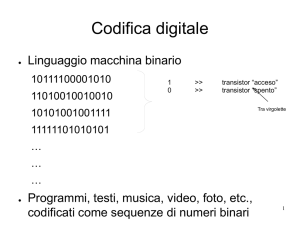
Teoria dell’informazione: ottimizzazione di codice.
Introduzione. La teoria dell’informazione ha per oggetto lo studio delle leggi matematiche che
regolano l’elaborazione e la trasmissione dell’informazione. In particolare, essa sistematizza i
metodi di misurazione e rappresentazione dell’informazione (codifica) e formula relazioni fra
variabili matematiche per ottenere un utilizzo ottimale dei sistemi di comunicazione nella
trasmissione dei messaggi.
La teoria dell’informazione riguarda tutte le forme di trasmissione e memorizzazione di messaggi,
comprese la televisione e le registrazioni magnetiche e ottiche dei dati. Essa interessa campi
estremamente eterogenei come la cibernetica, la crittografia, la linguistica, la psicologia e la
statistica. L’informazione, ovvero l’insieme dei messaggi trasmessi, può essere costituita da voce o
musica trasmesse per telefono o radio, da immagini diffuse con sistemi televisivi, da dati digitali
trasferiti attraverso le reti di comunicazione, ma anche dagli impulsi nervosi degli organismi
viventi.
Note storiche. Il nucleo della teoria dell’informazione fu elaborato nel 1948 dall’ingegnere
elettrotecnico statunitense Claude E. Shannon. L’intenso sfruttamento dei canali di comunicazione,
quali le reti telefoniche e i sistemi di radiocomunicazione, iniziato negli anni Trenta e continuato nel
dopoguerra, poneva in primo piano la necessità della messa a punto di sistemi sempre più efficaci
per la trasmissione dei messaggi. Si deve a Shannon la prima espressione di un sistema per la
generazione e trasmissione delle informazioni in forma di modello, che comprende una sorgente
dell’informazione, un codificatore, un canale di trasmissione, un decodificatore e un destinatario
(od osservatore), il quale, rilevando, interpretando e utilizzando l’informazione per fini propri,
interagisce con essa, contribuendo in parte a determinarne il contenuto trasferito.
Misura dell’informazione. Il contenuto informativo di un messaggio è legato alla sua probabilità
di mostrarsi entro un insieme di messaggi possibili: maggiore è la probabilità di realizzarsi, minore
è il contenuto informativo. È abbastanza intuitivo che sarà il messaggio meno probabile, fra diverse
alternative, a portare la massima quantità d’informazione quando si verificherà, mentre il contenuto
informativo di un messaggio atteso con certezza è 0.
Esempio 1: lancio di una moneta. Indipendenza degli eventi ed equiprobabilità, introduzione del bit
come unità d’informazione binaria ed esempio di codifica.
Quando lancio una moneta il messaggio “testa o croce” descrive il risultato, ma non ha contenuto
informativo, mentre i due messaggi distinti “testa” oppure “croce” sono ugualmente possibili, cioè
equiprobabili, con probabilità pari a ½, e da quanto detto finora dovrebbero portare il massimo
dell’informazione. Inoltre facendo due lanci successivi essi sono indipendenti tra loro, cioè il
secondo lancio non dipenderà da quello che è uscito al primo lancio. Nel nostro esempio, se “croce”
è rappresentato da 0 e “testa” da 1, il messaggio può essere rappresentato per mezzo dei due soli
simboli 0 e 1, ovvero mediante le cifre del sistema binario; la scelta tra questi simboli corrisponde
alla cosiddetta unità di informazione binaria, o bit. Se la moneta viene lanciata tre volte di fila, ho 8
= 23 risultati (o messaggi) equiprobabili rappresentabili come 000, 001, 010, 011, 100, 101, 110 o
111. Questi messaggi corrispondono ai numeri 0, 1, ..., 7 scritti in notazione binaria. La probabilità
di occorrenza di ogni messaggio è di un ottavo, quale sarà invece il contenuto informativo, cioè la
quantità d’informazione? Per ora possiamo solo dire che:
p
1
8
q
1
Quantità di informazione q inversamente proporzionale a p.
