NOSQL
NOSQL
Origini e Significato
NOSQL = NO a SQL
NOSQL = Not Only SQL
Il termine NOSQL fu introdotto da Carlo Strozzi nel 1998 per indicare il suo database
relazionale open-source che non aveva una interfaccia SQL standard.
Il termine attualmente indica tutti quei database che sono: non relazionali, distribuiti,
open-source (spesso) e scalabili orizzontalmente.
NOSQL
Introduzione – un po' di storia
Anni '70
Nascono i database relazionali
- I supporti di memorizzazione sono altamente costosi
- I dati vengono normalizzati per il loro inserimento nel database
- L'organizzazione dei dati dipende da loro stessi e non dall'uso che sarà fatto
Anni '80
Vengono introdotti i sistemi RDBMS
- Si introduce il modello Client/Server
- Il linguaggio SQL diventa lo standard per l'interrogazione dei database
Anni '90
Nascita del World Wide Web e inizio della diffusione massiva di Internet
NOSQL
Introduzione – un po' di storia
Anni 2000
Nascita del Web 2.0
- Diminuisce notevolmente il costo dei sistemi di memorizzazione
- Diffusione dell'e-Commerce
- Diffusione dei social media
- Crescita esponenziale dei dati prodotti
NOSQL
Introduzione – un po' di storia
Anni 2000
Nascita del Web 2.0
- Diminuisce notevolmente il costo dei sistemi di memorizzazione
- Diffusione dell'e-Commerce
- Diffusione dei social media
- Crescita esponenziale dei dati prodotti
Necessità di scalare con il crescere dei dati
NOSQL
Introduzione – un po' di storia
A questo punto la scalabilità dei sistemi RDBMS distribuiti non è più sufficiente per
stare al passo con la velocità desiderata di produzione e consumo dei dati. Nascono
quindi i database NOSQL per rispondere alle esigenze che con i RDBMS non potevano
affrontare ovvero la necessità di una alta scalabilità orizzontale invece che una
Scalabilità verticale
scalabilità verticale (limitata) tipica dei RDBMS.
Scalabilità orizzontale
NOSQL
Introduzione – un po' di storia
NOSQL
RDBMS
VS
NoSQL
RDBMS vs NOSQL
Fine delle relazioni ?
Dire che un sistema NoSQL è non relazionale significa che
adottandolo si è costretti a rinunciare alle relazioni fra i dati?
No! Anzi...
NoSQL significa non tanto rinunciare al linguaggio SQL quanto
rinunciare al rigido formalismo matematico, detto algebra relazionale,
che è alla base di tutti i sistemi RDBMS
e quindi
liberarsi dai vincoli che esso impone.
NOSQL
Fine delle relazioni ?
Quali sono questi vincoli ?
Ricordiamo che i sistemi RDBMS richiedono un processo di normalizzazione sui dati
che consente di
“evidenziare le caratteristiche essenziali dei dati
e le relazioni che tra essi intercorrono, eliminando tutte le ridondanze”.
Il risultato è un modello astratto dei dati, detto schema, che definisce univocamente la
struttura e il tipo dei dati e li separa in tabelle.
NOSQL
Fine delle relazioni ?
Due conseguenze fondamentali del processo di normalizzazione sono:
- la necessità di utilizzare dei JOIN per ricostruire le informazioni da elaborare;
operazione costosa sia computazionalmente che temporalmente;
- la rigidità dello schema:
- aggiungere un campo o una relazione rende necessario bloccare l'intero database
fino a che la modifica non è completata;
- solo i dati conformi allo schema possono essere memorizzati;
Il costo relativo di questi vincoli aumenta con l'aumentare delle dimensioni dei dati da
trattare e rende impossibile un'efficace scalabilità orizzontale.
RDBMS vs NOSQL
Fine delle relazioni ?
I sistemi NoSQL non nascono quindi con l'obiettivo di rinunciare alle relazioni tra i dati
ma, al contrario, dal desiderio di avere la massima libertà possibile di modificare ed alterare
nel tempo sia la struttura dei dati che le relazioni che tra essi intercorrono.
Per questo motivo si fondano su:
- una organizzazione/memorizzazione dei dati in formati meno astratti e più vicini
(ed utili) all'applicazione che li dovrà elaborare;
- l'assenza di uno schema rigido che consenta di aggiungere nuovi dati, anche molto
dissimili dai precedenti, e nuove relazioni senza la necessità di modificare la struttura
del database e senza bloccarne l'accesso.
RDBMS vs NOSQL
Acidi vs Basi
Le caratteristiche ed i punti di forza dei sistemi RDBMS vengono spesso sintetizzate
con l'acronimo ACID; per evidenziare il diverso approccio ai dati dei sistemi NoSQL
alcuni dei loro punti di forza sono stati sintetizzati nell'acronimo BASE.
