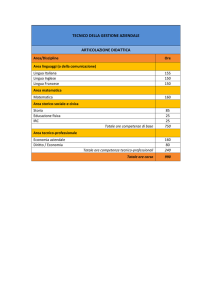
15.1 Introduzione
Un computer è una macchina a stati in grado di eseguire delle
operazioni aritmetico-logiche sui dei dati di ingresso e fornisce dei
risultati. La logica con la quale il sistema elabora i dati di ingresso
(input) per fornire dei risultati (output) è definita da quello che viene
detto programma.
Generalmente un programma (applicazione, file binario,
eseguibile, script) nasce dallʼesigenza di trovare la soluzione ad un
determinato problema (o classe di problemi) anche se i motivi che
spingono i programmatori a scrivere i programmi possono essere
molteplici: dal mero interesse pecuniario, allʼattrazione per la sfida
(posta dal problema da risolvere), alla voglia di apprendere (sia
perché le tecnologie sono sempre in evoluzione, sia perché i
programmi possono essere scritti per vari scopi e quindi possono
coinvolgere varie discipline, dalla grafica allʼaudio, alla gestione dei
dati, allʼintelligenza artificiale, ...), alla voglia di creare qualcosa che
possa essere utile per sé ed anche per altri.
15.2 Gli algoritmi ed i programmi
Il PC è una macchina programmabile, ovvero che è in grado di
elaborare dei dati in funzione di una determinata logica definita da
qualcuno. La descrizione della logica in base alla quale il sistema
deve elaborare i dati è detta algoritmo1 e consiste in un numero
finito di passi da seguire per arrivare alla soluzione. Un algoritmo può
essere espresso in varie forme, ma quelle più utilizzate sono
essenzialmente due: il linguaggio naturale, o il diagramma a blocchi.
Ad esempio, si considerino gli esempi riportati di seguito relativi ad un
algoritmo che visualizza il massimo tra due valori inseriti, il primo è
descritto col linguaggio naturale, mentre il secondo è un diagramma a
blocchi (in tali esempi a e b sono i valori inseriti).
Esistono essenzialmente due tipi di approccio per la stesura di un
algoritmo che hanno caratteristiche opposte
top-down è lʼapproccio più classico. È il metodo secondo il
quale chi scrive lʼalgoritmo deve avere da subito unʼidea della
struttura dellʼalgoritmo stesso: la stesura dellʼalgoritmo inizia dal
suo inizio e procede sequenzialmente fino ad arrivare alla fine;
bottom-up è lʼapproccio nato per la stesura di algoritmi relativi
a problemi più complessi. Si basa sul motto latino “divide et
impera”, ovvero il problema viene spezzato in sottoproblemi più
facili da risolvere e si inizia a stendere lʼalgoritmo per questi.
Quindi si combinano insieme le varie parti fino ad ottenere
lʼalgoritmo che risolve il problema nel suo complesso.
Nella realtà per la stesura di un algoritmo si fa generalmente uso di
entrambe le due tecniche: per lo sviluppo delle parti per le quali è
necessario avere una visione dʼinsieme del problema si utilizza la
tecnica top-down, mentre per sviluppare le parti per le quali si sente
più lʼesigenza di concentrarsi sul dettaglio, si utilizza la tecnica
bottom-up.
Un algoritmo, sia esso espresso in linguaggio naturale che
sottoforma di diagramma a blocchi, descrive i passi necessari per la
soluzione di un problema, ma non è comprensibile da un computer. A
tal fine esso deve essere trasformato in un programma. Un
programma infatti non è altro che lʼimplementazione di un algoritmo in
un linguaggio comprensibile allʼelaboratore, cioè una sequenza finita
ed ordinata di istruzioni eseguibili in un tempo finito.
