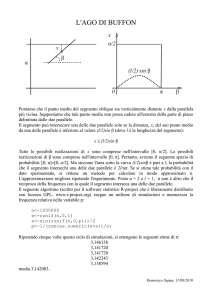
Architetture parallele
Macchina di von Neumann
Modello di calcolo: macchina di von Neumann.
Limite alle prestazione ottenibili:
• un’unica operazione in esecuzione
• una sola parte attiva
Ricerca di nuove architetture con più operazioni in
esecuzione allo stesso istante.
Memory
Control
unit
Input
Arithmetic
logic unit
Output
Accumulator
(Architettura degli Elaboratori)
Architetture parallele
1 / 70
(Architettura degli Elaboratori)
Architetture parallele
Cenni storici
2 / 70
Cenni storici
Molte proposte per architetture parallele:
Macchine parallele a larga diffusione: anni 90.
• Reti neuronali,
• Pipeline, superscalari
• Date flow machine,
Approcci conservativi, mantengo il codice.
• processore multi-core, sistemi multiprocessore,
cluster di calcolatori.
Ultime evoluzioni, conseguenze della:
legge di Moore,
vincoli sui consumi energetici.
Per sfruttare a piene il parallelismo devo usare
algoritmi concorrenti distribuiti.
• Calcolatori vettoriali,
• Connection machine,
• Illiac IV.
Scarso successo commerciale.
I calcolatori vettoriali usate per supercomputer per il
calcolo scientifico.
Approcci rivoluzionari, difficili da usare,
richiedono nuovi stili di programmazione.
(Architettura degli Elaboratori)
Architetture parallele
3 / 70
(Architettura degli Elaboratori)
Architetture parallele
Illustreremo
Motivazioni per il
parallelismo
• problematiche e aspetti generali del
parallelismo;
• classificazione dei calcolatori paralleli;
• esempi di calcolatori paralleli, idee architetturali
attualmente in uso.
(Architettura degli Elaboratori)
Architetture parallele
4 / 70
5 / 70
Migliorare le prestazioni:
• problemi che richiedo molta potenza
computazionale: algoritmi di simulazione;
• il software tende a sfruttare tutte le risorse
disponibili.
Aumento delle prestazioni mediante:
• nuove tecnologie (porte logiche più veloci).
• nuove architetture (computazione più efficiente,
maggior parallelismo)
(Architettura degli Elaboratori)
Motivazioni per il
parallelismo
Architetture parallele
6 / 70
Parallelismo su un singolo
chip
Pipeline: divisione della (micro-)istruzione in stadi.
Altri vantaggi:
• tolleranza ai guasti: più unita di calcolo, un
guasto non necessariamente blocca il
calcolatore,
• architettura scalabile: posso aumentare le
prestazioni aggiungendo nuove unità di calcolo.
S1
S2
S3
S4
S5
Instruction
fetch
unit
Instruction
decode
unit
Operand
fetch
unit
Instruction
execution
unit
Write
back
unit
(a)
S1:
1
S2:
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
1
2
3
4
5
6
7
1
2
3
4
5
6
1
2
3
4
5
8
9
S3:
S4:
S5:
1
(Architettura degli Elaboratori)
Architetture parallele
7 / 70
(Architettura degli Elaboratori)
2
3
4
5
6
7
Time
(b)
Architetture
parallele
…
8 / 70
Processori superscalari
Parallelismo a livello di
istruzione
Integer pipeline
Execute
Fetch
Decode
Cache
N1
N3
Register
X1
X2
Più istruzioni, di uno stesso processo, eseguite
contemporaneamente.
• Vantaggi: si utilizza codice sequenziale, facile
da utilizzare, non è necessario riscrivere il
codice.
• Svantaggi: difficile ottenere un elevato grado di
parallelismo.
