DataBase NoSQL
Prof. Marco Pedroni – Unversità degli Studi di Ferrara
Definizione
DB NoSQL =
sistemi software di archiviazione, in cui la persistenza dei dati è
caratterizzata dal fatto di non utilizzare il modello relazionale, di
solito usato dai database tradizionali (RDBMS)
Modello relazionale
“Next generation databases mostly addressing some of the points:
being non-relational, distributed, open source and horizzontally scalable”
(definizione da http://nosql-database.org/)
DB NoSQL - caratteristiche
Database distribuiti
Strumenti generalmente open-source
NON dispongono di schema
NON supportano operazioni di join
Implementano parzialmente le proprietà
ACID delle transazioni
Sono scalabili orizzontalmente
Sono in grado di gestire grandi moli di dati
Supportano le repliche dei dati
ACID
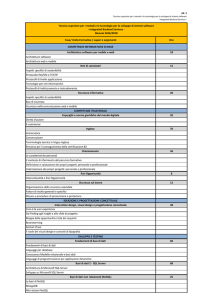
Le proprietà logiche che devono avere le transazioni per operare in modo corretto sui dati:
Atomicità, Coerenza, Isolamento, Durabilità
Perché le transazioni operino in modo corretto sui dati è necessario che i meccanismi che le
implementano soddisfino queste quattro proprietà:
atomicità: la transazione è indivisibile nella sua esecuzione e la sua esecuzione deve
essere o totale o nulla, non sono ammesse esecuzioni parziali
coerenza: quando inizia una transazione il database si trova in uno stato coerente e
quando la transazione termina il database deve essere in un altro stato coerente, ovvero
non deve violare eventuali vincoli di integrità, quindi non devono verificarsi contraddizioni
(inconsistenza) tra i dati archiviati nel DB
isolamento: ogni transazione deve essere eseguita in modo isolato e indipendente dalle
altre transazioni, l'eventuale fallimento di una transazione non deve interferire con le altre
transazioni in esecuzione
durabilità: detta anche persistenza, si riferisce al fatto che una volta che una transazione
abbia richiesto un commit work, i cambiamenti apportati non dovranno essere più persi
DB NoSQL - caratteristiche
●
Leggerezza computazionale: i database NoSQL non prevedono operazioni di aggregazione sui dati
(JOIN), molto dispendiose in termini dipeso computazionale, in quanto tutte le informazioni sono già raccolte in
un unico documento associato all’oggetto da trattare. Ne derivano migliori performance, ma si generano
duplicazioni delle informazioni (i costi attuali dei sistemi di storage rendono questo svantaggio poco importante)
e si richiede un controllo diretto dell'integrità dei dati
●
Assenza di schema: i database NoSQL sono privi di schema in quanto ogni documento contiene tutti i
campi necessari, senza necessità di predefinizione. In questo modo, si possono aggiungere nuovi dati e
informazioni, definibili liberamente all’interno dei documenti, senza rischi per l’integrità dei dati. Sono quindi
adatti a inglobare velocemente nuovi tipi di dati, anche semistrutturati o non strutturati
●
Scalabilità orizzontale: l’aggregazione dei dati e l’assenza di uno schema definito a priori offre
l’opportunità di scalare orizzontalmente i database NoSQL senza difficoltà e senza rischi operativi
DB NoSQL - ambiti di utilizzo
Volume
Velocità
Dati semistrutturati – non strutturati
Varietà
DB NoSQL - ambiti di utilizzo
Motivazioni della diffusione dei database NoSQL:
Gestione dei Big-data
Limitazioni del modello relazionale
Teorema CAP
DB NoSQL - Volume
Volume: Big data = grandi moli di dati
Dati
Scientifici
PB
Web
Server
Log
Sensori
Transazioni
finanziarie
TB
GB
ERP
CRM
Social Media
User
Generated
Contents
Documenti
Word, Excel,
PDF
MB
Complessità bassa
Complessità media Complessità alta
DB NoSQL - Velocità
Velocità: Big data = stream di dati
Stream MorningStar di dati NASDAQ: oltre 5.000 record di transazioni /secondo
DB NoSQL - Varietà
Varietà: Big data =
dati eterogenei, multi-sorgente
SOCIAL MEDIA
DBMS
OPERATIVO
SITO WEB
DATA
WAREHOUSE
SOFTWARE DI
SUPPORTO
DECISIONALE
REPORT
DB NoSQL - Limiti dei modelli relazionali
Il modello relazionale presuppone una
rappresentazione tabellare, che accade
se i dati non si presentano in tale forma?
ANAGRAFICA
PAGINA
WEB
CF
Nome
?