A tomicity
B asically
C onsistency
A vailable,
I solation
S oft State,
D urability
E ventually Consistent
RDBMS vs NOSQL
CAP Theorem
Perché abbandonare le proprietà ACID ?
Il CAP Theorem sostanzialmente dimostra che
è impossibile garantire le proprietà ACID
in un sistema distribuito e scalabile orizzontalmente .
Quindi il superamento delle proprietà ACID non è un vezzo ma un passaggio
obbligatorio qualora si voglia costruire un sistema distribuito.
RDBMS vs NOSQL
CAP Theorem
Nel 2000 Brewer teorizzo il seguente teorema noto CAP theorem:
un sistema distribuito può fornire contemporaneamente solo due fra le seguenti
garanzie:
●
Consistency (Consistenza): tutti i nodi vedono gli stessi dati nello stesso
momento;
●
Availability (Disponibilità): il sistema risponde a tutte le richieste;
●
Partition tolerance (Tolleranza al Partizionamento): il sistema continua ad
operare anche se alcune sue parti rimangono isolate dalle altre in modo
arbitrario (ovvero se il grafo che rappresenta il sistema è disconnesso).
RDBMS vs NOSQL
CAP Theorem
CA
Consistency
L'intersezione
tra queste tre
regioni è nulla.
CP
Partition
Tollerance
Availability
AP
RDBMS vs NOSQL
CAP Theorem
Perché è impossibile garantire le proprietà ACID su un sistema distribuito ?
Un limite fondamentale di cui ci si dimentica spesso quando si progetta un software,
anche nel caso di web services, è che la velocità della luce è costante.
Questo fatto apparentemente irrilevante implica che
un segnale che deve attraversare l'Atlantico impiega circa 30 ms.
cosa che rende estremamente complesso realizzare un sistema distribuito, altamente
scalabile, fortemente interattivo e dunque indipendente dalla latenza.
RDBMS vs NOSQL
CAP Theorem
Vediamo attraverso alcuni diagrammi il significato del CAP Theorem.
Nel diagramma sono illustrati due nodi N1 e N2 che condividono un dato V ( ognuno ne ha una
copia) il cui valore è V0.
Su ciascun nodo gira un algoritmo (A e B) che
possiamo considerare sicuro, privo di errori,
prevedibile ed affidabile.
A scrive un nuovo valore su V
B legge il valore di V.
RDBMS vs NOSQL
CAP Theorem
In un mondo ideale la rete sarebbe sempre affidabile e il trasferimento di informazioni
istantaneo...
1
2
3
RDBMS vs NOSQL
CAP Theorem
In un mondo reale la rete non sempre é affidabile e il trasferimento di informazioni non
è istantaneo...
N1
1
N1
A
V1
Vo
N1
A
2
A
V1
3
V1
M
N2
N2
B
1
N2
B
Vo
2
B
Vo
3
V0
V0
RDBMS vs NOSQL
CAP Theorem
In altri termini, il CAP Theorem ci dice che
se vogliamo un sistema che sia
- highly available, ovvero in grado di lavorare con latenza minima;
- costituito da centinaia o migliaia di nodi
- e che ciascun nodo sia tollerante alle interruzioni di rete ( messaggi persi, non
recapitati, fallimento di processi, guasti hardware)
allora dobbiamo accettare il fatto che ci saranno alcuni momenti in cui
- un nodo sarà convinto che il valore di V sia V0
- ed un altro nodo sarà convinto che il valore di V sia V1
RDBMS vs NOSQL
CAP Theorem
CA
Come ovviare ai limiti imposti dal CAP Theorem ?
Ci sono 3 possibilità:
Consistency
Availability
1 : CA - rinunciare alla Partitition Tolerance
ovvero forzare tutti i dati richiesti da una
transazione in un'unica macchina
CP
Partition
Tollerance
o quantomeno datacenter,
con ovvi limiti alla scalabilità.
Questo è tipicamente quello che si fa con i tradizionali RDBMS.
AP
RDBMS vs NOSQL
CAP Theorem
CA
Le altre due opzioni, con diverse sfumature,
sono quelle adottate dai sistemi NoSQL
2 : CP – rinunciare a qualcosa in termini di
Availabilty
per
garantire
consistenza
Consistency
Availability
e
robustezza al partizionamento;
3 : AP – rinunciare a qualcosa in termini di
Consistenza
per
garantire
robustezza al partizionamento;
disponibilità
e
CP
Partition
Tollerance
AP
RDBMS vs NOSQL
ACID Properties
Atomicità: la transazione è indivisibile nella sua esecuzione e la sua esecuzione deve essere o totale o
nulla, non sono ammesse esecuzioni parziali;
Consistenza: quando inizia una transazione il database si trova in uno stato consistente e quando la
transazione termina il database deve essere in un altro stato consistente, ovvero non deve violare eventuali
vincoli di integrità, quindi non devono verificarsi contraddizioni (inconsistenza) tra i dati archiviati nel DB;
Isolamento: ogni transazione deve essere eseguita in modo isolato e indipendente dalle altre transazioni,
l'eventuale fallimento di una transazione non deve interferire con le altre transazioni in esecuzione;
Durabilità: detta anche persistenza, si riferisce al fatto che una volta che una transazione abbia richiesto
un commit, i cambiamenti apportati non dovranno essere più persi.
