il 1944 per avere la dimostrazione che il
materiale ereditario è costituito da DNA.
Da Mendel al Progetto genoma. Aspetti salienti.
1865. Mendel formula le leggi dell’ereditarietà.
1869. Miescher scopre il DNA a Tubinga. Lo denomina “nucleina”.
Vengono identificati i cromosomi. (Un libraio di Lipsia, W. Hofmeister, aveva compiuto
delle osservazioni microscopiche di corpicciuoli intranucleari già nel 1848).
1887. Weissmann distingue le cellule somatiche da quelle germinali e ipotizza il dimezzamento del
numero dei cromosomi durante la formazione delle cellule germinali.
1900. Le leggi di Mendel vengono riscoperte da De Vries, Correns e Tschermack.
1902. Sutton studia i cromosomi e ipotizza che in essi sia contenuta l’informazione ereditaria.
1907. Morgan ipotizza che l’informazione ereditaria risieda fisicamente su unità, paragonabili alle
perle di una collana, disposte lungo il cromosoma. Queste formazioni costituiscono ciascuna
un’unità genetica di base. I cromosomi costituiscono sequenze di materiale ereditario.
1906 – 1909. Johannsen denomina “geni” i fattori ereditari.
1909. Garrod compie la prima osservazione sugli effetti biochimici dei geni, scoprendo che una
malattia ereditaria, l’alcaptonuria, dipende dall’assenza di una proteina.
1915. Morgan, Muller ecc. dimostrano che l’intero campo dell’ereditarietà mendeliana può essere
interpretato analizzando il comportamento dei cromosomi.
1927. Muller dimostra che i raggi X sono mutageni. Apre lo studio delle proprietà dei geni mediante
l’induzione di mutazioni sperimentali.
1941. Beadle e Tatum avanzano l’ipotesi che ogni gene abbia come azione primaria la produzione o
il controllo di una proteina.
1944. Avery, Mc Leod e Mc Carthy dimostrano che il materiale ereditario è costituito da DNA.
1946. Tatum e Lederberg dimostrano che i batteri possono scambiarsi geni.
1952. Hershey e Chase dimostrano che alcuni virus sono costituiti da DNA, che rappresenta l’unico
materiale infettante.
1953. Wilkins, Watson e Crick propongono il modello a doppia elica per la struttura del DNA.
1960. Kornberg sintetizza una molecola di DNA.
1960. Jacob e Monod stabiliscono che alcuni geni determinano la produzione di proteine, altri
regolano l’azione dei geni.
1965. Viene completata la decifrazione del codice con il quale sono archiviate nel DNA le istruzioni
per la sintesi delle proteine. Si constata che questo codice è uguale in tutti i viventi, dai batteri
all’uomo.
1983. Mullis mette a punto la tecnica della reazione a catena della polimerasi.
2000 – 2001 (con successivo perfezionamento). Sequenziamento del genoma umano (all'inizio si
ipotizzano circa 40.000 geni; il numero viene poi ridotto a 24.000 – 21.000).
Consorzio pubblico statunitense (NHRI) di Bethesda, coordinato da Francis Collins.
Impresa commerciale Celera Genomics di Rockville (MA) diretta da J. Craig Venter.
Mentre Darwin giungeva alla formulazione finale delle teoria dell’evoluzione, un oscuro monaco
austriaco, Gregor Johann Mendel nel 1850 iniziò la prima serie di esperimenti che dovevano
dimostrare che l’ereditarietà non dipende dal caos o da un miracolo, ma è una legge rigorosa. Gli
scritti del monaco giacquero purtroppo completamente ignorati da tutto il mondo scientifico per
alcuni decenni.
Mendel cominciò, nel monastero, a sperimentare incroci tra fiori. E notò che, incrociando certe
varietà, le stesse caratteristiche continuavano ad apparire con sorprendente regolarità. I libri
consultati gli erano di poco aiuto. Mendel capì che gli studi erano stati caotici e privi di conclusioni.
Nessuno aveva cresciuto degli ibridi sistematicamente, generazione dopo generazione, e registrato
esattamente quali caratteristiche individuali apparissero in ogni pianta e altro ancora. Decise allora
di iniziarli lui.
Per cominciare gli occorrevano piante pure ed elette, facilmente proteggibili da tutti i pollini. I
legumi si prestavano meglio e dopo alcune prove scelse come pianta sperimentale un legume molto
comune, il pisello. Di norma il fiore di pisello si autofeconda ed è facilmente protetto dall’ingresso
di polline estraneo. Mendel decise di studiare alcuni caratteri del pisello facilmente paragonabili.