N2
Group
Write
X3
Floating-point/graphics pipeline
Più istruzioni iniziate contemporaneamente
Prestazioni: aumento di un fattore circa dieci
(Architettura degli Elaboratori)
Architetture parallele
9 / 70
(Architettura degli Elaboratori)
Architetture parallele
Parallelismo su di un
singolo chip
VLIW – Very Long
Instruction Words
Altre tecniche il parallelismo:
• Processori VLIW Very Long Instruction Words
• On-Chip Multi-threading
• Single-Chip Multiprocessor
•
•
Multiprocessori omogenei
Multiprocessori eterogeneo
(Architettura degli Elaboratori)
Architetture parallele
10 / 70
11 / 70
Nuovi linguaggi macchina adatti alla computazione
parallela.
Sfruttano al meglio le tecnologie esistenti.
I nuovi linguaggi macchina usano:
VLIW – Very Long Instruction Words ossia istruzioni
molto lunghe, ciascuna composta da una sequenza
di istruzioni base.
Istruzione base da eseguire in parallelo
contemporaneamente.
Senza controllare che siano indipendenti tra loro.
Sposto
il lavoro dal processore
al compilatore.
(Architettura degli Elaboratori)
Architetture parallele
12 / 70
TriMedia
Itanium IA-64
Intel, candidato a sostituire l’IA-32 (Pentium, Core).
Processore sviluppato dalla Philips, per dispositivi
embedded di audio-video (DVD player - recorder,
camcorder, . . . .
Una singola istruzione è composta da 5-8
sotto-istruzioni: operazioni aritmetiche, load-store,
multimediali (vettoriali).
INSTRUCTION 1
INSTRUCTION 2
INSTRUCTION 3
TEMPLATE
INSTRUCTION 1
INSTRUCTION 2
INSTRUCTION 3
TEMPLATE
INSTRUCTION 1
INSTRUCTION 2
INSTRUCTION 3
TEMPLATE
R1
R2
Instructions
can be
chained
together
R3
PREDICATE
REGISTER
Più istruzioni possono essere collegate assieme ed
eseguiti contemporaneamente,
senza controllare l’indipendenza.
(Architettura degli Elaboratori)
Architetture parallele
13 / 70
(Architettura degli Elaboratori)
Itanium IA-64
14 / 70
Multi-threading
• Istruzioni condizionate, per evitare le istruzioni
di salto.
• Centinaia di registri, evito:
accessi in memoria,
dipendenza tra istruzioni.
• Caricamenti speculativi,
anticipo gli accessi in memoria.
a meno di page-fault.
Poco successo commerciale,
Prestazioni sotto le aspettative, difficile costruire
compilatori
il mercato ha preferito x86-64 (o AMD 64)
(Architettura conservativa.
degli Elaboratori)
Architetture parallele
scelta
Architetture parallele
Permette di sfruttare meglio le capacità di calcolo dei
processori superscalari (con più pipeline).
Il processore esegue più thread (processi (con
memoria condivisa)) contemporaneamente.
Utile nel caso un programma rallenti per:
• dipendenze tra istruzioni,
• istruzioni che bloccano, per alcuni cicli di clock
l’esecuzione (accessi alla memoria principale,
cache III livello)
15 / 70
(Architettura degli Elaboratori)
Architetture parallele
16 / 70
Multi-threading
Multi-threading
Può essere utilizzato in processori con singola
pipeline.
Più utile in processore superscalari.
In determinati istanti il processore commuta da un
thread ad un altro.
Due tecniche possibili;
• m. grana fine: si commuta su ogni istruzione,
numero elevato di commutazione di contesti,
si anticipano i possibili blocchi.
• m. grana grossa: si cerca di eseguire più
istruzioni per thread,
riduco le commutazioni.
(Architettura degli Elaboratori)
Architetture parallele
Processore con una singola pipeline:
Processore superscalare:
17 / 70
(Architettura degli Elaboratori)
Ripartizione risorse
Architetture parallele
18 / 70
Ripartizione risorse
Come le risorse del processore vengono ripartite tra
i vari thread.
Esempi:
• ogni thread disponi di un suo insieme di registri:
• risorse condivise: memoria cache
• risorse partizionate: le pipeline di un processore
super-scalare
In generale:
• condivisione ripartita: ogni thread un insieme
privato di risorse,
• condivisione totale,
• condivisione a soglia; un limite alle risorse
acquisibili da un thread.