RDBMS vs NOSQL
ACID Properties
Le proprietà ACID garantiscono l’integrità e la consistenza del dato, ma per consentire
la transazionalità impongono forti limiti alle performance ed alla scalabilità orizzontale.
I produttori di sistemi RDBMS per ridurre i limiti alla scalabilità dei loro sistemi hanno
sviluppato un protocollo denominato Two Phase Commit (2PC) che prevede che:
- il coordinatore delle transazioni richiede a tutti i db coinvolti dalla transazione di
effettuare un pre-commit per verificare la fattibilità dell'operazione;
- ogni database effettua il pre-commit e invia una risposta al coordinatore;
- se tutte le risposte sono positive il coordinatore conferma la transazione e le
modifiche vengono apportate, altrimenti viene invocato un rollback.
RDBMS vs NOSQL
BASE properties
Giocoforza si è dovuto adottare una versione “rilassata” delle proprietà ACID che
favoriscono la replicazione dei dati per aumentare la scalabilità orizzontale e la
disponibilità del dato a scapito della consistenza (in senso ACID).
Queste proprietà sono sintetizzate dall'acronimo :
BASE = Basically Available, Soft state, Eventual consistency.
NOSQL
Differenze RDBMS e NOSQL
Basically Available. L'approccio NoSQL predilige la disponibilità del dato anche in presenza di
molteplici errori. Viene ottenuto utilizzando un approccio altamente distribuito replicando i dati su un gran
numero di sistemi di memorizzazione. E' la consistenza nel senso del teorema CAP.
Soft state. Si abbandona la consistenza nel senso delle proprietà ACID. Lo stato del sistema può quindi
variare nel tempo, teoricamente anche senza input specifici.
Eventual consistency. Significa che in un qualche istante futuro i dati arriveranno in uno stato
consistente (nel senso ACID). Non ci sono garanzie, ovviamente, su quando ed in quanto tempo questo
avverrà. Questo perché:
• il sistema deve risponde subito alle richieste dei client;
• le modifiche ai dati si propagano in maniera asincrona fra i vari nodi.
NOSQL
Tipologie di sistemi
NoSQL
NOSQL
Tipologie di NOSQL
Proprio perché i database NOSQL sono incentrati sui dati esistono, ne esistono di
diverse tipologie ed esistono diverse varianti all'interno della stessa tipologia.
Le quattro tipologie principali di database NOSQL sono:
NOSQL
Key-value stores
I Key-Value stores puntano sugli aspetti di “Availability” e “Partition Tolerance” del
teorema CAP e prendono origine dall'articolo di Amazon dove descriveva il suo
database Dynamo.
Lo scopo di Amazon era quello di avere un database altamente scalabile dove si
potesse accedere ai dati in modo affidabile il più velocemente possibile in quanto i
database relazionali non scalavano alla velocità necessaria. Lo sviluppo di Dynamo fu
iniziato nel 2007.
Esempi di database:
Amazon Dynamo, Voldemort (Linkedin), MemcacheDB, Riak,
Redis, BerkleyDB ...
NOSQL
Key-value stores
I database Key-Value stores sono la più “semplice” tipologia di database NOSQL.
Ad ogni chiave è associato un blob binario “oscuro” che può contenere qualsiasi
tipologia di dato (stringa di testo, documento, immagine, video, ecc...).
KEY
VALUE
Key 1
Key 2
Key 3
Stringa
Key 4
Blob datatype
NOSQL
Key-value stores
KEY
Key 1
Key 2
Key 3
Key 4
VALUE
Il vantaggio è che si ha una struttura altamente scalabile con
una API di interrogazione del database molto semplice:
●
Aggiungi una coppia key/value
●
Recuperare un blob data la sua chiave
●
Cancellazione di una chiave
Le differenze principali rispetto al modello relazionale:
●
Una query restituisce un solo elemento
●
I value possono contenere qualsiasi tipo di dato
Lo svantaggio è che non c'è nessun modo di eseguire query basate sul contenuto del
valore in quanto i blob sono “oscuri”.
NOSQL
Document stores
Sono orientati alla conservazione di documenti; quindi a differenza di quanto accade con
i Key-Value stores, il contenuto non è una black-box ma è accessibile ed indicizzabile
I Document stores si basano su un modello proposto già negli negli anni '80 da Lotus
Notes; non a caso uno dei fondatori di CouchDB, Damien Katz, ha dichiarato
“Couch is Lotus Notes built from the ground up for the web”.
Esempi di DB: MongoDB, CouchDB, Couchbase...