Dopo aver osservato che ogni tipo di ceppo parentale si manteneva puro (ossia produceva una
progenie con particolari qualità identiche a quelle dei genitori) Mendel effettuò un certo numero di
incroci tra genitori (P) che differivano per singole caratteristiche (quali la forma del seme o il colore
del seme). Tutti i discendenti (F1: prima generazione) avevano l’aspetto di un genitore. Per
esempio, in un incrocio tra piselli con semi gialli e piselli con semi verdi, tutti i discendenti avevano
semi gialli. Il carattere che compare nella progenie F1 è detto dominante, mentre quello che non
compare è detto recessivo. Il significato di questi risultati divenne evidente quando Mendel eseguì
incroci genetici tra discendenti F1.
I suoi risultati lo portarono, quindi, a formulare le seguenti leggi biologiche, proposte per la prima
volta nel 1865:
1. L’ereditarietà è trasmessa alla prole da un gran numero di unità che sono indipendenti fra loro ed
ereditabili.
2. Quando ogni genitore contribuisce con un fattore dello stesso tipo, si produce nella discendenza
un carattere costante. Se ognuno contribuisce con un tipo diverso, risulta un ibrido e, quando
l’ibrido forma le proprie cellule riproduttive, le due unità diverse si scindono di nuovo;
3. Le unità ereditarie non sono influenzate dalla loro lunga associazione con altre in un individuo;
infatti emergono da ogni unione, distinte come quando vi entrarono.
Il pensiero scientifico di allora non era ancora maturo per accogliere queste dimostrazioni. Esse
furono completamente ignorate fino al 1900, sebbene Mendel si fosse sforzato di destare l’interesse
dei biologi più eminenti del suo tempo. In seguito, Hugo De Vries, Karl Correns ed Erich
Tschermak, compiendo studi separatamente, si resero conto dell’enorme importanza degli studi di
Mendel fino ad allora ignorati. Tutti e tre, conducendo esperimenti simili a quelli di Mendel,
raggiunsero la medesima conclusione prima ancora di conoscere il lavoro di Mendel.
Leggi di Mendel. Nome di leggi che riassumono la teoria dell’ereditarietà formulata da Gregor
Mendel. Egli avanzò l’ipotesi che i caratteri individuali fossero determinati da “fattori” ereditari.
Quando divenne possibile, grazie a microscopi più potenti, studiare i particolari delle strutture
delle cellule, si poté stabilire che il comportamento dei “fattori” di Mendel era correlato con il
comportamento dei cromosomi durante la meiosi.
Tre leggi.
Legge della dominanza dei caratteri o dell’uniformità degli ibridi: incrociando tra loro individui
puri che differiscono per un solo carattere si ottengono alla prima generazione ibridi tutti uguali, si
ha cioè uniformità degli ibridi. Ogni carattere è regolato da una coppia di fattori, quello dominante
prevale su quello recessivo.
Legge della segregazione o disgiunzione dei caratteri: alla seconda generazione ottenuta
incrociando fra loro gli ibridi della prima, i fattori che regolano un determinato carattere si
distinguono e si separano in una proporzione fissa e precisa (3: 1).Tutti i caratteri ereditari sono
controllati da due “fattori” (oggi chiamati alleli) che si segregano, ossia si separano, ed entrano in
diverse cellule germinali.
Legge dell’indipendenza dei caratteri: incrociando individui che differiscono fra loro per due o più
caratteri, ogni coppia di fattori che regola ciascun carattere viene ereditata in maniera del tutto
indipendente dall’altra; si hanno così tutte le possibili combinazioni dei fattori di ciascuna coppia e
la comparsa di individui con caratteri nuovi. Le coppie di “fattori” si separano indipendentemente
l’una dall’altra quando si formano le cellule germinali.
Arrivano i cromosomi!
1879. Walter Flemming osserva che, prima della divisione cellulare, ciascun cromosoma si duplica
per formare due cromosomi identici a quello originario, raddoppiando, quindi, il numero dei
cromosomi nucleari. Poi, nel corso della divisione nucleare, ciascuno dei due nuclei figli riceve uno
dei due cromosomi così formatisi (mitosi). Risultato: il corredo cromosomico delle cellule figlie è
quindi, di solito, identico a quello delle cellule parentali.