Multi-threading usato su molti processori:
• Core i7: hyper-threading, 2 thread/core,
• UltraSparcT3: 16 core, 8 thread/core
(Architettura degli Elaboratori)
Architetture parallele
19 / 70
(Architettura degli Elaboratori)
Architetture parallele
Multiprocessori omogenei
su un singolo chip
20 / 70
Intel Core i7
Evoluzione del multi-threading, ogni thread un core.
Totale separazione delle risorse tra i thread.
Solo a memoria cache resta comune.
Maggior numero di core:
- ARM
- Cell (Sony, Toshiba, IBM)
- Schede video.
La tecnologia attuale permette di inserire più
processori su di un chip.
(Architettura degli Elaboratori)
Architetture parallele
21 / 70
(Architettura degli Elaboratori)
Co-processori
Parallelismo ottenuto delegando alcuni compiti a
processori ausiliari.
• DMA (Direct Memory Access): controllore DMA
complesso, co-processore, si fa carico della
gestione I/O.
• Scheda video: generazione di immagini.
• Co-processori multimediali: la gestione dei dati
audio video gravosa: codifica - decodifica
(MPEG, MP3), elaborazione del segnale.
• Scheda di rete: controllo degli errori,
instradamento dei messaggi.
• Cripto-processori.
(Architettura degli Elaboratori)
Architetture parallele
23 / 70
Architetture parallele
22 / 70
Multipr. eterogenei su
singolo chip
SoC (System on Chip), in un chip:
• core principale di controllo;
• co-processori specializzati;
• memoria;
• bus di interconnessione,
diversi standard alternativi:
CoreConnect IBM, AMBA per CPU CPU ARM,
VCI (Virtual Component Interconncect)
Chip progettato combinando preesistenti progetti di
singole componenti (core).
(Architettura degli Elaboratori)
Architetture parallele
24 / 70
Parallelismo su più chip
Multiprocessori
Sistemi a memoria condivisa.
Più processori su più circuiti integrati.
• Maggiori aumenti di prestazioni.
• Necessità di nuovo codice (o di un adatto SO),
nuove problematiche.
• Considereremo due principali approcci:
multiprocessori e multicomputer.
P
P
P
P
CPU
P
P
Shared
memory
P
P
P
P
P
P
P
Architetture parallele
25 / 70
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
P
(a)
(Architettura degli Elaboratori)
P
P
P
(b)
(Architettura degli Elaboratori)
Architetture parallele
Multiprocessori
26 / 70
Multicomputer
Sistemi a memoria distribuita:
• Le CPU dividono lo stesso spazio di memoria.
M
M
M
M
Private memory
• Comunicazione tra CPU attraverso l’accesso
P
P
P
P
CPU
alla memoria condivisa LOAD, STORE.
M
P
• Non è necessario ripartire i dati tra le CPU
M
P
• Accesso alla memoria limita le unità di
M
P
computazione (il grado di parallelismo).
• Esempi: PC con multi-processore, server.
M
P
Messagepassing
interconnection
network
P
P
M
M
P
P
M
M
P
P
M
P
P
M
P
P
M
P
P
M
P
P
Architetture parallele
27 / 70
• Ogni CPU ha un proprio spazio di memoria.
Machine 1
Machine 2
Application
CPU
P
P
P
P
P
P
P
P
(b)
(Architettura degli Elaboratori)
Multicomputer
P
Messagepassing
interconnection
network
(a)
(Architettura degli Elaboratori)
P
Architetture parallele
28 / 70
Simulazione memoria
condivisa
Machine 1
Machine 2
Machine 1
Machine 2
Application
Application
Application
Application
Application
Language
run-time
system
Language
run-time
system
Language
run-time
system
Language
run-time
system
Language
run-time
system
Language
run-time
system
Operating
system
Operating
system
Operating
system
Operating
system
Operating
system
Operating
system
Hardware
Hardware
Hardware
Hardware
Hardware
Hardware
• Comunicazione attraverso scambio di
messaggi: SEND, RECEIVE.
• Più semplice integrare numerose CPU, numero
unità limitato dalla capacità della rete di
interconnessione.