NOSQL
Document stores
Lo scopo di questa tipologia di database è quella di archiviare in modo efficiente sia i
documenti che il loro contenuto, perciò consentono di creare indici secondari in modo
da poter recuperare i documenti anche in base al loro contenuto, metadati o
combinazioni di essi.
Inoltre, gli indici sono quasi sempre realizzati simili a quelle tipiche dei sistemi RDBMS
che consentono ricerche
●
per uguaglianza;
●
per intervallo;
●
indici su più attributi;
●
riferimenti ad altri documenti.
NOSQL
Document stores
Esiste una limitata analogia fra i Document DB e gli RDBMS che si può riassumere in
questa tabella e che può aiutare a comprenderne meglio l'organizzazione
Relazionale
Document stores
Tabella
Collection
Riga
Document
Colonna
Coppia Key/Value
Join
Non presente*
I JOIN non sono presenti, ma i riferimenti verso altri documenti possono essere visti
come una sorta JOIN.
Va rimarcato che i documenti non hanno uno schema e che quindi possono essere
costituiti da coppie key/value, coppie key/array, o anche documenti annidati.
NOSQL
Document stores
Il formato in cui vengono memorizzati i documenti è generalmente standard, anche se
più raramente in alcuni casi vengono memorizzati file di documenti veri e propri (es.
PDF, DOC …).
Il formato più utilizzato è il JSON, gli altri formati utilizzati sono XML, YAML e BSON.
Questo è dovuto principalmente anche alla forte integrazione che questi database
hanno con Javascript. Inoltre, la possibilità di ottenere modelli di dati complessi senza
rinunciare alle performance, li ha resi molto diffusi per siti web e di e-commerce, e
gestione documentale.
NOSQL
Column family stores
I database Column family si ispirano all'articolo di Google dove descriveva il suo
database Bigtable.
Bigtable è “un sistema di memorizzazione distribuito per la gestione di dati strutturati
progettato per scalare su grandissime dimensioni: petabyte di dati distribuiti su migliaia
di server”.
Dal 2006, Bigtable, è usato da Google in oltre 60 progetti.
Esempi di DB: Bigtable, Hbase, Hypertable, Cassandra ...
NOSQL
Column family stores
Column family store indica che il database è organizzato per colonne invece che per
righe come nei RDBMS.
+
-
+
-
semplicità nell'aggiungere
o modificare un record
durante la lettura dei record
si potrebbero leggere dati
non necessari
vengono letti solamente i dati
di interesse
la scrittura di una tupla richiede
accessi multipli
Ottimale per repository di grandi dimensioni che sono read-intensive
NOSQL
Column family stores
Un Column Family Store può esser visto come una mappa
●
ordinata;
●
multi-dimensionale;
●
persistente;
●
indicizzata per row key, column key e timestamp;
Poiché ad ogni dato è associato un timestamp è possibile avere anche un versioning dei dati.
Inoltre ogni riga può avere un numero differente di colonne, cosa che di fatto rende questo
database una matrice multidimensionale sparsa.
I column family si dividono in:
●
Standard column family
●
Super column family
NOSQL
Column family: Standard Column Family
La row key (la chiave più “esterna”)
identifica l'aggregato, che a sua volta
mappa una o più famiglie di colonne
dove possono essere presenti diversi
valori
associati
column key.
ad
una
diversa
NOSQL
Column family: Super Column Family
Un’estensione
dello
Standard
Column Family è rappresentato dal
Super Column Family.
Questo
aggiunge
modello
un
semplicemente
ulteriore
livello
di
indicizzazione fra la row key e
l’insieme delle colonne, la cosiddetta
super column.
Questa chiave viene utilizzata per raggruppare attributi correlati fra di loro, appartenenti
allo stesso aggregato. Questa organizzazione ha vari vantaggi fra cui:
●
dati più ordinati ed utilizzabili dalle applicazioni;
●
sharding più efficiente.
NOSQL
Column family stores
Altri vantaggi dei Column family database sono:
●
I valori in una singola colonna sono memorizzati in maniera contigua e conservati in
specifici column datafile;
●
I dati all'interno di ciascun column datafile sono dello stesso tipo, questo li rende ideali
per la compressione;
●
La memorizzazione per colonna permette di migliorare le performance delle query in
quanto permette l'accesso diretto alle colonne;
●
Alte performance nelle query di aggregazione (es. COUNT, SUM, AVG, MIN, MAX).
NOSQL
Graph
Quest'ultima tipologia di database NOSQL, a differenza delle precedenti, è relazionale,
in quanto il suo focus è memorizzare i dati e le relazioni fra loro esistenti.
I Graph stores sono ispirati dalla teoria dei grafi.
E' la tipologia di database ideale per la gestione di social network e simili, nonché
sistemi intelligenti che facciano uso di clustering e generazione di regole.
Esempi di DB: Neo4j, OrientDB, AllegroGraph, InfiniteGraph...