NOTA. Nelle piante superiori e negli animali, ogni tipo specifico di cromosoma è normalmente
presente in due copie (alleli) provenienti una dal genitore maschio e una dal genitore femmina
(cromosomi omologhi, stato diploide). Durante la mitosi i cromosomi della cellula madre si
duplicano e si distribuiscono alle cellule figlie, che ne conservano inalterato il numero.
Una eccezione al processo della mitosi si verifica nelle cellule sessuali. Al termine delle due
divisioni cellulari (meiosi) che producono uova e spermatozoi, il numero dei cromosomi risulta
dimezzato in quanto ciascuna delle cellule sessuali (gameti) riceve, in modo casuale, solo uno dei
due cromosomi omologhi parentali (stato aploide). Al momento della fecondazione si
ricostituiscono le coppie di cromosomi omologhi materni e paterni.
1902. Walter Sutton, alla Stazione Zoologica di Napoli, dimostra che il numero di cromosomi in
una specie si mantiene costante di generazione in generazione. Egli osserva anche i meccanismi di
appaiamento alla meiosi fra cromosomi omologhi paterni e materni e la loro individualità. Ipotizza
che l’informazione ereditaria sia contenuta nei cromosomi.
Viva la frutta coi moscerini!
1907. Morgan, studiando il moscerino della frutta Drosophila melanogaster, ipotizza che
l’informazione ereditaria risieda fisicamente su unità, paragonabili alle perle di una collana,
disposte lungo il cromosoma. Queste formazioni rappresentano ciascuna un’unità genetica di
base. I cromosomi costituiscono quindi sequenze di unità genetiche di base, materiale ereditario che
Johannsen denomina “geni”.
1915. Morgan, Muller ecc. dimostrano che l’intero campo dell’ereditarietà mendeliana può essere
interpretato analizzando il comportamento dei cromosomi.
La bomba di avery: il DNA può trasportare specificità genetica.
Studiando i batteri (Diplococcus pneumoniae) che causano la polmonite emerse, in maniera
completamente inattesa, che il DNA poteva essere la molecola genetica chiave.
Isolato per la prima volta dalla saliva umana nel 1881 da Pasteur in Francia e da Sternberg negli
USA, la relazione di Diplococcus pneumoniae con la polmonite lobare fu stabilita pochi anni dopo
da Fraenkel in Germania e da Weichselbaum in Austria.
Nel 1928 il microbiologo inglese Frederick Griffith fece la sorprendente osservazione che tipi non
virulenti (innocui) di questi batteri diventavano virulenti (causando la polmonite lobare) se
mischiati con le loro controparti virulente uccise col calore. Utilizzando i discendenti dei tipi
virulenti così creati per trasformare ancora altri batteri non virulenti, si dimostrò che tali
trasformazioni dalla non – virulenza alla virulenza rappresentavano cambiamenti ereditari. Si
determinò così la possibilità che i componenti genetici di cellule patogene uccise col calore non
fossero danneggiati e, liberati in qualche modo dalle cellule uccise, potessero attraversare la parete
cellulare delle cellule ospiti vive e successivamente ricombinarsi con l’apparato genetico della
cellula ospite. Ulteriori ricerche hanno confermato questa interpretazione genetica. La patogenicità
riflette l’azione del gene S (liscio) che determina la costruzione di un involucro che avvolge la
maggior parte dei batteri che causano la polmonite. Quando è presente il gene R (rugoso), non si
forma alcun involucro e le rispettive cellule non sono patogene. S e R si dicono alleli perché
intervengono su una caratteristica particolare (presenza o assenza di involucro) della cellula, come
nel caso dei semi di pisello lisci o rugosi, gialli o verdi ecc.
Negli anni successivi all’osservazione originale di Griffith, si trovò che estratti di batteri uccisi
erano in grado di indurre trasformazioni ereditarie, e poté iniziare una ricerca per l’identità chimica
dell’agente trasformante. A quel tempo, la maggior parte dei biochimici riteneva ancora che i
geni fossero proteine. Fu perciò un’enorme sorpresa quando nel 1944, dopo circa 10 anni di
ricerca, il microbiologo americano Oswald T. Avery e i suoi colleghi Colin M. Mac Leod e Maclyn
McCarty, al Rockfeller Institute di New York, diedero l’annuncio clamoroso che il principio attivo
era il DNA.