p
Esempio 2: alfabeto inglese. Supponendo di essere in una trasmissione di un impulso attraverso un
canale di comunicazione idealmente privo di errori. Trasmettiamo una lettera dell’alfabeto inglese
(26 simboli) da una sorgente binaria. Supponiamo che ogni simbolo sia equiprobabile (anche se
nella realtà non è così), avremo che la probabilità di occorrenza di ogni simbolo nel messaggio è:
p
1
26
q
con
1
bit
p
Matematicamente abbiamo quindi bisogno di una legge che possa esprimere la relazione tra
quantità d’informazione e probabilità di occorrenza dell’evento messaggio.
Avendo un numero di simboli N = 2m, con m intero, per ogni simbolo occorrono m bit (quantità
d’informazione). Ricordando che logaan = n
q = m = logaan = log22m = log2N = log2
1
= - log2 p
p
q = log2
1
= - log2p
p
Quindi negli esempi delle monete q = 1/8 bit e nell’esempio dell’alfabeto inglese q = log2
1
= 4.70
26
bit. Dati N simboli equiprobabili (p= 1/N):
I = n log2
1
= n log2 N bit
p
Quantità d’informazione necessaria per trasmettere n simboli.
Entropia. Precedentemente abbiamo supposto l’equiprobabilità e l’indipendenza dei simboli
trasmessi. Negli alfabeti linguistici in realtà non avviene questo. In un testo scritto in italiano ad
esempio è più semplice imbattersi nelle vocali i, a, e, o piuttosto che nelle consonanti q oppure z.
Dati N simboli non equiprobabili
Qi = - log2pi bit
Quantità d’informazione per ogni simbolo dove pi
sono le probabilità di ogni simbolo.
Da qui si calcola la media pesata
N
H pi log 2
i 1
N
1
pi log 2 pi bit/simbolo
p
i 1
Entropia
2
H è detta entropia, cioè la quantità media d’informazione associata ad ogni simbolo emesso da una
sorgente
Esempio 3: una sorgente emette una sequenza di quattro simboli A, B, C, D
Probabilità simbolo
p(A) = 0,0625
Qi
QA = - log2 0.0625 = 4 bit
p(B) = 0.25
QB= - log2 0.25 = 2 bit
p(C) = 0.25
QB = - log2 0.25 = 2 bit
p(D) = 0.4375
QB = - log2 0,4375 = 1.19 bit
Entropia
H = 0.0625∙ 4 + 0.025∙2 +
+0.25∙2 + 0.4375∙1.19 =
1.77 bit/simbolo
Se la sorgente emette messaggi equiprobabili, l’entropia della sorgente diventa massima:
H Max
I
log 2 N
N
Codifica di sorgente e ottimizzazione di codice. Chiamata parola ogni sequenza di bit
rappresentante un simbolo del codice utilizzato dalla sorgente, supposta binaria, il codice deve
essere tale che il ricevitore distingua una parola dall’altra. Allora ogni parola deve essere:
a) riconoscibile tra quelle che appartengono al codice stesso
b) identificabile indipendentemente dalla posizione che occupa nel messaggio
Esempio 4: A = 11, B = 0, C = 1, D = 00, E = 11
A ed E non rispettano a)
Esempio 5: A = 0, B =1, C = 10, D = 00 E = 11
non rispettano b). Infatti
ED
BCA
EAA
BBD
BBAA
1100
Esempio 6:
A = 001, B = 110, C = 010, D = 100, E =111 rispetta le due condizioni.
E’ a lunghezza fissa Facilmente decodificabile dal ricevente.
Domanda: quando una codifica è ottimale? Per rispondere dobbiamo prima introdurre il concetto di
bontà di codice definendo la sua lunghezza come la lunghezza media delle sue parole.
N
L p ( si ) Li bit/parola
dove Li numero bit della parola si con probabilità di occorrenza p(si).
i 1
Esempio 7. Nell’esempio 6 essendo a lunghezza fissa e con simboli equiprobabili, L = 5(1/5*3) =3.