NOSQL
Graph
Nome: “Roberto”
Età: 36
Email: [email protected]
Nome: “Francesca”
Età: 34
Marca: “Opel”
Modello: “Corsa”
I nodi del grafo sono i dati ed hanno coppie key/value.
NOSQL
Graph
Nome: “Roberto”
Età: 36
Email: [email protected]
Ama
Nome: “Francesca”
Età: 34
Vive con
Ama
Possiede
dal: 2008
Guida
Marca: “Opel”
Modello: “Corsa”
Le relazioni sono gli edge del grafo, collegano i nodi, hanno una etichetta e possono
avere coppie key/value. Inoltre, la semantica delle relazioni dipende dall'applicazione e
quindi possono essere sia riflessive (es. Vive con) che no (es. Ama).
NOSQL
Un punto di vista applicativo
Confronto
NoSQL
NOSQL
Un punto di vista applicativo
Una chiave di lettura molto interessante sui sistemi NoSQL è quella proposta da Martin
Fowler nel suo libro NoSQL Distilled, che si fonda sull'utilizzo tipico che viene fatto di
queste tecnologie.
La prima domanda che si pone è:
esiste davvero una linea di demarcazione netta
tra Key-Value Stores e Document Stores ?
NOSQL
Un punto di vista applicativo
Metadata
customer ID: 4156
La risposta è NO.
●
La maggior parte dei KV store consente di aggiungere dei metadati indicizzabili con cui
recuperare velocemente i values associati (rendendoli simili ai document store)
●
La maggior parte dei Document, associano automaticamente un ID al document che
tipicamente viene recuperato per intero (ciò che si fa con i KV)
NOSQL
Un punto di vista applicativo
Anche i Column-Store, pur avendo una struttura più complicata, possono essere visti come degli
Aggregate Store.
Ogni Column-Family raggruppa un insieme di colonne “simili” che possono essere recuperate
attraverso un'unica operazione.
Ad esempio in una
Colum-Family si possono
racchiudere i dettagli
dell'ordine
Ed in un'altra i dettagli dei
singoli Item associati
all'ordine .
NOSQL
Aggregate Storage
Possiamo considerare i sistemi NoSQL come degli Aggregate Storage, cioè dei sistemi
che ci consentono di memorizzare entità complesse (così come le abbiamo in RAM nella
nostra applicazione) con un'unica operazione, come se fossero un'unica entità indivisibile.
Consideriamo il caso banale di un ordine con più elementi al suo interno.
In RAM avremo almeno
●
●
un oggetto Order e
un oggetto Item per ogni elemento.
Tuttavia, anche discorsivamente, quando pensiamo di salvare l'ordine o
leggere i dettagli dell'ordine, pensiamo all'ordine come un'unica entità
complessa che vogliamo leggere e scrivere con un'unica operazione.
NOSQL
Aggregate Storage
I sistemi RDBMS
ci costringono a
spargere i dati su
tante tabelle distinte
e separare un' operazione
in tante sotto-operazioni..
...che poi raggrupperemo
in una transazione
per poter avere atomicità e
consistenza.
NOSQL
Aggregate Storage
I sistemi NoSQL invece ci consentono di memorizzare
l'intera struttura complessa come un unico Aggregato,
così come lo abbiamo in RAM.
●
KV
: Aggregato == Value
●
Document
: Aggregato == Documento
●
Col-Store
: Aggregato == RowID + ColFamily
NOSQL
Aggregate Storage - Drawbacks
Esistono tuttavia delle controindicazioni nell'uso dei sistemi NoSQL.
Supponiamo di voler fare un po' di analisi ed elaborare delle statistiche sulle vendite:
Product
Curr. Sales
Prev. Sales
PR001
123
142
PR002
234
208
PR003
331
300
...
….
….
…
….
...
NOSQL
Aggregate Storage - Drawbacks
Ciò che stiamo facendo in questo caso è cambiare il cuore dell'Aggregato.
In questo caso l'aggregazione non sarà più incentrata sugli ordini, ma sui prodotti perché ci
interessano gli andamenti delle vendite in diversi periodi dell'anno.
Questo con i sistemi RDBMS risulta facile,
basta cambiare leggermente la QUERY e le
regole di raggruppamento.
Con i sistemi NoSQL è invece molto più
scomodo
ottenere
questo
risultato
e
tipicamente si effettuano dei Job MapReduce
che analizzano l'intera base dati.
L'uso dei sistemi NoSQL risulta dunque vantaggioso quando l'accesso ai dati
avviene per lo più in forma aggregata. Se invece si ha necessità di cambiare
spesso forma di aggregazione un sistema RDBMS può essere più adatto.
NOSQL
Aggregate Storage
Fanno storia a se i Graph DB che invece hanno un approccio diametralmente opposto e
presentano una parcellizzazione delle informazioni ancor più estrema di quella dei sistemi
RDBMS.