La CPU è in grado di comprendere solo un particolare insieme di
istruzioni: il linguaggio macchina (o codice macchina) composto
da particolari sequenze di valori binari. Scrivere un programma in
linguaggio macchina non è né pratico né agevole. Ecco quindi che
sono nati i linguaggi di programmazione, dei linguaggi intermedi,
molto vicini al linguaggio naturale (rispetto al linguaggio macchina),
che rendono più facile la vita al programmatore. Una volta scritto un
programma con il linguaggio di programmazione desiderato esistono
degli appositi programmi che fanno la “traduzione” del programma in
linguaggio macchina, in maniera da renderlo comprensibile alla CPU
e, quindi, eseguibile.
Esistono essenzialmente due metodi per effettuare la traduzione di
un programma in linguaggio macchina: lʼinterpretazione e la
compilazione, che si basano su tecniche diverse descritte di seguito.
Un programma è generalmente memorizzato sul file system
allʼinterno di uno o più file, detti file sorgenti, che contengono quello
che viene definito appunto il codice (sorgente) del programma, cioè il
programma scritto nel linguaggio di programmazione scelto.
15.2.1 Lʼinterprete
Lʼinterprete è un programma in grado di tradurre in linguaggio
macchina e fare eseguire un file sorgente scritto in un particolare
linguaggio di programmazione. Ovviamente ogni interprete sarà in
grado di tradurre i programmi scritti nel linguaggio di programmazione
che esso comprende.
Lʼinterprete legge, traduce e fa eseguire alla CPU le istruzioni
presenti nel file sorgente, una dopo lʼaltra. Questo implica il fatto che
è necessario che lʼinterprete sia presente ed in esecuzione sul
sistema ogni volta che il programma deve essere eseguito, poiché
altrimenti la CPU non sarebbe in grado di eseguire il file sorgente: è
scritto in un linguaggio che essa non comprende.
Di seguito sono elencati i vantaggi e gli svantaggi dellʼutilizzo di un
interprete
• lʼinterprete deve necessariamente essere eseguito ogni volta
che deve essere eseguito il programma;
• durantre lʼesecuzione del programma la memoria del sistema
viene occupata sia dallʼinterprete (che deve essere
necessariamente eseguito) che dal programma da eseguire;
• poiché lʼinterprete traduce e fa eseguire alla CPU istruzione
per istruzione il programma, il tempo di esecuzione di ogni
istruzione è sovraccaricato dal tempo di traduzione
dellʼistruzione stessa. Il risultato è quello di avere tempi di
esecuzione più alti rispetto a quelli effettivamente necessari
allʼesecuzione dellʼistruzione da parte della CPU;
• lʼutilizzo dellʼinterprete rende molto snella ed immediata
la gestione della correzione e verifica dei programmi in fase di test;
15.2.2 Il compilatore
Il compilatore è un programma in grado di tradurre in linguaggio
macchina uno o più file sorgenti scritti in un particolare linguaggio di
programmazione. Esso fornisce come output un file eseguibile. Tale
file è il risultato della traduzione dei file sorgenti ed è quindi
direttamente comprensibile dalla CPU. Quindi per la sua esecuzione
non è necessario avere il compilatore.
La compilazione scinde la fase di traduzione delle istruzioni contenute
nei file sorgenti da quella di esecuzione. Essa è relativa soltanto alla
fase traduzione di un programma in linguaggio macchina ma non è
legata in alcun modo alla sua esecuzione. In particolare, la
compilazione di un programma si compone di due fasi distinte
(v. fig. 15.5):
compilazione è la fase di traduzione dei file sorgenti in
linguaggio macchina e fornisce come risultato dei file intermedi
detti file oggetto che non sono comprensibili dal sistema, ma
servono per la fase di linking;
linking è la fase di collegamento (link) dei file oggetto e delle
librerie (statiche) per la produzione del file eseguibile;
In genere un programma si appoggia a delle librerie di sistema (ed
eventualmente anche a delle librerie specifiche) per poter essere
avviato, terminato ed eseguito. Il codice eseguibile presente in tali
librerie deve essere inserito nel file eseguibile, risultato della
compilazione del programma, in maniera tale che il file stesso risulti
indipendente.
