SVILUPPO DI UNA CLASSE STATISTICA IN AMBIENTE JAVA
POTOK MARCO
Università degli Studi di Trieste
A.A. 2011/2012
SVILUPPO DI UNA CLASSE STATISTICA IN AMBIENTE JAVA
ANALISI ED ESEMPI D'UTILIZZO
Potok Marco
➢ IDEA
Creare un programma Java in grado di risolvere problemi statistici assegnati in classe e proposti nei temi
d'esame.
➢ COME
In primis è stata scritta una classe Stat dove sono stati implementati vari metodi con le principali
funzioni per la risoluzione dei problemi di statistica. In seguito la classe Stat è stata opportunamente
usata per risolvere 5 esercizi (2 compiti per casa e 3 temi d'esame). Sono state quindi create 5 classi con
un metodo main per stampare a video i risultati. Vedremo in dettaglio ogni risoluzione.
➢ LA CLASSE STAT
Ora vedremo in dettaglio la classe Stat, composta da 47 metodi in grado di calcolare disposizioni,
permutazioni, dismutazioni, combinazioni semplici, la speranza matematica, la varianza e la media di un
campione, gli intervalli di fiducia e i test di Student per uno e due campioni. Può inolte calcolare la
cumulative distrubution function della distribuzione normale tramite il metodo CdfN che utilizza a sua volta
il metodo Erf che restituisce il valore dell'integrale
x
2
e−t dt .
√π ∫
2
0
➢ IL METODO ERF
Soffermiamoci ora sul metodo Erf(double x) della classe Stat. Sappiamo che la funzione errore è
definita dall'integrale sopracitato, rendendola difficile da calcolare in Java senza approssimazioni. Si è
quindi ricorso alla serie di Taylor per descrivere la funzione come la sommatoria
m
i
2i+1
(−1) x
2
Erf ( x) := √ π ∑
i =0 i !( 2i+1)
( con m → ∞) .
Questo procedimento ha permesso d'implementare la funzione in Java tramite un metodo iterativo,
quindi semplice ed efficacie da utilizzare in un calcolatore. Per ottenere valori approssimati al meglio
sarebbe necessario imporre m più grande possibile, tenendo però conto della velocità di calcolo e, data la
presenza di un fattoriale dell'indice, la capacità massima di cifre a disposizione nel calcolatore.
Risolviamo questi problemi con delle veloci verifiche empiriche. Con il comando Double.MAX_VALUE
vediamo che il massimo numero consentito è 1.7976931348623157E308. In seguito verifichiamo per
quale m il suo fattoriale è minore del valore massimo appena trovato. Si ottiene che la m cercata vale 170,
quindi non ha senso (e potrebbe essere molto dannoso ai fini della precisione di calcolo) porre m>170.
Scritto il metodo che implementa
170
(−1)i x 2i+1
2
∑
√π
i=0 i ! (2i+1)
dobbiamo verificare che il tempo d'esecuzione sia ottimale. Tramite una classe prova creata ad hoc, si
verifica la velocità del calcolo di Erf(x) per 0⩽x<6 con definizione 0,01. I risultati dimostrano che
la media è di circa 0,085 ms, con un massimo di 0,133 ms, tempo più che accettabile. Come
ultima analisi, vediamo l'errore di approssimazione di tale metodo (confrontato con i valori
ottenuti in Matlab):
1
SVILUPPO DI UNA CLASSE STATISTICA IN AMBIENTE JAVA
POTOK MARCO
Si conclude che l'errore è molto limitato, con valore massimo di 7,1863E-10 ed è pari a zero per valori di
x minori di 3,5 e maggiori di 5,1.
➢ LE CLASSI EX_C ED EX_G
Queste classi contengono un metodo che utilizza la classe Stat per risolvere gli esercizi C e G assegnati
come compiti per casa.