Ridondanza. Nell’esempio numero 3 abbiamo che H = 1.77 bit/simbolo, se noi indichiamo con
HMax la massima quantità di informazione si ha HMax = log 4 = 2 bit/simbolo. Con un codice binario
posso codificare con m bit, 2m simboli, cioè sono necessari m = 2 = HMax bit, superiore all’effettiva
3
quantità d’informazione necessaria H, quindi la sorgente emette una percentuale di bit
sovrabbondante (ridondanza), occupando inutilmente il canale di comunicazione.
R= 1 -
H
H Max
Esempio 8. Se si trasmettono messaggi che consistono in combinazioni casuali delle 26 lettere
dell’alfabeto inglese, del segno di spazio e cinque segni di interpunzione(:;,’.), e se si assume che la
probabilità di ogni messaggio sia la stessa, l’entropia è data dall’espressione H = log232 = 5. Sono
necessari quindi cinque bit per codificare ogni carattere: 00000, 00001, 00010, ..., 11111. Può
accadere che il numero di simboli necessari per trasmettere e memorizzare in modo efficace
l’informazione sia inferiore a quello ottenuto con la valutazione dell’entropia del sistema: è quindi
necessario ridurre il numero di bit usati per la codifica. Questo è possibile nell’elaborazione dei
testi, ad esempio, poiché la distribuzione delle lettere dell’alfabeto non è completamente casuale (ad
esempio, alcune sequenze di lettere sono più probabili di altre).
Esempio 9. Il codice Morse codifica le parole di una lingua in punti e linee. Partendo, in questo
caso, dalla conoscenza della distribuzione di probabilità delle lettere nella lingua inglese, si è deciso
di codificare la lettera e, che è la più probabile, con un solo punto , mentre la q , che è la meno
probabile, è codificata con due linee un punto una linea (--.-). Naturalmente, dato che il codice
Morse è stato concepito pensando alla lingua inglese, non è detto che esso sia molto efficiente
quando il messaggio da codificare è scritto in un'altra lingua.
Esempio 10. In generale il linguaggio comune è molto ridondante. È proprio questa ridondanza che
permette ad una persona di capire messaggi lacunosi o di decifrare una calligrafia poco chiara.
Pensando all'uso che la lingua italiana fa della lettera `q' che è sempre seguita da una `u': nessuno
avrebbe difficoltà nel capire il significato della parola ``q*adro'', nonostante essa non sia scritta
correttamente. La presenza di ridondanza in una lingua, in un testo scritto, o in una qualunque
stringa di simboli non è però negativa, anzi, essa svolge il compito fondamentale di rendere robusto
il messaggio contenuto in quella stringa. Nei moderni sistemi di comunicazione si parla di
ridondanza artificiale per indicare quella ridondanza che viene introdotta di proposito nei messaggi
codificati per ridurre gli errori di trasmissione.
Efficienza e ottimalità. Una caratteristica fondamentale di un codice è la sua efficienza che è pari
al rapporto tra l’entropia e la lunghezza media:
H
L
In un codice ottimale η si avvicinerà a 1
La ridondanza può essere scritta come
R 1 1
H
L
In un codice ottimale R si avvicinerà a 0
L’ottimizzazione di codice: algoritmo di Huffman. Il codice di Huffman è un codice
univocamente decodificabile a prefisso. Questo significa che nessuna parola del codice è il prefisso
di un'altra parola del codice stesso, fatto molto comodo perché, in fase di decodifica, consente di
evitare perdite di tempo.
4
Esempio 11. Supponiamo di avere un codice non univocamente decodificabile in cui esistono le due
parole 10 e 100; quando il decodificatore ha letto le prime due cifre si trova a dover
necessariamente aspettare di vedere la terza per sapere di quale parola si tratta, in quanto 10 è un
prefisso di 100. Questa attesa del decodificatore si chiama ritardo di decodifica e si manifesta ogni
qualvolta non sia possibile riconoscere una parola di codice subito dopo aver letto la sua ultima
lettera.