Di seguito sono elencati i vantaggi e gli svantaggi dellʼutilizzo di un
compilatore
• il compilatore è necessario soltanto in fase di traduzione dei
file sorgenti, non durante lʼesecuzione del programma. Il tempo
di compilazione è generalmente non trascurabile;
• durante lʼesecuzione del programma la memoria del sistema
viene occupata soltanto dal programma da eseguire;
• poiché il file eseguibile prodotto dalla compilazione è già
comprensibile dalla CPU, il tempo di esecuzione è quello
strettamente necessario allʼesecuzione delle istruzioni. Non ci
sono tempi morti durante lʼesecuzione;
• lʼutilizzo del compilatore rende un poʼ lenta la gestione della
correzione e verifica dei programmi in fase di test (perché il
tempo di compilazione può essere lungo);
15.3 I metodi di programmazione
Scrivere programmi è unʼattività delicata poiché sebbene sia
relativamente facile scrivere programmi, è difficile scrivere buoni
programmi. Un buon programma non è quello che funziona, ma
quello che, oltre a funzionare, permette unʼagevole manutenzione. Di
seguito sono elencate delle regole generali utili per la scrittura di
buoni programmi, anche se lʼesperienza e le capacità del
programmatore rimangono comunque i fattori determinanti della
bontà di un programma.
Quando si scrivono programmi, oltre a conoscere bene il
linguaggio di programmazione utilizzato (la sua sintassi, le sue
funzioni, ...) la prima cosa da non sottovalutare è la leggibilità del
codice. Al computer non importa affatto della leggibilità del codice,
ma è sufficiente che non vi siano errori di sintassi per poter eseguire
il programma. Bisogna però considerare che quel programma andrà
manutenuto o comunque eventualmente corretto e quindi la sua
correzione (che potrebbe avvenire anche in un momento piuttosto
distante da quello di termine dei lavori o da persone diverse da quelle
che lo hanno scritto) risulterà di gran lunga agevolata quanto più sarà
facile comprenderne il codice. A tal fine, oltre ad essere
estremamente
consigliato
lʼutilizzo
di
un
linguaggio
di
programmazione ad alto livello, si possono utilizzare vari espedienti,
come lʼuso di nomi esplicativi di varibili e funzioni (v. sez. 15.4), lʼuso
adeguato di commenti e dellʼindentazione2 delle istruzioni, ...
Per migliorare la leggibilità del codice è anche opportuno seguire
le regole della programmazione strutturata3. Il riutilizzo di porzioni
di codice già scritte è da incoraggiare, ma ciò non deve andare a
scapito della comprensibilità del codice. In pratica, si tratta di
eliminare i salti nellʼordine di esecuzione del codice a blocchi di
istruzioni scritti qua e là nel programma (questo generalmente viene
fatto con istruzioni tipo goto4), preferendo una logica di esecuzione
sequenziale ed utilizzando costrutti più vicini alla logica umana, come
quelli seguenti
istruzioni condizionali - costrutto if ... then ... else se la
condizione X è vera
allora
esegui
le seguenti
istruzioni ... altrimenti esegui le seguenti istruzioni ...
cicli di istruzioni - costrutto do ... while (o ciclo for) s
e la
condizione X è vera esegui le seguenti istruzioni ... ritorna ad
eseguire il flusso del programma a partire dallʼistruzione “se la
condizione X è vera ...”
La sintassi dei linguaggi ad alto livello contiene questi tipi di costrutti,
che aiutano a rendere più agevole e chiara la scrittura del codice.
Esiste comunque anche un uso dei salti di esecuzione allʼinterno del codice che va incontro
programmi. Questo accade quando tale istruzione è utilizzata per uscire dai cicli (anche annidati),
per tale esigenza.
Parti di codice indipendenti e già collaudate, che devono essere
riusate spesso nei programmi, possono essere utilizzate per formare
delle librerie (ovvero scritte e compilate una volta per tutte e messe a
disposizione per ulteriori utilizzi).