NOSQL
Confronto
RDBMS vs NoSQL
RDBMS vs NoSQL
MySQL vs Mongo
Effettuare un confronto approfondito tra sistemi così diversi è molto complesso.
Per dare un'idea dell'impatto delle caratteristiche ACID su un sistema distribuito e dei
potenziali vantaggi di sistemi basati sul modello BASE, riportiamo i risultati di un
confronto tra
- MySQL installato in modalità distribuita e
- MongoDB
eseguiti nel dipartimento di High Performance Computing della Università di Edimburgo
nel 2013.
RDBMS vs NoSQL
MySQL Schema
RDBMS vs NoSQL
Mongo Schema
RDBMS vs NoSQL
Test 1 : Simple Query
Test 1:
Il primo test riguarda l'esecuzione di una query semplice che coinvolge una sola tabella.
SELECT * FROM Users WHERE username = 'username'
RDBMS vs NoSQL
Test 1 : Simple Query
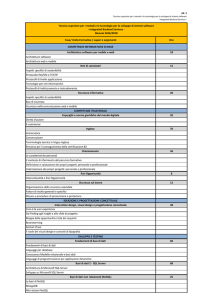
Tempo di esecuzione delle queries in diverse configurazioni:
RDBMS vs NoSQL
Test 1 : Simple Query
Numero di queries al secondo
RDBMS vs NoSQL
Test 2 : Query with SELF JOIN
Test 2:
Il secondo test è più complesso e richiede l'utilizzo di un SELF JOIN
SELECT 'Favourites.song_id' AS fSID,
'Favourites.userid' AS fUID
FROM
Favourites AS b INNER JOIN Favourites AS a
ON b.user_id = a.user_id
WHERE a.song_id = 123456 AND a.user_id != 987654
RDBMS vs NoSQL
Test 2 : Query with SELF JOIN
Tempo di esecuzione delle queries in diverse configurazioni:
RDBMS vs NoSQL
Test 2 : Query with SELF JOIN
Numero di queries al secondo
RDBMS vs NoSQL
Test 3 : Complex Query
Test 3:
Il terzo test è ancora più complesso e richiede l'utilizzo di
- una nested query e
- 2 INNER JOIN
SELECT 'Songs.release_id' AS sID, 'Releases.id' AS rID
FROM
Songs INNER JOIN Releases
ON Songs.release_id = Releases.id
WHERE artist_id IN
(SELECT 'Genres.artist_id' AS gAID
FROM Genres AS g INNER JOIN Artists AS a
ON g.artist_id = a.id
WHERE a.name = 'artist_name' )
RDBMS vs NoSQL
Test 3 : Complex Query
E' evidente come, anche in un setup piuttosto semplice come quello del test,
crescere della complessità della query i tempi di esecuzione siano nettamente diversi.
al
RDBMS vs NoSQL
Test 4 : Variazione delle dimensioni del DB
In questo caso si può notare come il tempo di esecuzione della query nel caso di
MySQL aumenti con il crescere delle dimensioni del DB
RDBMS vs NoSQL
Test comparativo
Il test precedente ha messo in evidenza l'impatto negativo sulle performance dovuto ai
JOIN ed agli accessi su più tabelle.
Impatto percepibile anche in un sistema semplice con pochi dati e poche macchine
tutte posizionate all'interno di uno stesso datacenter con connessioni ad alte
prestazioni.
Vediamo ora un secondo test che coinvolge anche HBase e Cassandra, effettuato su
macchine virtuali fornite dagli Amazon Web Services, con un carico di lavoro più
consistente ma con letture scritture su tabella singola, quindi senza l'impatto negativo
dovuto ai JOIN.
RDBMS vs NoSQL
Numeri del test
Client : 1 Nodo
- RAM : 7.5 GB
- CPU : 4 Core
Server : 4 Nodi
- RAM : 15 GB
- CPU : 8 Core
Dati:
- 100 Milioni di record
- 10 campi per record
- 100 thread attivi contemporaneamente (client-side)
RDBMS vs NoSQL
Bulk Load
Hbase è risultato il più veloce
con 40K op/sec.
Al
secondo
posto
troviamo
Cassandra con 15K op/sec.
RDBMS vs NoSQL
Workload A ( 50% read, 50% update)
RDBMS vs NoSQL
Workload A ( 50% read, 50% update)
RDBMS vs NoSQL
Workload B ( 95% read, 5% update)
RDBMS vs NoSQL
Workload B ( 95% read, 5% update)
RDBMS vs NoSQL
Workload C : read-only
N.B: Ricordiamo che si tratta di accessi su singola tabella a record con pochi campi.
RDBMS vs NoSQL
Workload D ( 90% insert, 10% read)
NOSQL
RDBMS vs NoSQL
Come Scegliere ?
NoSQL
Quando e quale scegliere?
Non esiste una riposta univoca a questa domanda.
La scelta tra un sistema RDBMS ed una o più delle tipologie di sistemi NoSQL è
strettamente legata al problema specifico che si deve affrontare.