Per ottenere la codifica di Huffman costruiamo un albero. E’ necessario disporre di simboli, o
blocchi, da codificare e delle loro probabilità. Nell'esempio che consideriamo abbiamo un alfabeto
di 6 simboli e partiamo dalla seguente distribuzione di probabilità:
Lettera
A
B
C
D
E
F
Totale
Probabilità 0.025 0.0.35 0.040 0.20 0.30 0.40 1.00
Possiamo ora descrivere l'algoritmo di Huffman. Si dispongono le singole unità fondamentali (che
possono essere lettere o blocchi di caratteri) in ordine di probabilità decrescente. Si attribuisce il
valore 0 al primo bit di A e 1 al primo bit di B. Si uniscono le due unità aventi le due probabilità
minori in un nuovo blocco cui viene assegnata la somma delle probabilità delle unità che lo hanno
formato; se questa è maggiore della successiva viene assegnato 1, 0 altrimenti. Si va avanti fino a
che non abbiamo raggiunto in cima all’albero 1 che deve essere per forza la somma di tutte le
probabilità. Vedi schema a seguire
5
Albero di Huffman
1
1
PE +PD + PC + PB + PA = 0.60 > PF
0
PD + PC + PB + PA = 0.30 < =PE
0
Verso
lettura
codice
0
Verso
costruzione
codice
1
PC + PB + PA = 0.10 < PD
1
1
0
PB+PA = 0.060 > PC
1
PF = 0.40
A 10010
B 10011
C 1000
D 101
E 11
F 0
PE = 0.30
PD = 0.20
PC = 0.040
PB = 0.035
0
PA = 0.025
N.B:
a) Nessuna parola di codice è il prefisso di un'altra parola
b) Alle parole meno probabili sono stati assegnati più bit
che a quelle più probabili
c) esistono molti metodi per costruire un albero di
Huffman. Abbiamo illustrato quello dall’approccio più
semplice
6
Assegnazione esercizi per casa
1) Una sorgente binaria emette sette simboli A B, C, D, E, F, G le cui probabilità di occorrenza pi
sono riportate nella seguente tabella con le rispettive codifiche. Determinare:
a) L’entropia di sorgente
b) Il contenuto informativo del messaggio m = ACAEFC
c) La lunghezza media L, l’efficienza e la ridondanza di codice
Simbolo
A
B
C
D
E
Probabilità 0.30 0.23 0.20 0.11 0.08
Codifica
00
01
10
F
G
0.06
0.02
110 1110 11110 11111
2) Una sorgente binaria emette cinque simboli A B, C, D, E, F, G le cui probabilità di occorrenza pi
sono riportate nella seguente tabella con le rispettive codifiche. Determinare:
a) la codifica secondo l’algoritmo di Huffmann
b) Il contenuto informativo del messaggio m = ACAEC
c) La lunghezza media L, l’efficienza e la ridondanza di codice
Simbolo
A
B
C
D
E
Probabilità 0.08 0.11 0.16 0.26 0.39
8.2 II Fase (mezz’ora frontale per la correzione con gli studenti degli esercizi svolti per casa)
Esercizio1
N
H pi log 2 pi -0.30∙log20.30 - 0.23∙log20.23 - 0.20∙log20.20 - 0.11∙log20.11 i 1
0.08∙log20.08 – 0.06∙log20.06 - 0.02∙log20.02 = 2.471 bit/simbolo.
La probabilità di m = ACAEFC è data dal prodotto delle probabilità di ogni parola.
P(m) = 0.30∙0.20∙0.30∙0.08∙0.06∙0.20 = 1.728 10-5
Il contenuto informativo Q(m) = - log2 P(m) =15.82 bit
Q(m) =15.82 bit > 6∙H = 6∙2.471 = 14.826 bit
Contenuto maggiore rispetto alla
quantità d’informazione media
Lunghezza media codice
N
L p ( si ) Li =0.30∙2 + 0.25∙2 + 0.20∙2 + 0.11∙3 + 0.08∙4 + 0.06∙5 + 0.02∙5 = 2.55 bit/simbolo
i 1
H 2.471
0.969
L
2.55
Efficienza codice
Ridondanza
R=1-
96.9%
H
= 1-0.969 = 0.031
L
3.1%
Esercizio 2
La codifica di Huffmann secondo schema precedente ad albero A = 1010, B = 1011, C = 100, D =
11, E = 0.