Inoltre, quando ci si accinge a scivere un programma è opportuno
chiedersi se qualcunʼaltro si sia già scontrato con il problema che si
tenta di risolvere, in modo da poterne eventualmente riutilizzare parte
del codice (che magari è anche già testato).
Sempre nellʼottica di migliorare la riusabilità del codice, la sua
comprensione e manutenibilità, è stata introdotta negli anni ʼ90 la
programmazione ad oggetti (OOP - Object Oriented Programming)
che estende il concetto classico di programmazione funzionale (o per
funzioni), suddividendo il programma in un insieme di oggetti
indipendenti di più facile manutenzione che possono essere riutilizzati
in altri programmi, come blocchi precostruiti, agevolandone la
realizzazione. Sono così nati i linguaggi di programmazione ad
oggetti (come il Java, il C++, lʼEiffel, ...) che permettono la scrittura di
codice ad oggetti. In particolare, la programmazione ad oggetti ha
delle potenzialità in più rispetto alla programmazione funzionale,
poiché ha il vantaggio di avere una relazione gerarchica tra gli
oggetti, che permette di gestirne lʼereditarietà, ovvero la
specializzazione degli oggetti ed il polimorfismo, cioè la capacità di
un oggetto di comportarsi come un suo “antenato”.
Infine, per avere ulteriori garanzie di sicurezza, si può sfruttare la
tecnica di programmazione per contratto (design by contract) di B.
Meyer. Essa si basa sullʼutilizzo di test sui dati subito prima della
chiamata di un metodo (precondition) e subito dopo il suo ritorno
(postcondition). In questo modo se il test fallisce significa che è inutile
proseguire perché si andrebbe incontro a una situazione
imprevedibile. Questo sistema rende leggermente più lenta la fase di
scrittura del codice a vantaggio di una più agevole fase di debug.
15.4 I linguaggi di programmazione
I linguaggi di programmazione si possono dividere in due grandi
categorie dipendentemente dal livello di astrazione da essi fornito. I
linguaggi di basso livello sono quelli più vicino alla logica della
macchina, non utilizzano i costrutti della programmazione strutturata
e fanno uso di registri e indirizzi di memoria e pertanto sono
dipendenti dalla piattaforma considerata. Lʼunico linguaggio di
programmazione di basso livello è lʼassembly (che varia
dipendentemente dalla CPU considerata). Per queste caratteristiche i
linguaggi di basso livello permettono il massimo controllo sulla
macchina e quini permettono di sfruttarne appieno tutte le
potenzialità, a scapito della facilità di scrittura del codice.
I linguaggi ad alto livello si avvicinano più alla logica umana,
astraendo dai meccanismi logici della macchina: fanno uso di codici
mnemonici per lʼidentificazione dei dati ed utilizzano i costrutti della
programmazione strutturata. Per questo i linguaggi di alto livello sono
generalmente meno performanti in termini di velocità di esecuzione
rispetto agli analoghi sviluppati in un linguaggio di programmazione a
basso livello.
Esitono anche linguaggi di alto livello che permettono lʼaccesso
agli indirizzi di memoria ed ai registri della CPU. Questo è il caso del
C (e C++), che per questo può essere considerato un linguaggio ad
alto livello con caratteristiche di basso livello che lo rendono molto
potente.
15.4.1 La memorizzazione dei dati
I linguaggi di programmazione di alto livello introducono apposite
strutture per la memorizazione dei dati ed inoltre permettono al
programmatore di assegnare un nome ad ogni locazione di memoria
effettivamente utilizzata nel corpo del programma per la
memorizzazione dei dati. Questo meccanismo di astrazione dalla
logica di memorizzazione dei dati a basso livello, rende più facile
riferirsi ai dati stessi, piuttosto che specificare esplicitamente i relativi
indirizzi di memoria, compito questo che viene totalmente demandato
al linguaggio di programmazione stesso (cioè al compilatore o
allʼinterprete). Inoltre, se il nome utilizato sarà scelto dal
programmatore in maniera oculata, sarà anche più agevole leggere il
programma stesso e capirne la logica.