Sebbene i risultati della trasformazione fossero chiari, vi fu inizialmente un grosso scetticismo
riguardo alla loro applicabilità generale; molti scienziati interessati alla questione, se non tutti,
avevano il dubbio che tali risultati si sarebbero rivelati importanti solamente per certi tipi di batteri.
Ma questa scoperta fu la chiave che aprì la porta della genetica molecolare e segnò l’inizio
dell’attuale rivoluzione in biologia. La straordinaria rilevanza della scoperta di Avery fu quindi
apprezzata solo gradualmente quando si rilevò che il DNA era localizzato quasi esclusivamente
nel nucleo e quasi mai dove non vi erano cromosomi rilevabili. Inoltre si dimostrò che la
quantità di DNA per corredo diploide di cromosomi era costante per un dato organismo e uguale al
doppio della quantità presente nelle cellule aploidi degli spermatozoi. Quindi il DNA è localizzato
nei cromosomi: ciò portò a concludere che non vi era motivo di assegnare alcun ruolo genetico alle
molecole proteiche e che i geni erano costituiti da DNA.
Struttura e funzioni delle proteine
Sono costituite essenzialmente da amminoacidi (alfa – L – amminoacidi). Questi sono caratterizzati
dalla presenza di un gruppo amminico (- NH2), di un gruppo acido carbossilico (- COOH) e di un
residuo R. Gli AA che entrano nella composizione delle proteine sono venti e ognuno di questi
venti è caratterizzato da un residuo diverso (R, R’, R”, R’’’ e così via per venti residui). In pratica
ogni residuo caratterizza un amminoacido. Gli amminoacidi si uniscono tra di loro mediante legame
carboammidico (CO – NH), che si stabilisce tra il gruppo amminico di un AA e quello carbossilico
di un altro AA (legame peptidico). Si possono così formare catene molto lunghe di amminoacidi
(catene polipeptidiche), il cui scheletro è sempre il medesimo, variando però il residuo:
… - NH – CRH – CO – NH – CR’H – CO – NH CR”H – CO – NH … e che si possono così
indicare: AA – AA’ – AA” – AA ‘’’ - e così via.
ATTENZIONE !!!: La successione degli amminoacidi è determinata secondo un ben preciso
programma, che vedremo in seguito.
Nel mondo vivente esistono 20 tipi diversi di amminoacidi (con alcune eccezioni).
Struttura primaria delle proteine: è costituita da lunghe catene polipeptidiche (immaginiamo
lunghi treni formati da numerosissimi vagoni – gli amminoacidi - di 20 colori diversi, agganciati
tra di loro con lo stesso tipo di gancio) cioè da amminoacidi in sequenza uniti tra di loro tramite
legami carboammidici. La successione dei residui R (sequenza degli amminoacidi) caratterizza la
struttura primaria di ciascuna proteina. E’ dunque l’ordine nel quale si trovano disposti questi
amminoacidi che conferisce a ciascuna proteina le sue caratteristiche.
Esistono poi una struttura secondaria, una struttura terziaria e una struttura quaternaria delle
proteine. Poiché l’unica variabilità strutturale di una molecola proteica è data dalla sequenza dei
venti tipi di amminoacidi nella catena, queste strutture dipenderanno in ultima analisi dall’ordine
nel quale si susseguono gli amminoacidi.
Nelle cellule animali e vegetali esistono probabilmente 5.000 diverse famiglie di proteine, ciascuna
con un ruolo determinato.
Il ruolo svolto da una proteina entro un organismo può essere molteplice. Es.: la miosina dei
muscoli unisce alla funzione meccanica quella enzimatica. L’emoglobina dei Vertebrati ha come
ufficio fondamentale quello del trasporto di ossigeno ma è dotata altresì di attività “catalasica”
catalizzando la scissione di acqua ossigenata in acqua e ossigeno atomico. Molte proteine delle
membrane plasmatiche uniscono a funzioni protettive quelle di trasporto di macromolecole. Sono
strutture proteiche gli anticorpi, molte tossine dei veleni dei serpenti, l’insulina.
Proteine strutturali
Funzioni di sostegno o meccaniche; materiali da costruzione della fabbrica cellulare (di solito
proteine filamentose). Es. fibroina della seta; cheratina delle unghie, dei capelli, della lana;
Proteine enzimatiche e loro significato
Funzioni enzimatiche; catalizzano e controllano le miriadi di reazioni simultanee che si svolgono
all’interno della cellula (sono di solito proteine globulari).