?
Cognome
?
Luogo
?
?
Data
DB NoSQL - Limiti dei modelli relazionali
Alcune operazioni sono complesse da
implementare in SQL.
Memorizzazione di un grafo, e calcolo del
percorso minimo tra due punti.
Esempi:
DB NoSQL - Limiti dei modelli relazionali
Scalabilità orizzontale dei DMBS relazionali.
PROBLEMI
Gestione dei vincoli
Throughput
(operazioni / sec)
Repliche dei dati
Gestione delle transazioni
Soddisfacimento delle
proprietà ACID
Servers
DB NoSQL - Teorema di CAP
Il teorema di Brewer (CAP Theorem)
afferma che un sistema distribuito può
soddisfare al massimo solo due delle tre
proprietà elencate sotto:
Consistency Tutti i nodi della rete vedono gli stessi dati
Availability Il servizio è sempre disponibile
Partition Tolerance Il servizio continua a funzionare
correttamente anche in presenza di perdita di messaggi o di
partizionamenti della rete.
Consistenza (tutti i nodi vedono gli stessi dati nello stesso momento)
Disponibilità (la garanzia che ogni richiesta riceva una risposta su ciò che è riuscito o fallito)
Tolleranza di partizione (il sistema continua a funzionare nonostante le perdite di messaggi)
DB NoSQL - Teorema di CAP
DB risponde sempre
DB risponde correttamente
DB distribuito
DB NoSQL - Teorema di CAP
DB NoSQL - Teorema di CAP
Comportamento dei database NoSQL
Basically Available I nodi del sistema distribuito
possono essere soggetti a guasti, ma il servizio è
sempre disponibile.
Soft State La consistenza dei dati non è
garantita in ogni istante.
Eventually Consistent Il sistema diventa
consistente dopo un certo intervallo di tempo, se
le attività di modifica dei dati cessano.
DB NoSQL - Modelli logici
Il termine NoSQL identifica diverse tipologie di
database, basate su modelli logici differenti:
Database chiave/valore
Database document-oriented
Database column-oriented
Database graph-oriented
DB NoSQL - modello Chiave-Valore
Esempi: BerkeleyDB, Project Voldemort
Dati di un DB come liste di coppie chiave/valore
(array associativi o dizionari)
Chiave valore univoco per operazioni di ricerca
Valore qualsiasi tipo di dato
Chiave
Valore
1
{Mario Rossi, 02311323}
2
{Mario Bianchi, 23}
3
{Dipartimento Informatica, Via Zamboni,
05143242}
DB NoSQL - modello Document oriented
Esempi: MongoDB, CouchDB
Gestione di dati eterogeneei e complessi (semi-strutturati)
Scalabili orizzontalmente, supporto per partizionamento
(sharding) dei dati in sistemi distribuiti
Documenti coppie chiave/valore (JSON)
Forniscono funzionalità per aggregazione/analisi dei dati
(MapReduce)
DB NoSQL - modello Column oriented
Esempi: HBase, Cassandra
Dati organizzati su colonne anziché su righe.
Column family: contenitore di colonne. Ogni column
family è scritta su un file diverso. Ogni riga dispone di
una chiave primaria (row key).
Schema flessibile
Maggiore efficienza nello storage
Maggiore possibilità di compressione dati
Usato in sistemi dati read-oriented (es. warehousing)
DB NoSQL - modello Column oriented
ID
Nome
Cognome
Nascita
Chiave della riga
Column Family 1
(dati anagrafica)
FILE 1
Lavoro
Salario
Contratto
Column Family 2
(dati lavoro)
FILE 2
DB NoSQL - modello Graph oriented
Esempi: Neo4J, Titan
PROPERTY GRAPH
Dati strutturati sotto forma di grafi:
nodi = attributi/righe,
archi = relazioni tra attributi/righe
Hadoop
Apache Hadoop è un framework che supporta applicazioni distribuite
con elevato accesso ai dati. È composto da due elementi fondamentali:
HDFS
Hadoop Distributed File System
è un file system distribuito e scalabile
MapReduce
MapReduce è un framework software che
supporta la computazione distribuita su
grandi quantità di dati in cluster di
computer, usando le funzioni map e reduce
HBase
• HBase è un ambiente di archiviazione di dati
distribuito, column-oriented, costruito su HDFS e
fondato sul modello di Google BigTable
• HBase è un progetto Apache open source il cui
obiettivo è archiviare dati per Hadoop Distributed
Computing
• I dati sono organizzati logicamente in tables, rows,
families e columns
Hbase – Data model
Hbase – Operations