Ad esempio, in un programma di contabilità, sarebbe opportuno
denominare una locazione di memoria atta a contenere un valore
intero che rappresenta lʼanno di riferimento come anno o anno_rif
piuttosto che utilizzare un nome generico tipo a, o valore, o ancora
pippo, che a distanza di pochi giorni dalla scrittura del codice a poco
servirebbe per indicare il significato della locazione di memoria anche
per lo stesso autore del programma.
15.4.1.1 Le costanti e le variabili
Esistono essenzialmente due tipi di utilizzo delle locazioni di
memoria: per la memorizzazione di dati che non possono essere
modificati durante il corso del programma o per la memorizzazione di
dati che possono essere modificati durante il corso del programma
(questo è il caso più frequente). Nel primo caso si parla di costanti,
ovvero il contenuto della locazione di memoria, che il sistema
riserverà per la memorizzazione del dato dichiarato come costante,
non potrà essere modificato durante il corso del programma:5
soltanto inizialmente sarà possibile poterlo modificare (per poterci
memorizzare il valore desiderato). Nel secondo caso si parla invece
di variabili6.
La dichiarazione di una costante/variabile indica al sistema di
riservare un apposito spazio in memoria per memorizzare un dato,
cioè una zona di memoria viene allocata (riservata) per la
memorizzazione di una particolare informazione.
Le costanti o le variabili possono essere quindi pensate come dei
contenitori, ognuno con il proprio nome (deciso dal programmatore),
in grado di contenere dei valori numerici, alfanumerici o logici,
dipendentemente dal tipo di cui sono state dichiarate. Poiché il
sistema tratta tutte le informazioni come valori numerici (v. sez. 1.3)
indicare il tipo di dato che una variabile conterrà indica al linguaggio
di programmazione il meccanismo di interpretazione dei valori in essa
contenuti: ad esempio se in una variabile è contenuto il valore
100010012 esso potrebbe indicare il numero intero senza segno 13710
oppure il numero con segno -11910 (se la locazione di memoria
utilizza solo 8 bit)7 o anche il carattere ASCII esteso con codice 89H.
Inoltre la tipizzazione dei dati aiuta il programmatore a non effettuare
errori inserendo inavvertitamente dati di un tipo allʼinterno di una
costante/variabile
dichiarata
di
tipo
diverso,
poiché
il
compilatore/interprete controllano tale occorrenza generando un
messaggio di errore.8
Ad esempio, nel linguaggio C si possono definire le costanti c_a
e c_b e le variabili v_a e v_b come riportato nellʼesempio
seguente
const int c_a = 4;
const char c_b = 'q';
int v_a;
char v_b;
In questo modo, le costanti c_a e c_b conterranno rispettivamente
il valore 4 e la lettera ʻqʼ. La variabile v_a potrà contenere al suo
interno un valore intero, mentre la variabile v_b potrà contenere al
suo interno un valore alfanumerico. In realtà quello che succede è
che le locazioni di memoria a cui fanno riferimento le costanti e le
variabili conterranno sempre valori numerici (v. sez. 1.3), ma questi
saranno opportunamente codificati/decodificati dal programma
dipendentemente dal tipo dichiarato per la costante/variabile
considerata.
I valori possono essere memorizzati allʼinterno di variabili per mezzo
di unʼistruzione particolare, detta assegnamento. Tale istruzione
cancella il valore precedentemente memorizzato nella variabile
considerata, inserendovi un nuovo valore.