• Più difficili da programmare.
(Architettura degli Elaboratori)
Architetture parallele
29 / 70
Shared memory
Shared memory
Shared memory
(a)
(b)
(c)
(Architettura degli Elaboratori)
Simulazione memoria
condivisa
1
2
3
Granularità: complessità delle computazioni
eseguite in parallelo (e dei circuiti che le eseguono)
• Fine: semplici istruzioni, Instruction Level
Parallelism (ILP).
Es. processori con pipeline.
• Grossa (coarse): procedure, Process Level
Parallelism (PLP).
Es. multi-threading, multiprocessori,
multicomputer.
nel memoria della CPU,
in memoria disco,
nella memoria locale di un altra CPU.
DSM (Distributed Shared Memory).
Memoria condivisa tramite librerie.
•
•
Linda: programmi con tuple condivise.
Orca: programmi con oggetti condivisi.
(Architettura degli Elaboratori)
Architetture parallele
30 / 70
Catalogazione del
parallelismo
Memoria condivisa hardware.
Memoria condivisa tramite memoria virtuale,
paginazione.
Una pagina può trovarsi:
•
•
•
Architetture parallele
31 / 70
(Architettura degli Elaboratori)
Architetture parallele
32 / 70
Livello di accoppiamento
Scalabilità
• Forte: unità fortemente connesse, notevole
Una stessa idea architetturale può essere
implementata con un numero variabile di unità di
calcolo.
Un’architettura è scalabile se funziona correttamente
con molte unita di calcolo.
scambio di dati. Es. processori superscalari,
multiprocessori.
• Debole: unità più indipendenti.
Es. multicomputer.
CPU
Bus
(a)
(Architettura degli Elaboratori)
Architetture parallele
33 / 70
(b)
(Architettura degli Elaboratori)
(c)
(d)
Architetture parallele
Scalabilità - prestazioni
34 / 70
Scalabilità
60
N-body problem
50
Linear speedup
40
Speedup
Problemi:
• Le unità di calcolo devono sincronizzarsi tra
loro, overhead di computazione (lavoro extra).
• Memoria, o altre risorse condivise, creano
conflitti tra le unità di calcolo.
Conseguenze:
• difficilmente n unità svolgono un lavoro n volte
più velocemente,
• a volte un aumento delle unità di calcolo porta a
un peggioramento delle prestazioni.
Scalabilità dipende sia dall’architettura che dai
problemi considerati:
Awari
30
20
10
Skyline matrix inversion
0
(Architettura degli Elaboratori)
Architetture parallele
35 / 70
Componenti di un
calcolatore parallelo
• Unità di memoria. Memorie cache locali alle
CPU,
memoria principale divisa in banchi per gestire
più richieste contemporanee.
• Rete di interconnessione.
50
60
Architetture
parallele
36 / 70
• Composta da diverse unità operanti in parallelo.
• Struttura complessa, dati replicati:
• ogni core possiede una cache locale,
• cache di alto livello comune a più core,
• memoria principale comune a più processori,
eventualmente divisa in banchi.
• Tempi di accesso ai dati dipendo dalla loro
Nei multiprocessori, collegano processori e moduli di
memoria.
• Nei multicomputer, collegano le unità di calcolo.
•
Architetture parallele
30
40
Number of CPUs
Memoria
• Unità di calcolo. Si usano processori standard.
(Architettura degli Elaboratori)
0
10 Elaboratori)
20
(Architettura
degli
37 / 70
Consistenza della memoria
Una memoria con comportamento ideale
(esecuzione in ordine, tutti i processore hanno la
stessa visione della memoria) è troppo lenta.
Ma l’ordine di accesso ai dati in memoria non può
essere arbitrario,
vanno stabilite regole minime per rendere
prevedibile il comportamento del codice.
• Sequenziale: tutte le CPU vedono lo stesso
ordine.
• Di processore: preserva: le scritture di ogni
CPU, la scrittura di ogni indirizzo.
• Debole: prevede richieste di sincronizzazione,
• Dopo
(Architettura
degli Elaboratori)
Architetture parallele
39 / 70
il rilascio: sincronizzazione
locale.
posizione rispetto al processore.