Nell'esercizio C come primo punto è rischiesta la probabilità che in 13 lanci di una moneta regolare esca
esattamente 3 volte testa. La risoluzione è semplice e consta nello stampare a video il rapporto tra la
combinazione C13,3 che rappresenta i casi favorevoli e i 213 casi possibili. Il risultato è inoltre arrotondato
a 4 cifre significative ed espresso anche in forma percentuale. Vediamo il codice Java:
short N=13;
double pa=Stat.combS(N,3)/Math.pow(2,N);
System.out.println("La probabilità che esca testa esattamente
"+Stat.Round(pa,4)+", cioè: "+Stat.Round(pa*100,1)+"%.");
3
volte
è:
e stampa a video:
La probabilità che esca testa esattamente 3 volte è: 0.0349, cioè: 3.5%.
Similmente si è proceduto con il secondo punto dell'esercizio, calcolando le probabilità che la testa esca
almeno 3 volte su 13 lanci:
double pb=1-(Stat.combS(N,2)-Stat.combS(N,1))/Math.pow(2,N);
System.out.println("La
probabilità
che
esca
testa
almeno
"+Stat.Round(pb,4)+", cioè:"+Stat.Round(pb*100,1)+"%.");
3
volte
è:
con relativa risposta:
La
probabilità
che
esca
testa
almeno
3
volte
è:
0.9921,
cioè:
99.2%.
2
SVILUPPO DI UNA CLASSE STATISTICA IN AMBIENTE JAVA
POTOK MARCO
vengono invece richieste le probabilità: X Cauchy per P ( X <b),
Y N ( µ=3, s =2) per P (a≤ y≤b) e W lnN ( µ=7, s 2=1.1) per P ( w≥b) , con a=113 /1013
e b=1013/ 213. Nella classe Stat sono stati implementati 3 metodi appositi per calcolare la probabilità
dei vari intervalli tramite la funzione di ripartizione corrispondente. I codici risultamo quindi molto
semplici:
Nell'esercizio
G
2
double F_b=Stat.Cauchy_F(b);
double nP=Stat.NormalP(3,2,a,b);
double lnNP=Stat.lnNormalP(7,1.1,b,'>').
➢ ESERCIZI D'ESAME
Con le tre classi Ex_3_110718, Ex_2_120220 ed Ex_3_120618 si dimostra come in un solo comando si
possa risolvere un intero quesito d'esame. Nel primo caso il terzo esercizio proposto all'esame del 18
luglio 2011 richiede, dati due campioni, di verificare con i test statistici se µ x ≠0 (contro µ x ≠ 0) e
l'ipotesi µ x =µ y (contro µ x ≠ µ y ). Nella classe Stat sono stati implementati due metodi STest(double[ ]
x, double m, double a, char c) e STest(double[ ] x, double[ ] y, double a, char c) che svolgono le
verifiche per il test di Student. Vediamo i codici Java:
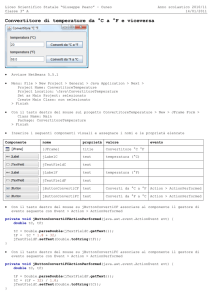
public static Boolean Stest(double[ ] x, double m, double a, char c)
{
if(c=='<') return T_n(x,m)>Tstud(x.length-1, 1-a);
if(c=='=') return Math.abs(T_n(x,m))<Tstud(x.length-1, 1-a/2);
else return null;
}
public static Boolean Stest(double[ ] x, double[ ] y, double a, char c)
{
if(c=='>') return Math.abs(T_n(x,y))>Tstud(x.length+y.length-2, 1-a);
if(c=='=') return Math.abs(T_n(x,y))<Tstud(x.length+y.length-2, 1-a/2);
else return null;
}
Questi permettono di risolvere il quesito e stampare a video la soluzione utilizzando solamente quattro
semplici linee di codice:
double[] x={.3,2.2,-.5,-.2,1,2.1}, y={-2.2,.5,-.3,.2,-2.1,-1};
double a=.05;
System.out.println("L'ipotesi µx=0"+(Stat.STest(x,0,a,'=')?" non":"")+" è respinta
al livello "+a+".");
System.out.println("L'ipotesi
µx=µy"+(Stat.STest(x,y,a,'=')?"
non":"")+"
è
respinta al livello "+a+".")
che stampano le relative risposte:
L'ipotesi µx=0 non è respinta al livello 0.05.