Ciò che un organismo è (a qualunque regno, … classe, genere o specie appartenga) è funzione
esclusiva del suo corredo proteico, e, in particolar modo, di quello enzimatico. Ma il corredo
proteico dipende essenzialmente dalla varia sequenza di amminoacidi (venti tipi diversi) lungo le
catene proteiche (struttura primaria) per formare le varie proteine. Si pone evidentemente la
questione fondamentale: che cosa determina il corretto montaggio delle migliaia di proteine che
vengono prodotte continuamente nelle cellule? Come può un minuscolo uovo fecondato (all’inizio
unica cellula) crescere, svilupparsi e trasformarsi in un essere completo (protozoo, vegetale o uomo
che esso sia)? Dove si trova lo schema per l’assemblaggio delle proteine a partire dagli
amminoacidi? Come si formano migliaia di treni differenti con venti diversi vagoni? Già Aristotele
si domandava quale potesse essere questo principio attivo capace di “informare” un semplice (!)
uovo di pesce per trasformarlo in un pesce vero e proprio.
Il 25 aprile del 1953 rappresenta una delle date cruciali per l’umanità: quella della pubblicazione,
da parte di J. D. Watson e F. H. C. Crick, del lavoro sull’ipotesi strutturale (poi rivelatasi fondata)
della molecola ordinatrice degli amminoacidi per formare le molecole proteiche. Gli autori
ottennero per questo, insieme a M. H. F. Wilkins, il Nobel nel 1962.
L’immensa quantità di istruzioni necessarie per formare un organismo vivente completo (batterio,
filo d’erba, farfalla, uomo) si trova inscritta, a livello molecolare, in un lungo filamento
macromolecolare, semplice ed elegante, supporto universale grazie al quale tutti gli esseri viventi
senza eccezione trasmettono i caratteri della specie di generazione in generazione: Il DNA (acido
desossiribonucleico.
Basi chimiche del flusso di informazioni genetiche.
Abbiamo visto che, dopo che molti scienziati avevano a lungo teorizzato che i fenomeni dell’eredità
trovassero base in …“molecole”, … “gemmule” … comunque in un substrato organico suscettibile
di riprodursi e di passare da una generazione all’altra, (il gene … entità ipotetica o particella
materiale) … Avery e coll. nel 1944 proposero che il DNA fosse il substrato materiale dell’eredità.
Nel 1953 Watson e Crick proposero il modello a doppia elica per la molecola del DNA e l’ipotesi
relativa al suo meccanismo di “autoriproduzione” o meglio di reduplicazione.
I nucleotidi.
Le molecole dei nucleotidi derivano dall’unione di alcune molecole più semplici.
Componenti costanti sono:
1) acido fosforico
2) pentoso (ribosio o desossiribosio)
3) una base azotata (Adenina; Guanina; Timina; Citosina; Uracile).
Quindi pentoso, acido fosforico e base azotata costituiscono il nucleotide.
I polinucleotidi.
DNA: acido desossiribonucleico. (Basi: A, T, G, C)
RNA: acido ribonucleico. (Basi:A, U, G, C)
DNA e RNA costituiscono gli acidi nucleici.
Il DNA è formato da due catene polinucleotidiche (il pentoso è desossiribosio) avvolte a elica l’una
sull’altra e unite tra di loro attraverso le basi azotate (A; G; T; C).
L’RNA è formato da una catena polinucleotidica (il pentoso è ribosio). Solo talvolta le catene
polinucleotidiche sono due, parzialmente avvolte a elica l’una sull’altra e unite tra di loro per la basi
azotate (A; G; U; C).
Le basi azotate possono legarsi tra di loro, con legami chimici deboli, solo in questo modo:
A – T; G – C; A – U.
Il DNA presiede al trasferimento dei caratteri ereditari da una generazione cellulare all’altra e alla
sintesi proteica.
L’RNA, trascritto sul DNA, presiede alla sintesi proteica.
I nucleotidi sono sempre presenti nelle cellule di tutti i tipi e figurano tra i loro componenti più
importanti.
Struttura degli acidi nucleici.
Struttura primaria.
Lo scheletro della struttura dei polinucleotidi è monotono. Lunghe file di molecole di desossiribosio
o di ribosio congiunte da acido ortofosforico formano le catene dello scheletro sul quale si
innestano lateralmente le basi azotate (una per ogni nucleotide). In pratica l’unica variazione
possibile lungo le catene è data dal susseguirsi (sequenza) delle basi azotate, che sono, come
abbiamo visto, di quattro diversi tipi! Si usa, perciò, definire un tratto di catena di acido nucleico
con la sequenza delle sue basi; es.: … AAAGAGATTACCTCCCAT… .