7
N
H pi log 2 pi -0.39∙log20.39 - 0.26∙log20.26 - 0.16∙log20.16 - 0.11∙log20.11 i 1
0.08∙log20.08 = 2.1 bit/simbolo.
P(m) = 0.39∙0.16∙0.39∙0.08∙0.16 = 3.11 ∙ 10-4
Q(m) = - log2 P(m) =11.548 bit > 5∙H = 5∙2.1 = 10.5 bit
Contenuto maggiore rispetto alla
quantità d’informazione media
Lunghezza media codice
N
L p ( si ) Li =0.39∙1 + 0.26∙2 +0.16∙3 + 0.11∙4 + 0.08∙4 = 2.15 bit/simbolo
i 1
H
2.1
0.9767 97.67 %
L 2.15
H
Ridondanza R = 1 = 1-0.9767 = 0.0233 2.33%
L
Efficienza codice
Spunti per un approfondimento.
L’utilizzo dell’algoritmo di Huffman nella compressione dati. L’algoritmo di Huffman nelle sue
varianti è utilizzato per la compressione dei dati, cioè per quella tecnica preposta alla riduzione del
numero di bit necessari per immagazzinare un'informazione, generalmente applicata per ridurre le
dimensioni di un file. Le varie tecniche di compressione cercano di organizzare in modo più
efficiente le informazioni al fine di ottenere una memorizzazione che richieda minor uso di risorse
(memoria e velocità di trasmissione). Visto il crescente utilizzo di materiale multimediale è utile
essere consapevoli del fatto che molto di questo materiale è compresso utilizzando principi in
precedenza. Possiamo introdurre genericamente le seguenti due grandi categorie delle tecniche di
compressione.
Lossy: i dati sono compressi attraverso un processo con perdita d'informazione che sfrutta le
ridondanze nell'utilizzo dei dati. Le tecniche con perdita di informazione ottengono delle
compressioni molto spinte dei file a scapito dell'integrità del file stesso. Il file prima della
compressione e il file dopo la decompressione sono simili ma non identici. Normalmente è
utilizzata per comprimere i file multimediali. I files multimediali in origine sono troppo grandi
perché possano essere agevolmente trasmessi o memorizzati quindi si preferisce avere una piccola
riduzione della qualità, ma nello stesso tempo files più leggeri. Esempi di queste tecniche sono le
immagini in formato JPEG o il formato MP3 per i brani musicali.
Es.
L’occhio umano non
coglie la differenza
Utilizzo di 64 grigi
Utilizzo di 256 grigi
8
Lossless: i dati sono compressi attraverso un processo senza perdita d'informazione che sfrutta le
ridondanze nella codifica del dato. Un loro esempio è il formato ZIP per i files o il GIF per le
immagini. A partire da un file in uno di questi formati, è sempre possibile ricostruire esattamente il
file d'origine.
Si sottolinea come l’algoritmo di Huffman fa parte delle tecniche lossless, anche se è utilizzato
frequentemente all’interno di tecniche più complesse di tipo lossy. Ad esempio nella riduzione dei
files musicali in formato MP3 esso è associato a tecniche di codifica percezionale, ossia basate sul
“tagliare” suoni non percepibili all’orecchio umano).
Testi di riferimento (bibliografia, sitografia)
Langella L.- Giuliano G. - Pojana G.- Scaccianoce R.: Informatica e sistemi automatici, Milano Edizioni Calderini, 2004
http://pil.phys.uniroma1.it/~baronka/tesi_laurea/node25.html
http://www.dia.unisa.it/~ads/TesineAsd2/Introduzione.htm,
http://www.beta.it/beta/bs019598/0496/b496grf1.htm
http://office.microsoft.com/it-it/excel/default.aspx
9
Simulazione su foglio excel
Utilizzando le conoscenze viste a lezione, date le probabilità di sei simboli A, B, C, D, E, F come da celle
B3-B8, costruire il foglio Excel in figura utilizzando le formule adatte e le proprietà di calcolo automatico
del foglio elettronico. Le soluzioni sono in allegato 1. Si richiede cioè
Problema 1
1.