Nelle prossime slide cercheremo di fornire alcune linee guida che potranno essere
d'aiuto nella scelta tra i vari sistemi.
Innanzitutto è necessario porsi alcune domande...
Come Scegliere ?
Che vincoli ci impone il nostro problema ?
Vediamo alcune domande di carattere generale che dovremmo porci prima di decidere:
Vincoli legati al modello :
- Quante entità ci occorrono per modellare il problema ?
- Quante relazioni abbiamo tra le diverse entità ? Quanto sono “fitte” ?
- Che probabilità c'è che lo schema possa cambiare ? Con quale frequenza ?
Vincoli legati all'accesso ai dati:
- Quanto è stringente il vincolo di consistenza ? Dev'essere assoluta ? E' ammissibile un ritardo di qualche
ms o di qualche secondo nella propagazione degli aggiornamenti ?
- L'accesso ai dati avverrà su tutti i campi di un record o solo su alcuni di essi ?
- Le elaborazioni richiederanno l'accesso a più tabelle ? O saranno concentrate solo su alcune colonne
(es. data, prezzo, disponibilità...) ?
Come Scegliere ?
Macro categorie di applicazioni
Per orientarci meglio possiamo definire tre macro categorie che ci aiutino a capire i pro
e i contro delle diverse soluzioni:
- Applicazioni prettamente Transazionali: caratterizzate da forti vincoli di consistenza e
certezza dell'informazione;
- Applicazioni prettamente Computazionali, caratterizzate dalla necessità di eseguire
elaborazioni anche complesse sui dati;
- Applicazioni prettamente Interattive e Web Oriented: caratterizzate dalla presenza
di un numero elevato di utenti e di dover loro garantire tempi di risposta molto brevi;
Come Scegliere ?
Applicazioni Transazionali
Ad esempio “gestione di un punto vendita” o “gestione risorse umane”.
Sono caratterizzate da :
●
obbligatorietà della consistenza ed integrità dei dati;
●
modesto livello di concorrenza (gestibile da una singola macchina)
Vincoli sullo schema:
●
tipicamente associate a problemi con dati fortemente strutturati
●
relazioni chiare e strette tra le varie entità
●
relazioni utilizzate di frequente
●
schema stabile e con scarse probabilità di cambiamento
Come Scegliere ?
Applicazioni Transazionali
Vincoli sull'accesso ai dati:
●
consistenza (ogni lettura DEVE garantire il valore più aggiornato del dato)
●
Row-Oriented (tipicamente viene letto l'intero record)
●
frequente accesso a più tabelle (JOIN)
●
necessità dell'uso delle transazioni (proprietà ACID)
Come Scegliere ?
Applicazioni Transazionali
Pro NoSQL:
●
Column Oriented: possono semplificare la gestione dello schema, che può facilmente
variare nel tempo con l'aggiunta di colonne;
●
Document : possono aiutare nella definizione di viste
Contro NoSQL:
●
non forniscono supporto alle relazioni (ad eccezione dei Graph DB);
●
non forniscono supporto alle transazioni (no ACID);
●
non forniscono supporto per JOIN o viste sui dati (tranne alcuni Document attraerso il
modello MapReduce, che però non è facile da usare);
Decisione:
Questo è il regno dei sistemi RDBMS e difficilmente si possono avere dei vantaggi con sistemi
NoSQL.
Come Scegliere ?
Applicazioni Computazionali
Sono applicazioni tipicamente orientate all'elaborazione dei dati, ad esempio per
●
la produzione di report di vendite;
●
generazione di statistiche sull'utilizzo di un dato servizio
●
individuazione di trend o altre funzionalità di analytics
Tipicamente :
●
operano su un sottoinsieme dei campi del record;
●
fanno un uso piuttosto limitato delle relazioni tra tabelle;
Vincoli sullo schema:
●
tipicamente sono associate a schemi strutturati che variano poco nel tempo
●
possono richiedere l'integrazione tra basi di dati diverse e dunque con schemi
differenti;
Come Scegliere ?
Applicazioni Computazionali
Accesso ai dati:
●
tipicamente utilizzano un sottoinsieme dei campi di un record;
●
Column-Oriented → le elaborazioni da eseguire sui dati richiedono operazioni tra
valori della stessa colonna associati a record diversi (es. colonna prezzo, colonna
vendite ed acquisti, date...)
●
accessi multi-tabella piuttosto rari;
●
consistenza dei dati non stringente → è richiesto il valore più recente del dato ma è
ammissibile un lieve ritardo nel suo ottenimento in quanto tipicamente le
elaborazioni non vengono effettuate in real-time;
Come Scegliere ?