Struttura secondaria.
Ci riferiremo ora al DNA.
La morfologia base della molecola fu chiarita dalla brillante ipotesi di Watson e Crick che nel 1953,
grazie anche agli studi di Rosalind Franklin e di Maurice Wilkins (quest’ultimo premio Nobel con
loro nel 1962; la Franklin era nel frattempo deceduta a 38 anni), realizzarono un modello credibile e
termodinamicamente possibile della molecola, modello che si è in seguito dimostrato
fondamentalmente corrispondente al vero.
La molecola del DNA consiste sempre in un lungo filamento (catena) che si appaia con un
filamento a esso complementare.
Quale è il significato chimico di questa complementarietà?
Ricordiamo che l’unica variabilità lungo la molecola di un singolo filamento è dovuta alla sequenza
delle basi azotate. Ricordiamo inoltre che le basi azotate presenti nel DNA (A, G, T, C) possono
legarsi tra di loro, con legami chimici deboli, solo così: A – T; G – C.
Riportiamo di seguito uno schema di una sequenza polinucleotidica:
.
.
.
P (acido orto fosforico)
Desossiribosio – A
P
Desossiribosio – G
P
Desossiribosio – T
P
Desossiribosio – C
P
.
.
.
Se due filamenti si legano tra di loro attraverso basi azotate avremo:
.
.
.
.
.
.
P
P
Desossiribosio – A………..T - Desossiribosio
P
P
Desossiribosio – G………..C - Desossiribosio
P
P
Desossiribosio – T..............A - Desossiribosio
P
P
Desossiribosio – C............. G - Desossiribosio
.
Ecco il significato di complementarietà: data una certa sequenza di basi su una catena, la sequenza
di basi sull’altra catena è chiaramente individuata dall’obbligo di legame chimico, come quattro
spine elettriche obbligate a unirsi solo come AT (AU nell’RNA) e CG: una sequenza sarà
complementare all’altra!! E’ questo un punto nodale nella comprensione del significato del DNA.
Per motivi spaziali e termodinamici, poi, le due catene complementari formano una struttura a
doppia elica che rassomiglia grosso modo a una scala a chiocciola: i pioli sono formati dalle due
basi complementari congiunte dai legami deboli (ponti a idrogeno), i sostegni laterali (che corrono
uno in un verso, l’altro nell’altro verso) sono formati dalle catene di desossiribosio e fosfato, come
si può vedere nelle immagini di seguito riportate (i pentagoni rappresentano il desossiribosio, le
tavolette le coppie di basi che uniscono le due eliche, le strutture laterali le molecole di acido
ortofosforico che uniscono tra loro il desossiribosio).
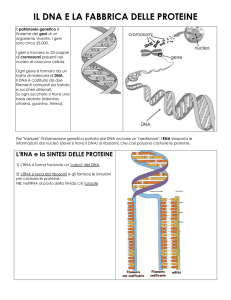
Duplicazione del DNA e Sintesi delle proteine.
Abbiamo esaminato la struttura delle proteine; constatato come un organismo è quello che è in virtù
del suo corredo proteico; appurato che la molecola ordinatrice degli amminoacidi lungo la catena
proteica è quella del DNA; rilevato che, quindi, un organismo è quello che è in funzione del suo
DNA; studiato come la molecola del DNA trovi la sua variabilità nella sequenza delle basi azotate
(quattro) lungo la catena di molecole di ribosio e acido fosforico. Come si connette, allora, la
struttura del DNA con quella delle proteine? Come interviene il DNA nella fabbricazione (sintesi)
delle proteine?
Duplicazione del DNA
Abbiamo visto che il DNA è il supporto chimico dell’informazione genetica contenente i geni; il
gene è una sequenza di molecola del DNA che racchiude le istruzioni necessarie alla fabbricazione
di una determinata proteina (un gene > un enzima). Queste informazioni non possono essere perdute
passando da una generazione cellulare all’altra, quindi il DNA, al momento della riproduzione
cellulare (una cellula > due cellule), deve potersi duplicare in due molecole identiche destinate alle
cellule figlie.