Per preservare l’efficienza, sono ammessi
accessi alla memoria fuori ordine:
i dati disponibili vengono subito letti o scritti.
(Architettura degli Elaboratori)
Architetture parallele
38 / 70
Reti di interconnessione
Equivalente sofisticato dei bus.
Componente fondamentale dei calcolatori paralleli.
Composte da:
• Link (connessioni - cavi - bus)
paralleli o seriali
• Switch (instradatori - commutatori)
• Interfacce (Processori - rete - memorie)
(Architettura degli Elaboratori)
Architetture parallele
40 / 70
Switch
Topologie di rete
Metodi di comunicazione:
• Circuit switching,
• Packed switching, Store and forward:
messaggio diviso in pacchetti.
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
Input port
CPU 1
Output port
A
B
C
D
End
of
packet
Four-port switch
Middle
of
packet
CPU 2
Front of packet
Routing: determinazione del percorso.
(Architettura degli Elaboratori)
Architetture parallele
41 / 70
(Architettura degli Elaboratori)
Topologie di rete
Classificazione di Flynn (1972)
massimizzare la ampiezza di banda (bidirezionale),
evitare colli di bottiglia,
minimizzare le distanze (in numero di archi):
diametro.
• SISD Single Instruction Single Data (macchina
di von Neumann)
• SIMD Single Instruction Multiple Date
(Computer Vettoriali)
• Configurazione: stella, completamente
• MIMD Multiple Instruction Multiple Data
interconnessa, albero, anello, griglia, doppio
toroide, ipercubo.
Geometria fissa o variabile
(Architettura degli Elaboratori)
42 / 70
Tassonomia dei computer
paralleli
Modo di strutturare le unità di calcolo:
• Obiettivi
•
•
•
Architetture parallele
Architetture parallele
(Multiprocessori e multicomputer)
• MISD Multiple Instruction Multiple Data (nessun
esempio)
43 / 70
(Architettura degli Elaboratori)
Una classificazione più fine
Architetture parallele
44 / 70
SIMD: Array processor
Control unit
Parallel computer architectures
Broadcasts instructions
SISD
SIMD
MISD
(Von Neumann)
MIMD
?
Vector
processor
Array
processor
Multiprocessors
Multicomputers
8 × 8 Processor/memory grid
Processor
UMA
COMA
NUMA
MPP
COW
Memory
Bus
Switched
CC-NUMA
NC-NUMA
Shared memory
(Architettura degli Elaboratori)
Grid
Hypercube
Più processori controllati da una unità: ILLIAC IV
Message passing
Architetture parallele
45 / 70
(Architettura degli Elaboratori)
GPU (Graphical Process
Unit)
ogni core ha una memoria privata,
gruppi di core condividono una memoria locale,
esiste una memoria comune a tutti i core.
(Architettura degli Elaboratori)
Architetture parallele
46 / 70
Nvidia Fermi
Alcune schede grafiche sono un implementazione
moderna degli array processor.
• La computazione nelle GPU (Graphical process
unit) avviene secondo lo schema array
processor:
• la stessa operazione eseguita da semplici core
su dati diversi.
• struttura della memoria complessa:
•
•
•
Architetture parallele
512 Core.
Gerarchia di memoria: locale al singolo core,
condivisa tra gruppi di core, memoria comune.
47 / 70
(Architettura degli Elaboratori)
Architetture parallele
48 / 70
GPGPU (General Purpose
GPU)
SIMD: Vector processor
Input vectors
Si utilizzano le GPU per calcoli generici (non grafici)
• si sfrutta l’elevato numero di core,
• solo alcuni tipi di calcolo adatti a questo tipo di
computazione,
• nuovi linguaggi di programmazione su GPGPU
CUDA (Nvidia)
OpenCL (Generico, usabile su più schede grafiche).
•
•
(Architettura degli Elaboratori)
Architetture parallele
49 / 70
Vector ALU
ALU e Registri operano su vettori.
Supercomputer anni 70-80, CRAY.