Applicazioni Computazionali
Pro NoSQL:
●
Column Oriented: consentono la definizione di uno schema rigoroso e contemporaneamente
facilitano l'uso di schemi variabili nel tempo ;
●
Document / Key-Value : possono essere utilizzati ma non forniscono alcun supporto nella
verifica dello correttezza dello schema;
●
Possono garantire un notevole incremento di prestazioni durante l'accesso parziale ai record;
●
Possono eseguire molte operazioni la dove sono memorizzati i dati senza necessità di
spostarli attraverso la rete; con un sostanziale incremento delle prestazioni;
Contro NoSQL:
●
non forniscono supporto alle relazioni (ad eccezione dei Graph DB);
●
l'assenza di regole e relazioni può generare temporanee inconsistenze tra i dati;
Come Scegliere ?
Applicazioni Computazionali
Decisione:
Entrambe le categorie di sistemi possono essere utilizzate per questo tipo di applicazioni.
L'elemento decisivo è la dimensione dei dati da elaborare.
In linea del tutto generale ed orientativa si può supporre che:
●
al di sotto del milione di record l'overhead dei sistemi NoSQL non ne giustifichi l'adozione;
●
tra il milione e 100 milioni di record, entrambe i sistemi possano funzionare egregiamente;
●
al di sopra dei 100 milioni di record i vantaggi dei sistemi NoSQL prevarranno su tutti gli oneri
di adozione e gestione aggiuntivi
Come Scegliere ?
Applicazioni Interattive e Web-Oriented
Sono web-applications o applicazioni mobile caratterizzate da:
●
elevatissimo numero di utenti;
●
vasta distribuzione geografica degli utilizzatori (potenzialmente mondiale);
●
grande quantità di dati da conservare ed elaborare;
●
disponibilità degli utenti ad attendere un “tempo ragionevole” per ottenere una
risposta;
●
uno schema che può variare nel tempo per assecondare l'evoluzione
dell'applicazione in funzione delle esigenze degli utenti;
●
possibilità di aggiungere e modificare nel tempo le relazioni tra entità;
Come Scegliere ?
Applicazioni Interattive e Web-Oriented
Vincoli sullo schema
●
possibilità di definire uno schema strutturato;
●
possibilità di modificare lo schema nel tempo senza impattare sui record esistenti;
●
le relazioni potrebbero non esser stringenti e dunque gestite a livello applicativo;
Accesso ai dati
●
spesso è richiesto un accesso parziale ai campi di un record;
●
grande velocità nell'esecuzione di operazioni (tipicamente CRUD);
●
è tollerabile una temporanea (breve) inconsistenza delle informazioni
Come Scegliere ?
Applicazioni Interattive e Web-Oriented
Pro NoSQL:
●
Column Oriented: consentono la definizione di uno schema rigoroso e contemporaneamente
facilitano l'uso di schemi variabili nel tempo ;
●
Document / Key-Value : possono essere utilizzati ma non forniscono alcun supporto nella
verifica dello correttezza dello schema (possono essere di grande aiuto nella gestione di
schemi molto variabili);
●
Possono garantire un notevole incremento di prestazioni durante l'accesso parziale ai record;
●
Possono eseguire molte operazioni la dove sono memorizzati i dati senza necessità di
spostarli attraverso la rete; con un sostanziale incremento delle prestazioni;
●
Basandosi sulle proprietà BASE e non ACID garantiscono un'elevatissima scalabilità delle
operazioni CRUD;
Contro NoSQL:
●
nessuno
Come Scegliere ?
Applicazioni Interattive e Web-Oriented
Decisione:
Decisamente questo è il regno dei sistemi NoSQL.
La scelta tra le diverse tipologie è legata alle esigenze operative del problema da risolvere.
Ad esempio:
●
per applicazioni SaaS che devono consentire uno schema flessibile in grado di accettare
campi definiti dall'utente (es. CRM o ERP di tipo Enterprise) i document store potrebbero
essere la scelta ottimale;
●
per applicazioni social o in cui lo schema cambia velocemente ma sotto il controllo dello
sviluppatore, la scelta ottimale è probabilmente quella dei Column-Store;
●
per applicazioni social o comunque caratterizzate da un'estrema variabilità delle relazioni tra
entità un Graph DB potrebbe essere la scelta ottimale.
Conclusioni
Come scegliere?
La tendenza che si sta consolidando è quella di una soluzione orientata alla
Polyglot Persistence
ovvero, si fa una decomposizione funzionale del problema e :
●
le funzionalità transazionali sono realizzate tramite un RDBMS;
●
le funzionalità computazionali, in funzione del volume di dati, sono realizzate tramite
RDBMS o Column-Store (eventualmente document o key-value);
●
le funzionalità web-scale che devono gestire una variabilità dello schema controllata
dall'utente possono esser realizzate tramite Document-Store;
●
le funzionalità web-scale che devono gestire una variabilità dello schema controllata dallo
sviluppatore possono esser realizzate tramite Column-Store;
●
le funzionalità web-scale che prevedono la gestione dinamica di relazioni fra le entità
possono esser gestite tramite Graph-DB;