2.
3.
4.
5.
6.
La quantità d’informazione per simbolo
La costruzione dell’albero di Huffman con relativa codifica
Il numero di bit per simbolo
La bontà del codice, l’entropia della sorgente, l’efficienza e la ridondanza di codice
Il codice ASCII per ciascuna lettera del messaggio (decimale e binario)
Data una codifica su 3 bit (celle K18-K23) notare l’evidente efficienza dell’algoritmo di Huffman
rispetto ad essa.
Problema 2
Dato il messaggio FFEABCDBACDEEFFF
1.
2.
3.
4.
Separare ciascuna lettera del messaggio
Calcolare l’occorrenza per simbolo e il totale dei simboli
Calcolare la frequenza di ogni simbolo.
Calcolare secondo la codifica di Huffman del problema 1 la quantità d’informazione e la probabilità
dell’intero messaggio
5. Scrivere in un'unica stringa il messaggio secondo Huffman
Nel caso siate in difficoltà nel reperimento di alcune formule utilizzate la guida in linea di Excel o consultate
http://office.microsoft.com/it-it/excel/default.aspx
10
Allegato 1 : soluzione per le formule più significative utilizzate nel foglio elettronico (si riportano
soltanto quelle iniziali per quelle copiate tramite trascinamento e riempimento automatico).
Cella
D3
F8
G8
H8
I8
F6
G5
H4
I3
J3
K3
L3
M3
N3
M11
M12
M13
B14
C14
B20
B21
D21
B24
C24
F33
Formula
- LOG(B3;2)
SE(($B$8+$B$7)>$B$6;1;0)
SE(($B$8+$B$7+$B$6)>$B$5;1;0)
SE(($B$8+$B$7+$B$6+$B$5)>$B$4;1;0)
SE(($B$8+$B$7+$B$6+$B$5+$B$4)>$B$3;1;0)
SE(($B$8+$B$7)>$B$6;0;1)
SE(($B$8+$B$7+$B$6)>$B$5;0;1)
SE(($B$8+$B$7+$B$6+$B$5)>$B$4;0;1)
SE(($B$8+$B$7+$B$6+$B$5+$B$4)>$B$3;0;1)
CONCATENA(I3;H3;G3;F3;E3)
(LUNGHEZZA(J3))
B3*K3
CODICE(C3)
DECIMALE.BINARIO(M3;8)
B3*(LOG(1/B3;2))+B4*(LOG(1/B4;2))+B5*(LOG(1/B5;2))+
+B6*(LOG(1/B6;2)+B7*(LOG(1/B7;2))+B8*(LOG(1/B8;2))
$M$11/L9*100
100-M12
LUNGHEZZA($A$12)LUNGHEZZA(SOSTITUISCI($A$12;A14;""))
B14/$B$20
LUNGHEZZA(A12)
PRODOTTO(C14:C19)
-LOG(C21;2)
STRINGA.ESTRAI($A$12;A24;1)
SE(B24=$C$3;$J$3;SE(B24=$C$4;$J$4;SE(B24=$C$5;$J$5;
SE(B24=$C$6;$J$6;SE(B24=$C$7;$J$7;SE(B24=$C$8;$J$8;
" "))))))
=CONCATENA(C24;C25;C26;C27;C28;C29;C30;C31;C32;
C33;C34;C35;C36;C37;C38;C39;C40;C41;C42;C43)
Intestazione
Quantità d’informazione
per simbolo
Costruzione albero
Codifica del simbolo
Numero bit simbolo
Lunghezza parole
ASCII
ASCII binario
Entropia
Efficienza
Ridondanza
Occorrenza per lettera
Frequenza
Totale lettere
Probabilità messaggio
Informazione messaggio
Lettera
Codifica
Codifica messaggio
11