(Architettura degli Elaboratori)
SIMD instruction
Architetture parallele
SIMD instruction
I processori attuali implementano istruzioni vettoriali.
Si distingue tra:
Estensioni ai linguaggi macchina.
• istruzioni multimediali: lunghezza fissa.
ISA x86:
• MMX (MultiMedia eXtension)
• SSE (Streaming SIMD Extension), ... , SSE4
• AVX (Advance Vector eXtension)
Utilizzati registri molto lunghi, centinaia di bit,
contenenti vettori di dati (byte, half-word, word)
su cui operare con istruzioni vettoriali.
• istruzioni vettoriali: insiemi di dati di lunghezza
(Architettura degli Elaboratori)
Architetture parallele
variabile, parametriche
Vantaggi:
• si sfrutta la legge di Moore (i tanti transistor a
disposizione),
• istruzioni vettoriali permettono un codice più
compatto.
51 / 70
(Architettura degli Elaboratori)
Calcolatori MIMD
Architetture parallele
53 / 70
SMP (Symmetric Multi Processor): quando i
processori hanno la stessa visione della memorie e
dei dispositivi I/0:
(Architettura degli Elaboratori)
CPU
CPU
M
CPU
CPU
M
CPU
CPU
M
Cache
Bus
(a)
(b)
(c)
• L’implementazione più semplice di un sistema
multiprocessore.
• Bus limita il numero di CPU utilizzabili (16).
• Cache di grosse dimensioni per limitare
l’accesso al bus.
• Necessità di mantenere la coerenza della
cache.
(Architettura degli Elaboratori)
Architetture parallele
Architetture parallele
54 / 70
Snooping cache
Shared
memory
Private memory
52 / 70
Tutti i processori hanno stessi tempi di accesso alla
memoria,
SMP con singolo bus
Shared memory
Architetture parallele
Multiprocessori UMA
• multiprocessor
• UMA Uniform Memory Access
• NUMA Non Uniform Memory Access
• multicomputer
• MPP Massive Parallel Processor
• COW Cluster Of Workstation (NOW Network Of W.)
• Grid Computing
(Architettura degli Elaboratori)
50 / 70
55 / 70
Le cache spia il traffico sul bus per garantire la
coerenza.
Diverse implementazioni: Write through
• Read Miss – Lettura dalla memoria.
• Read Hit – Dati locali.
• Write Miss – Aggiorna memoria - Invalida altre
linee.
• Write Hit – Aggiorna memoria e cache – Invalida
altre linee.
Semplice ma poco efficiente: troppe scritture in
memoria.
(Architettura degli Elaboratori)
Architetture parallele
56 / 70
Snooping cache:
protocollo MESI
MESI, esempio
CPU 1
CPU 2
CPU 3
Memory
(a)
Protocollo write back.
Utilizzato nei processori Core.
Ogni linea di cache viene marcato in uno tra 4 modi:
CPU 1 reads block A
A
Exclusive
Bus
Cache
CPU 1
CPU 2
CPU 3
Memory
(b)
CPU 2 reads block A
A
Shared
Shared
• Exclusive (sola copia in cache);
Bus
• Shared (linea presente in altre cache);
CPU 1
CPU 2
CPU 3
Memory
(c)
CPU 2 writes block A
A
• Modified (linee cache diversa da quella in
Modified
Bus
memoria);
• Invalid (linea non valida).
CPU 1
CPU 2
CPU 3
A
A
Memory
(d)
Shared
CPU 3 reads block A
Shared
Bus
CPU 1
(Architettura degli Elaboratori)
Architetture parallele
57 / 70
(e)
CPU 2
CPU 3
Memory
(Architettura degli Elaboratori)
A
CPU 2 writes block A
Architetture
parallele
58 / 70
Modified
Bus
CPU 1
CPU 2
CPU 3
Memory
(f)
CPU 1 writes block A
A
UMA con crossbar switch
UMA con reti a
commutazione
Modified
Bus
Processori e memorie connesse con un crossbar
switch, (Sun Fire E25K).
Rete non bloccante.
Elevato numero di switch. (O(n2 ))
Rete Omega
• Rete bloccante.