Ad esempio, nel linguaggio C si può assegnare il valore 46 alla
variabile v_a ed il valore ʻeʼ alla variabile v_b con le istruzioni
riportate nellʼesempio seguente
v_a = 46;
v_b = 'e';
In questo modo, nella locazione di memoria a cui si riferisce la
variabile v_a verrà memorizzato il valore 001011102 cioè quello
corrispondente al numero decimale 46, mentre nella locazione di
memoria a cui si riferisce la variabile v_b verrà memorizzato il valore
011001012 cioè quello corrispondente alla codifica ASCII del carattere
ʻeʼ (v. tab. 1.3).
Figura 15.
6:
Esempi di assegnamento di
variabili.
15.4.1.2 Le strutture dati
Alcuni linguaggi di programmazione permettono di definire delle
strutture dati, ovvero nuovi tipi di dati formati da agglomerati di tipi di
dati già definiti. Ad esempio si potrebbe definire il tipo di dato che
serve per la gestione dei numeri complessi a + jb, dove j è lʼunità
immaginaria (j2 = -1). Questo può essere pensato come lʼinsieme di
due dati numerici in grado di memorizzare numeri con parte
decimale: il primo dato rappresenterà la parte reale (a) del numero
complesso, mentre il secondo rappresenterà quella immaginaria (b).
La struttura dati definibile in C è quella riportata nellʼesempio
seguente
struct Complesso
{
double re;
double im;
}
In questo modo una variabile var, dichiarata di tipo Complesso,
avrà due proprietà o campi: var.re che rappresenta la parte reale e
var.im che rappresenta quella immaginaria del numero complesso
memorizzato appunto in var.
15.4.1.3 I vettori
Spesso è utile avere una serie di variabili da utilizzare per compiere
su di esse operazioni identiche, senza però dover necessariamente
scrivere varie linee di codice sostanzialmente uguali.
Ad esempio si supponga di avere a che fare con una serie di
valori numerici e che ad un certo punto dellʼelaborazione a tali valori
deve essere sommato il contenuto di una determinata variabile x. In
questo caso è conveniente che la serie di valori possa essere
memorizzata in un vettore (array), cioè un insieme di variabili
contigue alle quali si può far riferimento con il medesimo nome
distinguendole una dallʼaltra per mezzo di un indice, che indica la
posizione della stessa. Analogamente a quelli usati in algebra lineare,
i vettori possono essere pensati come una variabile con un numero n
di componenti: dalla 1 alla n (alcuni linguaggi di programmazione,
come il C, numerano le componenti partendo da 0 anziché che da 1).
Quindi, supponendo ad esempio di avere 10 valori numerici
memorizzati nel vettore vett ad ognuno dei quali si voglia
semplicemente aggiungere il valore memorizzato nella variabile x, in
C si possono utilizzare le istruzioni riportate nellʼesempio seguente
int vett[10];
...
for (i=0; i<10; ++i)
{
vett[i] += x;
}
...
In questo modo si indica al programma di ripetere il blocco di
istruzioni comprese tra le parentesi graffe, incrementando di volta in
volta di una unità il valore contenuto nella variabile i (++i), alla
quale viene assegnato come valore iniziale 0 (i=0), finché la stessa
variabile i risulta minore di 10 (i<10). Quindi il programma eseguirà
lʼistruzione vett[i] += x; con i che va da 0 a 9, dopodiché
continuerà ad eseguire le istruzioni successive nel programma.
Lʼistruzione vett[i] += x; indica di incrementare il valore
contenuto in vett[i] con quello contenuto nella variabile x (in
maniera meno criptica tale operazione può essere scritta come
vett[i] = vett[i] + x;).
Si noti che per mezzo dellʼuso dei vettori in questo caso si scrivono
soltanto 3 righe di codice, piuttosto che una per ogni componente del
vettore (cioè 10).
È opportuno sottolineare che lʼuso di vettori presuppone la
conoscenza a priori del limite massimo degli elementi del vettore,
poiché quando un vettore viene dichiarato, il compilatore ha la
necessità di sapere quanta memoria dedicargli. Quindi, una volta
compilato, un programma che fa uso di un vettore di n elementi non
ne può utilizzare n + 1.