L'ipotesi µx=µy è respinta al livello 0.05.
che corrispondono alle soluzioni messe in rete. Similmente e con ugual successo è stato risolto l'esercizio
3 del 18 giugno 2012, con output:
L'ipotesi µx=µy non è respinta al livello 0.05.
L'ipotesi µx=µy non è respinta al livello 0.01.
Ora vediamo come è stato possibile risolvere l'esercizio 2 del 20 febbraio 2012, in cui si chiede di trovare
prima il valore di un elemento c di un campione 0,11 0,05 c la cui media è 0,09, quindi gli intervalli di
fiducia consueti per µ ai livelli 0,05 e 0,01. Prima di tutto il valore di c è stato trovato con un banale
calcolo:
c=.09*3-.11-.05;
3
SVILUPPO DI UNA CLASSE STATISTICA IN AMBIENTE JAVA
POTOK MARCO
Si definisce quindi il campione da analizzare e si usa il metodo ConfIntMeanPrint(double[ ] x, double
a, int c) per stampare a video l'intervallo di confidenza richiesto. Il codice è:
double[ ] a={.11,.05,c};
System.out.print ("L'intervallo di fiducia del campione gaussiano a livello "+a1+"
è: ");
Stat.ConfIntMeanPrint(a,a1,4);
System.out.print ("L'intervallo di fiducia del campione gaussiano a livello "+a2+"
è: ");
Stat.ConfIntMeanPrint(a,a2,4);
Con relativa risposta:
L'intervallo di fiducia del campione gaussiano a livello 0.05 è: [0.0039,0.1761]
L'intervallo di fiducia del campione gaussiano a livello 0.01 è: [-0.1085,0.2885]
➢ CONCLUSIONE
È stato possibile realizzare l'idea iniziale che prevedeva di creare un programma Java in grado di risolvere
alcuni dei principali problemi statistici proposti nel corso di Metodi Statistici e Processi Stocastici 2011/2012.
Sono stati presi ad esempio cinque esercizi tra compiti per casa e temi d'esame, riuscendo a ricavare un
risultato preciso per ogni quesito, mantenendo sempre una notevole facilità d'utilizzo del codice, tanto
da richiederne poche righe per ogni esercizio. Successivamente alla stesura della presente tesina, il
programma è stato ulteriormente sviluppato ed ottimizzato. In particolare ora è possibile calcolare: le
funzioni gamma e beta standard, incomplete, regolarizzate incomplete. Altri metodi calcolano la
funzione di densità, di ripartizione e i quantili della distribuzione normale, come della distribuzione di
Student e del chi-quadrato. In futuro è previsto un'ulteriore sviluppo, ampliando così ulteriormente la
classe Stat che potrà risolvere gran parte dei problemi statistici.
➢ FONTI
- Appunti delle lezioni del corso Metodi Statistici e Processi Stocastici 2010/2011 – 2011/2012
- Wikipedia: http://en.wikipedia.org/wiki/Error_function
http://en.wikipedia.org/wiki/Normal_distribution
http://en.wikipedia.org/wiki/Student_t_distribution
http://en.wikipedia.org/wiki/Gamma_function
http://en.wikipedia.org/wiki/Beta_function
http://en.wikipedia.org/wiki/Pochhammer_symbol
- Mathworld: http://mathworld.wolfram.com/IncompleteBetaFunction.html
➢ PROGRAMMI UTILIZZATI
- DrJava (drjava-20110822-r5448)
- Matlab R2010a
4