Al momento delle duplicazione le due catene complementari del DNA si separano e su ciascuna di
esse, che funge da stampo, si riforma la catena complementare, utilizzando le basi azotate che si
trovano nell’ambiente cellulare. I rapporti biochimici tra stampo e nuova catena sono rigidamente
stabiliti dall’obbligatorietà di legame tra basi azotate. Da una molecola di DNA si sono quindi
formate due molecole identiche tra di loro e alla molecola preesistente. Questo evento, di seguito
rappresentato, si verifica ogni volta che c’è una riproduzione cellulare, nei batteri come nell’uomo!
Duplicazione del DNA
Sintesi delle proteine
Abbiamo visto come il DNA, duplicandosi, assicuri la conservazione del patrimonio genetico nelle
generazioni cellulari.
Ma ormai sappiamo che la struttura delle proteine è univocamente legata a quella del DNA. Quindi
il DNA, duplicandosi, assicura anche la conservazione del patrimonio proteico lungo le linee
cellulari. Come avviene ciò?
Il DNA, oltre che duplicato, può essere trascritto e infine tradotto in proteine a livello molecolare.
Per prima cosa cerchiamo di capire come la molecola del DNA possa rappresentare un codice.
Rappresentiamoci le quattro diverse basi azotate, che sole conferiscono variabilità alla monotona
struttura molecolare del DNA, come quattro lettere di un alfabeto, e denominiamole, per comodità,
proprio A, T, G, C. Prefiguriamoci poi di dover identificare, dare un nome in codice, con queste
quattro lettere, a venti differenti amminoacidi. Ovviamente, è la successione delle quattro basi lungo
la doppia elica del DNA che fornisce la possibilità del codice ma, avendo a disposizione solo
quattro lettere, in teoria è possibile specificare, in una catena proteica, la posizione di soli quattro
amminoacidi (che sono 20). Se si raggruppano due a due le lettere del codice genetico si ottengono
16 combinazioni, ancora insufficienti. Ma se si raggruppano a tre a tre si hanno 64 combinazioni,
ampiamente sufficienti per dare un nome a tutti gli amminoacidi e per gli eventuali “segni di
punteggiatura” o regolazioni varie del messaggio genetico. Questi gruppi di tre lettere vengono
chiamati “triplette” o “codoni”. Ciascun codone, in funzione della sua posizione nella molecola del
DNA, specifica anche il posto di un amminoacido nella sequenza che costituisce una proteina. Il
codice genetico è lo stesso per tutto il mondo dei viventi: dal microbo all’uomo! A esempio, un
amminoacido come la metionina ha il codice (codone) ATG; l’amminoacido istidina ha due codoni:
CAT e CAC ( codice ridondante).
Questo codice universale, affinché il suo contenuto informativo possa essere utilizzato, deve prima
essere trascritto su sistemi molecolari di trasporto dell’informazione verso macchine cellulari che
provvedono alla traduzione dell’informazione per realizzare le strutture molecolari proteiche.
La cellula utilizza un marchingegno basato su tre elementi essenziali: una macchina trascrittrice che
copia l’informazione dal DNA formando un messaggio, una macchina traduttrice che traduce il
messaggio in proteina, un adattatore decodificatore.
Macchina trascrittrice - copiatrice: è l’enzima RNA polimerasi che, in funzione della sequenza di
basi (gene) di un tratto di singolo filamento di DNA (dove nel frattempo si sono separate le due
catene) copia (come da uno stampo) e costruisce un singolo filamento complementare di RNA
(RNA messaggero) che contiene tutta l’informazione del gene copiato necessaria per codificare una
proteina. E’ questa la trascrizione.
Esemplificando, se una data sequenza di basi lungo un singolo filamento di DNA è la seguente …
… AATACCTGGTATTGC… …, la RNA polimerasi trascriverà questa catena di RNA
(ricordiamo che nell’RNA al posto della Timina c’è l’Uracile) … UUAUGGACCAUAACG… …
Si è dunque formato un singolo filamento di RNA, non a caso denominato messaggero, che reca
alla macchina traduttrice un messaggio codificato, della lunghezza del gene trascritto.
Macchina traduttrice: è il ribosoma. Sono assai numerose nelle cellule (circa 10.000 in un
batterio, circa 50.000 nelle cellule animali e vegetali) e lavorano in serie, leggendo uno dopo l’altro
i messaggi portati dall’RNA messaggero e fabbricando le proteine, amminoacido dopo
amminoacido.