15.4.1.4 Lʼallocazione dinamica della memoria
Non sempre il programmatore è in grado di conoscere a priori il
numero di elementi da memorizzare e nemmeno è in grado di poterlo
stimare. È generalmente impossibile lʼutilizzo di vettori per la
memorizzazione dei dati.9 Si può ricorrere quindi ad una tecnica di
allocazione dinamica della memoria.
Alcuni linguaggi di programmazione mettono a disposizione del
programmatore una serie di funzionalità che permettono la gestione
dellʼallocazione della memoria in maniera dinamica: durante
lʼesecuzione delle istruzioni, il programma, se opportunamente
istruito, può richiedere al sistema operativo la memoria di cui
necessita per la memorizzazione di dati e questʼultimo (se cʼè
memoria disponibile) gliela riserverà, in maniera tale che altri
programmi non possano utilizzarla. In seguito, quando la memoria
non sarà più utilizzata dal programma, questʼultimo potrà comunicarlo
al sistema operativo che non la renderà più accessibile al
programma.
La memoria utilizzata per lʼallocazione dinamica è la cosiddetta
memoria heap10, che nei processori Intel X386 è costituita da una
parte dello stack (v. sez. 15.4.5). Questa gestione della memoria è
generalmente a carico del programmatore, anche se i linguaggi di
ultimissima generazione tendono ad avere una gestione automatica
del recupero della memoria inutilizzata (garbage collection).
15.4.1.5 Le liste concatenate
In alcuni linguaggi di programmazione è possibile definire particolari
strutture dati come le liste concatenate (chained list). Una lista
(v. fig. 15.9) non è altro che un elenco di elementi concatenati lʼun
lʼaltro, come in un grafo. Ogni elemento della lista è detto nodo ed in
esso, oltre allʼinformazione vera e propria (data), è memorizzato
lʼindirizzo della locazione di memoria nella quale è presente il nodo
successivo (next) ed eventualmente anche quello della locazione di
memoria nella quale è memorizzato il nodo precedente (prev)11. Così
facendo è possibile raggiungere i vari elementi della lista scorrendoli
dal primo fino a quello interessato (nel caso di lista doppiamente
concatenata si possono scorrere i nodi anche in senso inverso): non
è possibile accedere in maniera diretta allʼn-esimo elemento come
invece avviene con i vettori, per il fatto che i nodi sono memorizzati in
zone di memoria non (necessariamente) contigue.
Un particolare tipo di lista è la lista ciclica che ha una struttura tale
che lʼultimo nodo indica come successivo il primo ed il primo nodo
indica come precedente lʼultimo. In questo modo la lista risulta
circolare (non cʼè più un primo o un ultimo nodo).
Queste strutture dati utilizzano generalmente lʼallocazione
dinamica della memoria. Quando cʼè la necessità di un ulteriore nodo,
il programma alloca la memoria necessaria, cioè la richiede al
sistema operativo che gliela rende disponibile; poi quando il nodo non
è più utilizzato, il programma restituisce la relativa memoria al
sistema.
15.4.1.6 Le pile
Esistono anche strutture dati particolari, dette sequenziali, poiché i
dati in esse memorizzati possono essere prelevati soltanto seguendo
lʼordine di memorizzazione o il suo inverso. Una pila (stack) è una
struttura nella quale i dati possono essere prelevati in ordine inverso
a quello nel quale sono stati memorizzati, cioè lʼultima informazione
memorizzata è quella che sarà possibile prelevare per prima. Per
questo motivo si parla anche di memorizzazione di tipo LIFO (Last In
First Out).
15.4.1.7 Le code
Una coda (queue) è una struttura nella quale i dati possono essere
prelevati nello stesso ordine di quello nel quale sono stati
memorizzati, cioè la prima informazione memorizzata è quella che
sarà possibile prelevare per prima. Per questo motivo si parla anche
di memorizzazione di tipo FIFO (First In First Out).