• Limitato numero di switch. (O(n log n))
111
110
101
100
011
010
001
000
Memories
3 Stages
Crosspoint
switch is open
CPUs
Memories
000
000
001
1A
2A
000
3A
b
b
b
001
001
CPUs
010
010
(b)
011
1B
2B
100
011
b
100
101
1C
110
101
111
110
(Architettura degli Elaboratori)
Open
crosspoint
switch
101
59 / 70
a
1D
111
Architetture parallele
100
3C
2C
a
(c)
Closed
crosspoint
switch
010
3B
011
Crosspoint
switch is closed
a
(Architettura degli Elaboratori)
2D
3D
a
110
111
Architetture parallele
60 / 70
(a)
Multiprocessori NUMA
Multiprocessori NUMA
Not Uniform Memory Access
CPU Memory
CPU Memory
• Memoria locale e remota
CPU Memory
CPU Memory
• Un unico spazio di indirizzamento
• maggiore scalabilità: superano il limite delle 100
MMU
Local bus
Local bus
Local bus
CPU
Local bus
• necessità di ridistribuire i dati
System bus
(Architettura degli Elaboratori)
Architetture parallele
Hardware DSM Distributed Shared Memory.
61 / 70
(Architettura degli Elaboratori)
Architetture parallele
Multicomputer
Multicomputer
CPU con spazio privato di memoria, non
direttamente accessibile
Vantaggi:
CPU
…
Local interconnect
• efficienti nell’eseguire in parallelo processi
indipendenti (o con poca dipendenza). Es.
server web.
Disk
and
I/O
…
Local interconnect
Disk
and
I/O
Communication
processor
Caratteristiche:
• sistemi fault-tollerance,
• i singoli computer possono essere SMP con bus
singolo.
Architetture parallele
Node
Memory
…
• maggiore scalabilità,
(Architettura degli Elaboratori)
62 / 70
63 / 70
High-performance interconnection network
Si dividono in due categorie.
(Architettura degli Elaboratori)
Architetture parallele
64 / 70
Massive Parallel Processor
MPP
BlueGene
Progetto IBM.
Record di prestazioni teoriche ed effettive.
Campi d’applicazione: scacchi, simulazione:
protein-unfolding, sistemi biologici (cervello, cuore),
cosmologia.
• Gli attuali supercomputer
• Un elevato numero di processori standard
• Rete di interconnessione sofisticata
• Librerie software parallelo
• Fault tollerance: necessario per l’elevato
numero di componenti
• Esempi: BlueGene: ∼: 400K CPU, Red Storm
10K CPU Opeteron.
(Architettura degli Elaboratori)
Architetture parallele
65 / 70
Cluster of workstation
COW
(Architettura degli Elaboratori)
Architetture parallele
66 / 70
Esempio: Cluster Google
• Rete di interconnessione standard: si sfruttano i
progressi nelle reti.
• Dispositivi economici, facilmente assemblabili,
• possono raggiungere prestazioni paragonabile
ai MPP.
• Centralizzati o decentralizzati.
(Architettura degli Elaboratori)
Architetture parallele
67 / 70
(Architettura degli Elaboratori)
Esempio: Cluster Google
Architetture parallele
68 / 70
Grid computing
Un numero limitato di datacenter (12) di grosse
dimensioni.
Il progetto poco pubblicizzato.
Principi costruttivi:
• utilizzare componenti economici (desk-top, rete
Ethernet) di largo uso, con il miglior rapporto:
prestazioni/(prezzo + consumi);
(consumi ∼100MW)
• l’affidabilità ottenuta attraverso ridondanza, la
rottura di un componente non compromette il
sistema.
(Architettura degli Elaboratori)
Architetture parallele
69 / 70
Computazione distribuita su calcolatori eterogenei,
distanti tra loro, connessi via web.
• organizzazione pear-to-pear,
• meccanismi di protezione, autenticazione
singola,
• gestione della risorse di calcolo (locale-grid),
• distribuzione del carico,
• sistemi di calcolo non omogenei, definizione di
uno standard comune.
(Architettura degli Elaboratori)
Architetture parallele
70 / 70