Adattatore decodificatore: si chiama RNA di trasporto e assicura il posizionamento di ciascun
amminoacido, così come è codificato dal messaggero, nella proteina in formazione. Interviene come
un dizionario tra i due linguaggi, quello dell’RNA e quello della proteina. Una delle sue estremità
possiede un decodificatore, una tripletta di basi (anticodone) che è complementare a una delle
triplette (codone) dell’RNA messaggero. L’altra estremità consiste in un adattatore legato a un
particolare amminoacido al quale si fissa in modo specifico. L’amminoacido legato è codificato da
un particolare codone dell’RNA e di conseguenza trova corrispondenza nell’anticodone di quel
RNA di trasporto. Ci sono tanti RNA di trasporto quanti sono i codoni per gli amminoacidi.
Affinché gli amminoacidi possano unirsi tra di loro devono essere attivati e collocati alla giusta
distanza. Tale assetto viene realizzato grazie al riconoscimento del codone e dell’anticodone. In
questo modo nessun amminoacido può prendere il posto di un altro.
Il ribosoma, vera macchina di montaggio delle proteine, assicura la meccanica d’insieme. Posiziona
l’RNA messaggero, lascia il posto per due RNA di trasporto, serve da matrice per far crescere
progressivamente la proteina in formazione e favorisce l’apporto di energia per il funzionamento
dell’intero meccanismo.
Schematizzando, la sintesi proteica procede nel seguente modo. Numerosi ribosomi percorrono il
filamento di RNA messaggero relativo a un gene, “leggendo” il messaggio che esso porta. Ciascun
RNA di trasporto – con il suo specifico amminoacido - si fissa temporaneamente su un ribosoma al
passare del codone corrispondente al suo anticodone, per poi lasciare il posto a quello successivo,
separandosi dal suo amminoacido che si lega, tramite legame carboammidico, all’amminoacido
trasportato dall’RNA di trasporto successivo. I vari RNA di trasporto, lasciati gli amminoacidi sul
ribosoma, ritornano a ricaricarsi del rispettivo amminoacido. Sul ribosoma si allunga la catena di
amminoacidi che infine va a costituire la proteina codificata dal gene che è stato trascritto e
tradotto.
Fabbrica immaginaria che produce proteine.
La cellula è la fabbrica che produce proteine. Il nucleo della cellula può essere rappresentato
dall’ufficio del direttore. In questo ufficio sono conservati i programmi (geni costituiti dal DNA)
per il montaggio dei diversi tipi di proteine che costituiscono l’intera produzione della fabbrica. Tali
progetti non lasciano mai l’ufficio della direzione. L’assemblaggio delle proteine è assicurato da
alcune macchine semiautomatiche programmate: i ribosomi.
Ecco lo svolgimento delle operazioni: su richiesta di vari reparti della fabbrica il programma (gene)
corrispondente a un particolare tipo di proteina viene cercato negli appositi cassetti dove è
conservato sotto forma di bande perforate o quant’altro (DNA). Abbiamo detto che gli originali non
lasciano mai l’ufficio del direttore (se deteriorati non potrebbero mai essere sostituiti e le
malformazioni di un programma sarebbero trasmesse indefinitamente alla corrispondente proteina
prodotta nella fabbrica). Allora una o varie copie del programma richiesto vengono ricavate dalla
RNA polimerasi, per trascrizione, in una forma facilmente maneggiabile (RNA messaggero) e
inviate in fabbrica. Nel messaggero sono contenute le istruzioni del gene conservato nel cassetto,
che servono a programmare le macchine – ribosomi dove vengono assemblate le proteine.
Venti sono i pezzi (amminoacidi) differenti che entrano nella composizione delle proteine; questi
pezzi si trovano nel magazzino della fabbrica e ogni magazziniere (RNA di trasporto) è
responsabile di un particolare pezzo. Via via che alla macchina arriva il codice di un pezzo, il
magazziniere specifico per quel pezzo va a prenderlo nel magazzino e lo porta alla macchina
ribosoma.
La macchina viene alimentata con pezzi separati che vengono uniti uno di seguito all’altro (legame
carboammidico) e la proteina che viene prodotta è conforme al programma introdotto nella
macchina, che compie così la funzione di traduzione del programma medesimo.
Così abbiamo capito come una variazione nella sequenza delle basi del DNA può portare a
codificare per amminoacidi diversi e di conseguenza a proteine diverse e quindi a diversi enzimi e
pertanto a diverse strutture molecolari.!!









![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)

